切片是Go语言中常用的数据类型,相比数组它更加灵活。不同于数组是值类型,而切片是引用类型。虽然两者作为函数参数传递时候都是值传递(pass by value),但是切片传递的包含数据指针(可以细分为pass by pointer),所以如果切片使用不当,会产生意想不到的副作用。
切片初始化方式可以分为三种:
-
使用make函数创建切片
make函数语法格式为:make([]T, length, capacity),capacity可以省略,默认等于length
-
使用字面量创建切片
-
从数组或者切片派生(reslice)出新切片
Go支持从字符串、数组、指向数组的指针、切片类型变量再reslice一个新切片。
reslice操作语法可以是[]T[low : high],也可以是[]T[low : high : max]。low,high,max都可以省略,low默认值是0,high默认值cap([]T),max默认值cap([]T)。low,hight,max取值范围是
0 <= low <= high <= max <= cap([]T),其中high-low是新切片的长度,max-low是新切片的容量。对于[]T[low : high],其包含的元素是[]T中下标low开始,到high结束(不含high所在位置的,相当于左闭右开[low, high))的元素,元素个数是high - low个,容量是cap([]T) - low。
func main() {
slice1 := make([]int, 0)
slice2 := make([]int, 1, 3)
slice3 := []int{}
slice4 := []int{1: 2, 3}
arr := []int{1, 2, 3}
slice5 := arr[1:2]
slice6 := arr[1:2:2]
slice7 := arr[1:]
slice8 := arr[:1]
slice9 := arr[3:]
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice1", slice1, len(slice1), cap(slice1))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice2", slice2, len(slice2), cap(slice2))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice3", slice3, len(slice3), cap(slice3))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice4", slice4, len(slice4), cap(slice4))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice5", slice5, len(slice5), cap(slice5))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice6", slice6, len(slice6), cap(slice6))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice7", slice7, len(slice7), cap(slice7))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice8", slice8, len(slice8), cap(slice8))
fmt.Printf("%s = %v,\t len = %d, cap = %d\n", "slice9", slice9, len(slice9), cap(slice9))
}上面代码输出一下内容:
slice1 = [], len = 0, cap = 0
slice2 = [0], len = 1, cap = 3
slice3 = [], len = 0, cap = 0
slice4 = [0 2 3], len = 3, cap = 3
slice5 = [2], len = 1, cap = 2
slice6 = [2], len = 1, cap = 1
slice7 = [2 3], len = 2, cap = 2
slice8 = [1], len = 1, cap = 3
slice9 = [], len = 0, cap = 0.. hint:: 当我们使用arr[3]访问切片元素时候会报 ``index out of range [3] with length`` 错误,而使用arr[3:]来初始化slice9却是OK的。这是Go语言故意为之的。具体原因可以参见 `Why slice not painc <https://github.com/golang/go/issues/42069>`_ 这个issue。
接下来我们来看看切片底层数据结构。
Go语言中切片的底层数据结构是runtime.slice(runtime/slice.go),其中包含了指向数据数组的指针,切片长度以及切片容量:
type slice struct {
array unsafe.Pointer // 底层数据数组的指针
len int // 切片长度
cap int // 切片容量
}.. hint:: 切片底层数据结构也可以说成是reflect.SliceHeader,两者没有冲突。
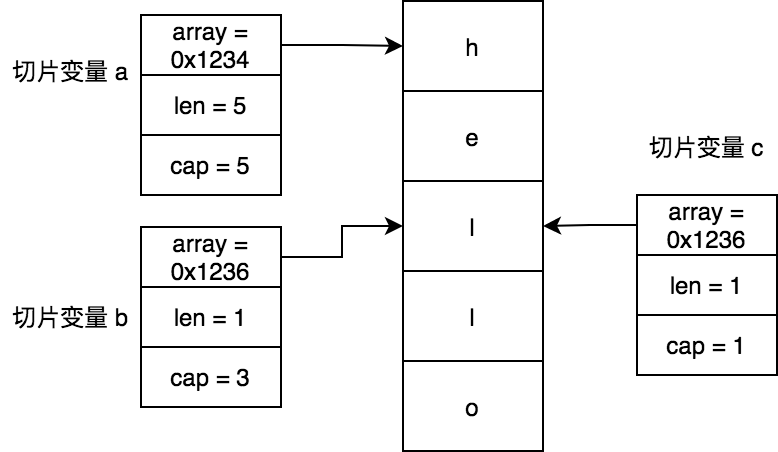
我们来看看下面切片如何共用同一个底层数组的:
func main() {
a := []byte{'h', 'e', 'l', 'l', 'o'}
b := a[2:3]
c := a[2:3:3]
fmt.Println(string(a), string(b), string(c)) // 输出 hello l l
}
在前面字符串章节,我们使用了GDB工具验证了字符串的数据结构,这一次我们使用另外一种方式验证切片的数据结构:
func main() {
type sliceHeader struct {
array unsafe.Pointer // 底层数据数组的指针
len int // 切片长度
cap int // 切片容量
}
a := []byte{'h', 'e', 'l', 'l', 'o'}
b := a[2:3]
c := a[2:3:3]
ptrA := (*sliceHeader)(unsafe.Pointer(&a))
ptrB := (*sliceHeader)(unsafe.Pointer(&b))
ptrC := (*sliceHeader)(unsafe.Pointer(&c))
fmt.Printf("切片%s: 底层数组地址=0x%x, 长度=%d, 容量=%d\n", "a", ptrA.array, ptrA.len, ptrA.cap)
fmt.Printf("切片%s: 底层数组地址=0x%x, 长度=%d, 容量=%d\n", "b", ptrB.array, ptrB.len, ptrB.cap)
fmt.Printf("切片%s: 底层数组地址=0x%x, 长度=%d, 容量=%d\n", "c", ptrC.array, ptrC.len, ptrC.cap)
}上面代码输出以下内容,完全符合预期:
切片a: 底层数组地址=0xc00009400b, 长度=5, 容量=5
切片b: 底层数组地址=0xc00009400d, 长度=1, 容量=3
切片c: 底层数组地址=0xc00009400d, 长度=1, 容量=1
由于切片底层结构的特殊性,当我们使用切片的时候需要特别留心,防止产生副作用(side effect)。
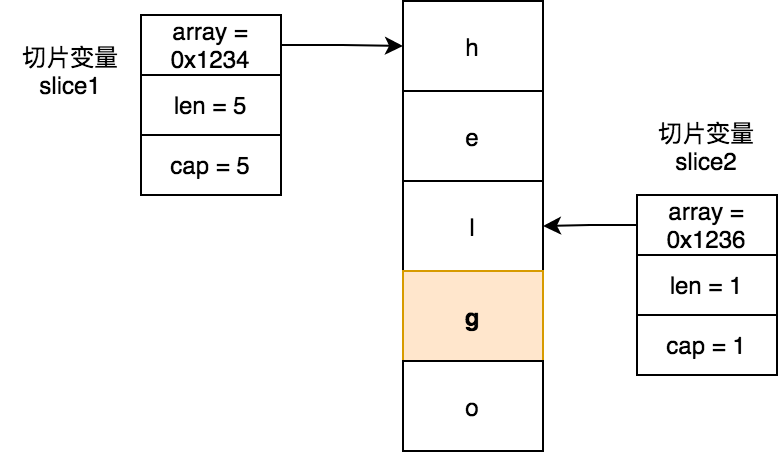
func main() {
slice1 := []byte{'h', 'e', 'l', 'l', 'o'}
slice2 := slice1[2:3]
slice2 = append(slice2, 'g')
fmt.Println(string(slice2)) // lg
fmt.Println(string(slice1)) // 输出helge,slice1的值也变了。
}上面代码本意是将切片slice2追加g字符,却产生副作用,即也修改了slice1的值:
解决这个问题有两种方式:一种是reslice时候指定max边界,第二种使用copy函数拷贝出一个副本。
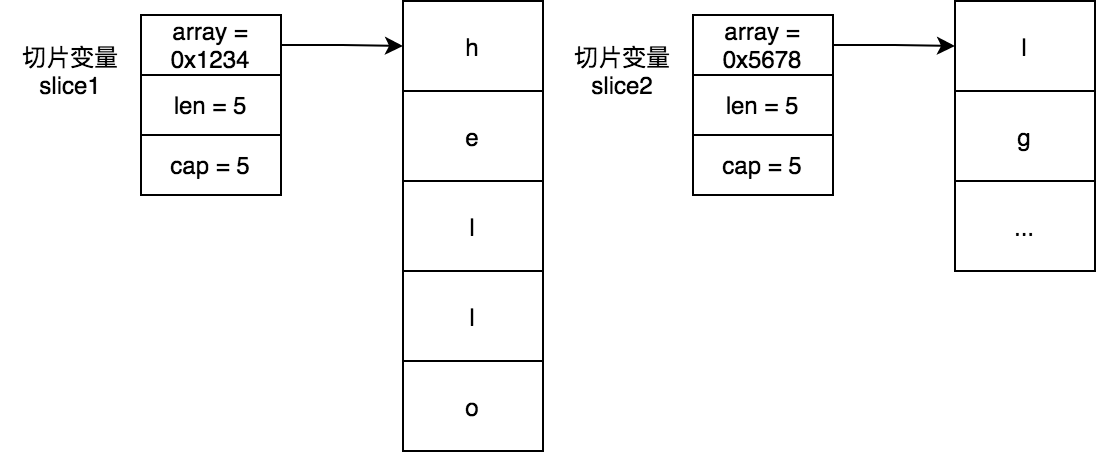
reslice时候指定max边界
func main() {
slice1 := []byte{'h', 'e', 'l', 'l', 'o'}
slice2 := slice1[2:3:3]
slice2 = append(slice2, 'g') // 此时slice2容量扩大到8
fmt.Println(string(slice2)) // 输出lg
fmt.Println(string(slice1)) // 输出hello
}slice2 := slice1[2:3:3]方式reslice之后slice2的长度和容量一样,若对slice2再进行append操作其一定会进行扩容,此后slice2和slice1之间就没有任何关系了。
使用copy函数拷贝出一个副本
func main() {
slice1 := []byte{'h', 'e', 'l', 'l', 'o'}
slice2 := make([]byte, 1)
copy(slice2, slice1[2:3])
slice2 = append(slice2, 'g')
fmt.Println(string(slice2)) // 输出lg
fmt.Println(string(slice1)) // 输出hello
}type User struct {
Likes int
}
func main() {
users := make([]User, 1)
pFirstUser := &users[0]
pFirstUser.Likes++
fmt.Println("所有用户:")
for i := range users {
fmt.Printf("User: %d Likes: %d\n\n", i, users[i].Likes)
}
users = append(users, User{}) // 添加一个新用户到集合中
pFirstUser.Likes++ // 第一个用户的Likes次数加一
fmt.Println("所有用户:")
for i := range users {
fmt.Printf("User: %d Likes: %d\n", i, users[i].Likes)
}
}指向上面代码输出以下内容:
所有用户:
User: 0 Likes: 1
所有用户:
User: 0 Likes: 1
User: 1 Likes: 0代码本意是通过User类型指针变量pUsers进行第一个用户Likes更新操作,没想到切片进行append之后,发生了副作用:pUsers指向切片已经与切片变量users不一样了。

黄金法则1:在边界处拷贝切片,这里面的边界指的是函数接受切片参数或返回切片的时候。
黄金法则2:永远不要使用一个变量来引用切片数据。
当对切片进行append操作时候,若切片容量不够时候,会进行扩容处理。当切片进行扩容时候会先调用runtime.growslice函数,该函数返回一个新的slice底层结构体,该结构体array字段指向新的底层数组地址,cap字段是新切片的容量,len字段是旧切片的长度,旧切片的内容会拷贝到新切片中,最后再把要追加的数据复制到新切片中,并更新切片len长度。
// et是slice元素类型
// old是旧的slice
// cap是新slice最低要求容量大小。是旧的slice的长度加上append函数中追加的元素的个数
// 比如s := []int{1, 2, 3};s = append(s, 4, 5); 此时growslice中的cap参数值为5
func growslice(et *_type, old slice, cap int) slice {
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap { // 最小cap要求大于旧slice的cap两倍大小
newcap = cap
} else {
if old.len < 1024 { // 当旧slice的len小于1024, 扩容一倍
newcap = doublecap
} else { // 否则每次扩容25%
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
case et.size == 1: // 元素大小
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem) // 调整newcap大小
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 { // 切片元素中没有指针类型数据,不用考虑写屏障问题
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)
}
}
// 涉及到slice扩容都会有内存移动操作
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}从上面代码中可以总结出切片扩容的策略是:
- 若切片容量小于1024,会扩容一倍
- 若切片容量大于等于1024,会扩容1/4大小,由于考虑内存对齐,最终实际扩容大小可能会大于1/4
从上面代码中可以看到,切片进行扩容时一定会进行内存拷贝,这是成本较大操作。所以切片一大优化点就是在使用之前尽量指定好切片所需容量,避免出现扩容情况。
零拷贝(zero-copy)指的是CPU不需要先将数据从某处内存复制到另一个特定区域。当应用程序读取文件,需要从磁盘中加载内核区域,然后将内核区域内容复制到应用内存区域,这就涉及到内存拷贝。若采用mmap技术可以文件映射到特定内存中,只需加载一次,应用程序和内核都可以共享内存中文件数据,这就实现了zero-copy。或者当应用程序需要发送文件给远程时候,可以采用sendfile技术实现零拷贝,若未实现零拷贝,则需要进行四次拷贝过程:
磁盘---(DMA copy)--> 系统内核 --> 应用程序区域 --> 系统内核(socket) ---(DMA copy)---> 网卡
package main
func byteArrayToString(b []byte) string {
return string(b)
}
func stringToByteArray(s string) []byte {
return []byte(s)
}
func main() {
}我们来看下上面代码中的底层实现:go tool compile -N -l -S main.go
.. code-block::
:emphasize-lines: 15,25
"".byteArrayToString STEXT size=117 args=0x28 locals=0x38
0x0000 00000 (main.go:3) TEXT "".byteArrayToString(SB), ABIInternal, $56-40
0x0000 00000 (main.go:3) MOVQ (TLS), CX
0x0009 00009 (main.go:3) CMPQ SP, 16(CX)
0x000d 00013 (main.go:3) PCDATA $0, $-2
0x000d 00013 (main.go:3) JLS 110
0x000f 00015 (main.go:3) PCDATA $0, $-1
0x000f 00015 (main.go:3) SUBQ $56, SP
0x0013 00019 (main.go:3) MOVQ BP, 48(SP)
0x0018 00024 (main.go:3) LEAQ 48(SP), BP
...
0x003c 00060 (main.go:4) MOVQ AX, 8(SP)
0x0041 00065 (main.go:4) MOVQ CX, 16(SP)
0x0046 00070 (main.go:4) MOVQ DX, 24(SP)
0x004b 00075 (main.go:4) CALL runtime.slicebytetostring(SB)
0x0050 00080 (main.go:4) MOVQ 40(SP), AX
....
"".stringToByteArray STEXT size=144 args=0x28 locals=0x50
0x0000 00000 (main.go:7) TEXT "".stringToByteArray(SB), ABIInternal, $80-40
0x0000 00000 (main.go:7) MOVQ (TLS), CX
0x0009 00009 (main.go:7) CMPQ SP, 16(CX)
...
0x0040 00064 (main.go:8) MOVQ AX, 8(SP)
0x0045 00069 (main.go:8) MOVQ CX, 16(SP)
0x004a 00074 (main.go:8) CALL runtime.stringtoslicebyte(SB)
0x004f 00079 (main.go:8) MOVQ 32(SP), AX
0x0054 00084 (main.go:8) MOVQ 40(SP), CX
....
从上面汇编代码可以看到string([]byte)底层调用的是runtime.slicebytetostring,[]byte(string)底层调用的是runtime.stringtoslicebyte。查看这两个底层函数实现可以看到两者都是先创建一段内存空间,然后使用memmove函数拷贝内存,将数据拷贝到新内存空间。这也就是说[]byte(string) 和 string([]byte)进行转换时候需要内存拷贝。
那么能不能实现不需要内存拷贝的字符串和字节切片的转换呢?答案是可以的。根据前面字符串章节和本章节,我们可以看到字符串和字节切片底层结构很相似,它们相同部分都有指向底层数据指针和记录底层数据长度len字段,字节切片额外多了一个字段cap,记录底层数据的容量,只要转换时候让它们共享底层数据就能实现zero-copy。
type StringHeader struct {
Data uintptr
Len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}我们来看下网上比较常见zero-copy的实现方式,它是有bug的:
func string2bytes(s string) []byte {
return *(*[]byte)(unsafe.Pointer(&s))
}
func bytes2string(b []byte) string{
return *(*string)(unsafe.Pointer(&b))
}我们来测试一下:
func main() {
a := "hello"
b := string2bytes(a)
fmt.Println(string(b), len(b), cap(b))
}上面代码输出以下内容:
hello 5 824634122328
可以看到字节切片的容量明显有问题的。我们来分析下。上面两个函数借助非安全指针类型强制转换类型实现的。对于字节切片转换字符串使用这种方式是可以的,字节切片多余的cap字段会自动溢出掉;而反过来由于字符串没有记录容量字段,那么将其强制转换成字节切片时候,字节切片的cap字段是未知的,这有可能导致非常严重问题。所以将字符串转换成字节切片时候需要保证字节切片的cap设置正确。
正确的字符串转字节切片实现如下:
func StringToBytes(s string) (b []byte) {
sh := *(*reflect.StringHeader)(unsafe.Pointer(&s))
bh := (*reflect.SliceHeader)(unsafe.Pointer(&b))
bh.Data, bh.Len, bh.Cap = sh.Data, sh.Len, sh.Len
return b
}或者
func StringToBytes(s string) []byte {
return *(*[]byte)(unsafe.Pointer(
&struct {
string
Cap int
}{s, len(s)},
))
}