Replies: 2 comments 2 replies
-
|
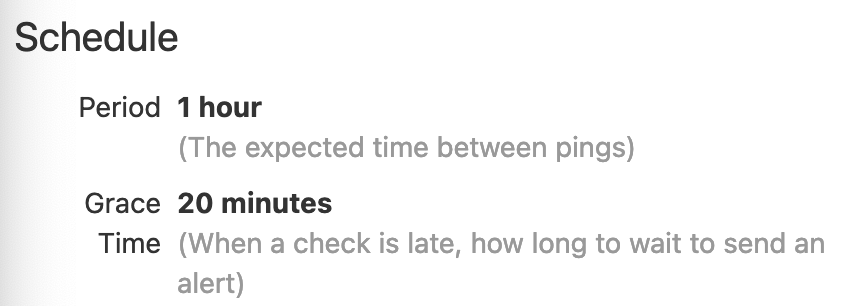
I'm just starting to play with assets, but I like having a different color to quickly identify ones that are really out of date, as it makes it possible to see the health of the whole graph in a glance. Is the problem really that things are stale and yellow too often? Does the timing that the reconciliation runs from need to be separate from the timing that shows when an asset is late? Right now I'm working on some run status sensors that ping Healthchecks.io or Sentry.io cron monitoring. Most of those cron monitoring types of services have both a schedule for when runs are expected to run, and then a delay or grace period before it time to panic.
By having the clear delineation between 'it should start before this', and 'ok now something has gone wrong' assets could progress from fresh > stale > late with colors changing accordingly. I wonder if this is also a place to look at asset expectations ( #9543 ) again? In addition to then data expectations that could drive failures, timing (and other) expectations could drive failures, then users could be in control of if/when an asset would change colors (and maybe even the level of failure and language?). The policy to drive the declarative pipeline could then be separate from the expectations that signal failures. @asset(
expectations=[data_isnt_horrible, LatencyExpectation(period_minutes=60, grace_minutes=20)], # things that can signal when things go wrong
declarative_policies=[LatencyPolicy(maximum_lag_minutes=60)], # things needed to decoratively drive the pipelines
)
def an_asset_that_should_happen_hourly_but_maybe_not_worth_panicking_about_until_its_20_min_late():
...It may seem like duplication of code (60 min is specified twice), but it disentangles what you want Dagster to do from when do you care about it telling you that things have gone wrong. (I'm thinking there could also be declarative policies like This could also allow signaling on assets that aren't driven by the declarative policies and are instead driven by external state to signal when they end up late too. Expectations could also have different levels (and messages) that would allow fine grained control by the user to define exactly how bad of an issue it is, and display on the graph (and possibly trigger sensors) accordingly. @asset(
expectations=[
data_isnt_horrible, # true/false default to danger level
LatencyExpectation(period_minutes=60, level="info", message="Slightly delayed"), # immediately change the color and message after 60 min
LatencyExpectation(period_minutes=60, grace_minutes=20, level="warning", message="Start worrying"), # Now things may actually not be good
LatencyExpectation(period_minutes=60, grace_minutes=40, message="Beg for forgiveness"), # Level not specified, so danger
]
)
def levels_of_trouble():
...Also worth linking to asset SLA monitoring as related #9455 |
Beta Was this translation helpful? Give feedback.
-
It's one of those things where: alerts are really useful if you care about them, but if you don't care about them and you can't turn them off, they're really annoying. |
Beta Was this translation helpful? Give feedback.
-
This is actually something we are going to post another proposal on soon. |
Beta Was this translation helpful? Give feedback.
-
|
We've run into an issue that's peripherally related to this and it was suggested that we describe it here. Right now partitioned assets seem to assume that their upstream dependencies are also partitioned. There are tools for changing the nature of the partitioning, e.g going from hourly to daily or daily to monthly partitions, where a group of partitions is combined in the next step, but there doesn't seem to be a way to have a partitioned asset depend on another asset upstream which is not partitioned -- each partition of the partitioned asset detects that its upstream dependency is stale and, then they all kick off processes to generate their own individual copies of the identical upstream asset. Our use case looks like this:
We had thought that we'd be able to have a partitioned asset that depended on a simple unpartitioned asset, and some raw input data (one CSV file for every combination for state and year), with the partitioned assets generating a bunch of state-year.parquet files in a directory that could either be read as a partitioned Parquet dataset, or consolidated into a single Parquet file in a subsequent asset, but that didn't work, and instead we've ended up with the following, which feels significantly more complex: YearPartitions = namedtuple("YearPartitions", ["year", "states"])
@op(
out=DynamicOut(),
required_resource_keys={"dataset_settings"},
)
def get_years_from_settings(context):
"""Return set of years in settings.
