Postgres fast load #44
Comments
|
Hi Sunil, First of all, thank you for using
Could you please elaborate on how you loaded the data with
That does sound indeed like a good enhancement, thank you very much! I have created ER #45 for that.
Can you elaborate on this one, please? Given that
There are several reasons why |
I have tried not batch size or other parameters. Below the csv2db load -f 'C:\ReddReports\pgsql\bin\demo_bike_share_tripdata_temp.csv' -v -t demo_bikeshare_tripdata_temp -o postgres -u -p -m -n 5432 -d -s |
I meant the default for
You are absolutely right. I am looking at staging data (load step in an ELT process) only so no issues dropping or truncating the target table. This could be an option with Hopefully this makes sense :) |
|
Regarding bulk loads, you could tap into the bulk load capability of the database clients. For PostgreSQL it is "COPY" or "copy" command. Happy to give you what the script looks like. Similarly for MySQL and SQL Server. This will make |
|
Thanks for your response, @sunilred!
You may want to try to bump up the batch size, the default is 10,000 rows. Depending on how long your rows are, you may want to increase that accordingly.
That makes sense now, thank you!
That makes sense to me, thank you, but that could also be easily accommodated by a shell script around |
|
I tried the batch size and it does not seem to make a huge difference. As per the below screenshot, I uploaded 50,000 rows to PostgreSQL (on AWS). I ran the csv2db with the default 10K batch size and then again with a 25K batch size. As shown below, the time taken was more or less the same.
I tried 50K batch size and the performance was the same. Finally I used Postgre COPY command and it took about 5 seconds. Am I missing something? |

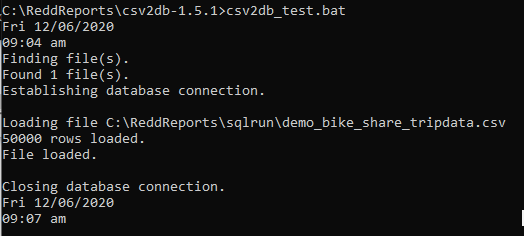

|
Thanks a lot, @sunilred! No, that all looks correct. Given that the time doesn't improve with different batch sizes, it seems that you already have big enough batches of 10k rows to avoid network round-trip related issues, which is good. I just did some experiments with a local Postgres database myself. For example, loading 50k rows (8MB of uncompressed file size) into the database takes me less than 8 seconds (with the default batch size of 10k): Comparatively, loading 720k rows (117MB of uncompressed file size) into the database takes me about 1 minute 52 seconds: However, that compared with the With the And the 720k rows within less than 3(!) seconds: It seems that the Postgres driver could handle batch loads much more efficiently than it currently does, or perhaps there is a different, better and faster way of performing data loads. I will reach out to the |
|
Hi. I think it is probably the fact that I am using AWS Aurora PostgreSQL. The may be some inefficiencies in that. I am going to run similar tests against SQL Server and see how that performs. |
|
I guess/believe that the COMMIT operation is handled differently in a copy and in a bulk insert. |
Hi Gerald,
First off this is a great tool. Thanks very much.
My use case is to upload CSV files into AWS Postgres DB for data analytics (Windows environment). Your tool works great however it is a bit slow when dealing with my data volumes. I get files with a million rows that need to be uploaded to Postgre on a daily basis.
For testing, I loaded 20000 rows and it took 2-3 mins, while using pgsql COPY load it took 2 seconds.
I was wondering if there is a way to tap into using pgsql for a faster upload?
I am assuming your process, in order to be generic, uses INSERT statements behind the scene?
Also I was wondering if we can add a few more options to "csv2db" that I think others users may find useful - and hopefully you see value in it.
Additional useful options for "csv2db load"
Additional useful option for "csv2db generate"
3. Create table in the target database (the default fornow i.e. to print the CREATE TABLE script)
Let me know what you think.
Thanks
Sunil
The text was updated successfully, but these errors were encountered: