- 给定一个无序数组,对数组进行排序
- 如果数组长度小于2,不用进行排序
- 从数组中选择一个基准值
- 将数组分成两个子数组,小于基准值的数组和大于基准值的数组
- 递归,分别对两个子数组进行快速排序。
def quick_sort(arr):
if len(arr)<2:
return arr
else:
# 选择基准值
refer_value = arr[0]
# 根据基准值,把数组分成两个子数组
left = [i for i in arr[1:] if i<=refer_value]
right = [i for i in arr[1:] if i>refer_value]
# 递归,对两个子数组进行快速排序
return quick_sort(left) + [refer_value] + quick_sort(right)
arr = [4,5,6,3,2,5,8,1]
quick_sort(arr)
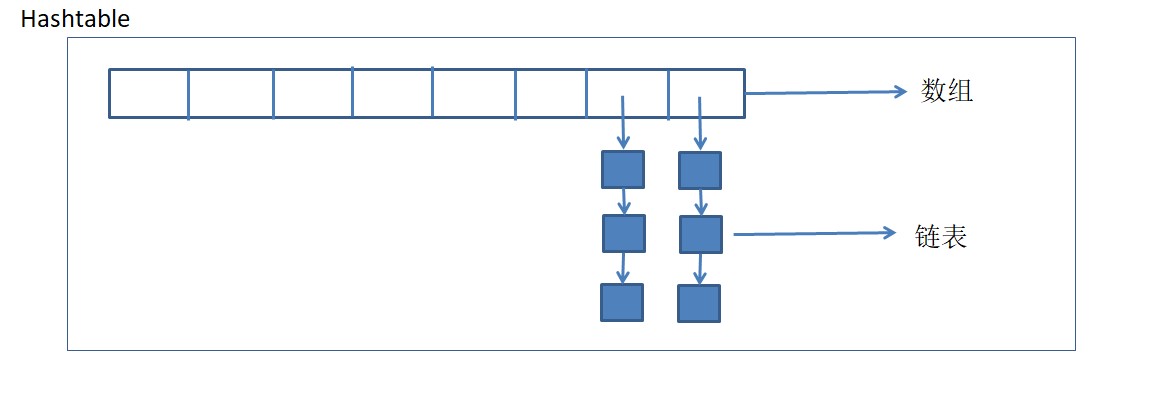
散列表也叫哈希表,是根据key的值直接进行访问的数据结构(key-value).它通过把key的值映射到内存中一个位置,以加快查找的速度。这个映射函数叫做散列函数(哈希函数),存放记录的数组叫做散列表(哈希表)。哈希表的查询速度,插入与删除速度都很快。
Python中的dict{}就是Hashtable的实现。
图是由节点和边组成,用于模拟不同节点间的关系

用Python实现图,表示节点间的关系
graph = {}
graph['A'] = ['B','D']
graph['D'] = ['B','C']
graph['B'] = []
graph['C'] = ['B']
- 给定一个图,和源节点,从图中搜索出目标节点。
- 创建一个队列,用于存储与源节点一度关系的节点。
- 从队列(先进先出)中取出一个元素,判断该元素是否是目标节点。
- 如果是,返回节点;如果不是,将该节点的所有一度关系节点加入队列。
- 重复第三步。
- 如果队列为空,说明没有找到目标节点。
from collections import deque
graph = {}
graph['A'] = ['B','D']
graph['D'] = ['B','daacheng']
graph['B'] = []
graph['daacheng'] = ['B']
def search(graph):
# 1、定义一个双端队列
search_queue = deque()
# 2、队列存储于源节点一度关系的节点
search_queue += graph['A']
searched = [] # 定义列表用于存放已经查询过的节点
# 如果队列为空,说明没有找到目标节点
while search_queue:
# 3.从队列中取出一个判断是不是目标节点
item = search_queue.popleft()
if item not in searched:
if item == 'daacheng':
print('找到daacheng了')
return True
else:
# 4、如果不是,把该节点所有一度关系节点加入队列
search_queue += graph[item]
searched.append(item)
return False
search(graph)