Recently, directly detecting 3D objects from 3D point clouds has received increasing attention. To extract object representation from an irregular point cloud, existing methods usually take a point grouping step to assign the points to an object candidate so that a PointNet-like network could be used to derive object features from the grouped points. However, the inaccurate point assignments caused by the hand-crafted grouping scheme decrease the performance of 3D object detection. In this paper, we present a simple yet effective method for directly detecting 3D objects from the 3D point cloud. Instead of grouping local points to each object candidate, our method computes the feature of an object from all the points in the point cloud with the help of an attention mechanism in the Transformers, where the contribution of each point is automatically learned in the network training. With an improved attention stacking scheme, our method fuses object features in different stages and generates more accurate object detection results. With few bells and whistles, the proposed method achieves state-of-the-art 3D object detection performance on two widely used benchmarks, ScanNet V2 and SUN RGB-D.
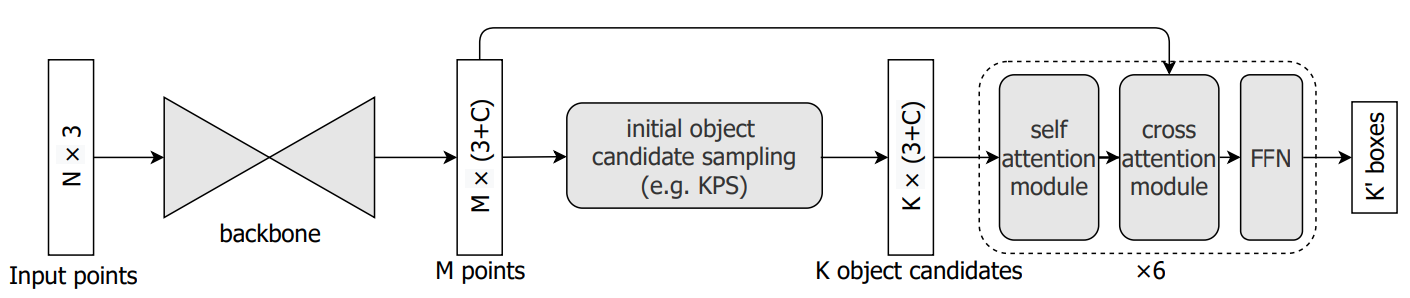
We implement Group-Free-3D and provide the result and checkpoints on ScanNet datasets.
| Method | Backbone | Lr schd | Mem (GB) | Inf time (fps) | AP@0.25 | AP@0.5 | Download |
|---|---|---|---|---|---|---|---|
| L6, O256 | PointNet++ | 3x | 6.7 | 66.32 (65.67*) | 47.82 (47.74*) | model | log | |
| L12, O256 | PointNet++ | 3x | 9.4 | 66.57 (66.22*) | 48.21 (48.95*) | model | log | |
| L12, O256 | PointNet++w2x | 3x | 13.3 | 68.20 (67.30*) | 51.02 (50.44*) | model | log | |
| L12, O512 | PointNet++w2x | 3x | 18.8 | 68.22 (68.20*) | 52.61 (51.31*) | model | log |
Notes:
- We report the best results (AP@0.50) on validation set during each training. * means the evaluation method in the paper: we train each setting 5 times and test each training trial 5 times, then the average performance of these 25 trials is reported to account for algorithm randomness.
- We use 4 GPUs for training by default as the original code.
@article{liu2021,
title={Group-Free 3D Object Detection via Transformers},
author={Liu, Ze and Zhang, Zheng and Cao, Yue and Hu, Han and Tong, Xin},
journal={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}