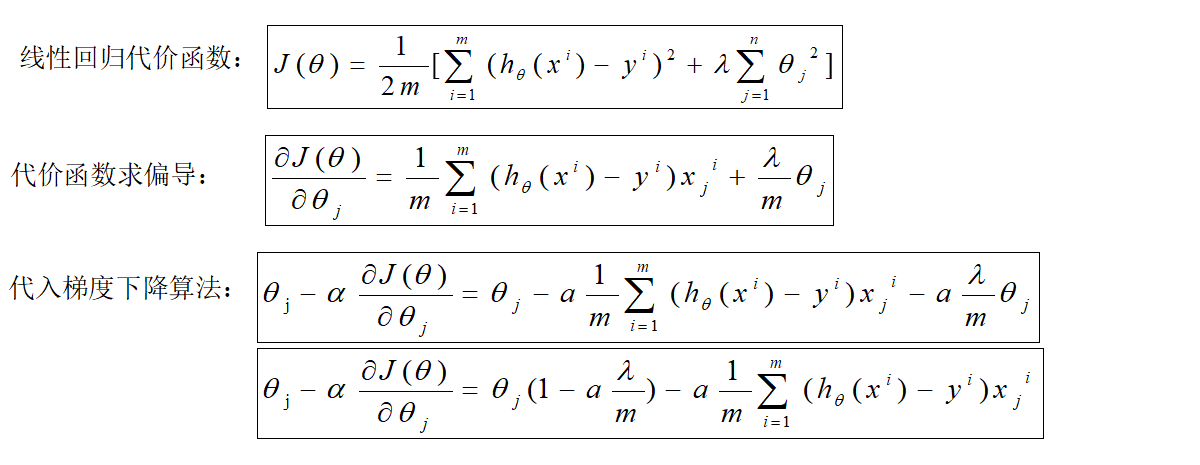机器学习通过大量的训练集数据进行训练,然后得到的模型,可以分为三种情况,欠拟合模型,过拟合模型,最合适的模型。
- 欠拟合:模型不能很好的适应训练集数据,误差太大,,只能适用训练集中很小一部分数据。
- 过拟合:模型过于强调适用每一组原始数据,误差基本上可以为0,但是如果用该模型去预测新的数据,表现却并不是很好。也就是说过拟合模型只能很好的适应训练集数据,而不能很好的适用于测试数据。
如何处理过拟合问题?
- 丢弃一些不能帮助我们正确预测的特征,通过手工选择保留哪些特征,或是通过算法自动选择特征。
- 正则化。保留所有的特征,但是降低特征的权重大小,也就是特征对应的参数Θ。特征权重变小了,特征对结果的影响也就随之变小了。