These will be used to kick off worker processes to process each year of data in
parallel.
"""
epacems_settings = context.resources.dataset_settings.epacems
for year in epacems_settings.years:
yield DynamicOutput(year, mapping_key=str(year))
@op(
required_resource_keys={"datastore", "dataset_settings"},
config_schema={
"pudl_output_path": Field(
EnvVar(
env_var="PUDL_OUTPUT",
),
description="Path of directory to store the database in.",
default_value=None,
),
},
)
def process_single_year(
context,
year,
epacamd_eia: pd.DataFrame,
plants_entity_eia: pd.DataFrame,
) -> YearPartitions:
"""Process a single year of EPA CEMS data.
Args:
context: dagster keyword that provides access to resources and config.
year: Year of data to process.
epacamd_eia: The EPA EIA crosswalk table used for harmonizing the
ORISPL code with EIA.
plants_entity_eia: The EIA Plant entities used for aligning timezones.
"""
ds = context.resources.datastore
epacems_settings = context.resources.dataset_settings.epacems
schema = Resource.from_id("hourly_emissions_epacems").to_pyarrow()
partitioned_path = (
Path(context.op_config["pudl_output_path"]) / "hourly_emissions_epacems"
)
partitioned_path.mkdir(exist_ok=True)
for state in epacems_settings.states:
logger.info(f"Processing EPA CEMS hourly data for {year}-{state}")
df = pudl.extract.epacems.extract(year=year, state=state, ds=ds)
df = pudl.transform.epacems.transform(df, epacamd_eia, plants_entity_eia)
table = pa.Table.from_pandas(df, schema=schema, preserve_index=False)
# Write to a directory of partitioned parquet files
with pq.ParquetWriter(
where=partitioned_path / f"epacems-{year}-{state}.parquet",
schema=schema,
compression="snappy",
version="2.6",
) as partitioned_writer:
partitioned_writer.write_table(table)
return YearPartitions(year, epacems_settings.states)
@op(
config_schema={
"pudl_output_path": Field(
EnvVar(
env_var="PUDL_OUTPUT",
),
description="Path of directory to store the database in.",
default_value=None,
),
},
)
def consolidate_partitions(context, partitions: list[YearPartitions]) -> None:
"""Read partitions into memory and write to a single monolithic output.
Args:
context: dagster keyword that provides access to resources and config.
partitions: Year and state combinations in the output database.
"""
partitioned_path = (
Path(context.op_config["pudl_output_path"]) / "hourly_emissions_epacems"
)
monolithic_path = (
Path(context.op_config["pudl_output_path"]) / "hourly_emissions_epacems.parquet"
)
schema = Resource.from_id("hourly_emissions_epacems").to_pyarrow()
with pq.ParquetWriter(
where=monolithic_path, schema=schema, compression="snappy", version="2.6"
) as monolithic_writer:
for year, states in partitions:
for state in states:
monolithic_writer.write_table(
pq.read_table(
source=partitioned_path / f"epacems-{year}-{state}.parquet",
schema=schema,
)
)
@graph_asset
def hourly_emissions_epacems(
epacamd_eia: pd.DataFrame, plants_entity_eia: pd.DataFrame
) -> None:
"""Extract, transform and load CSVs for EPA CEMS.
This asset creates a dynamic graph of ops to process EPA CEMS data in parallel. It
will create both a partitioned and single monolithic parquet output. For more
information see: https://docs.dagster.io/concepts/ops-jobs-graphs/dynamic-graphs.
"""
years = get_years_from_settings()
partitions = years.map(
lambda year: process_single_year(
year,
epacamd_eia,
plants_entity_eia,
)
)
return consolidate_partitions(partitions.collect()) |
Beta Was this translation helpful? Give feedback.
-
We want to take the experimental tag off of Dagster’s declarative scheduling APIs. Before we do this, we’re reviewing feedback from users and giving the APIs a second look, with the aim of making the product that we’ll commit to maintaining as clear as possible.
Issues we want to address
Lack of correspondence between FreshnessPolicy and “stale” status
A central point of confusion that we’ve observed with the existing system is that, while the word “stale” is the opposite of the word “fresh”,
FreshnessPolicys and the “stale” asset status have only a loose correspondence:FreshnessPolicydetermines whether an asset is “late”, not whether it’s “stale”.FreshnessPolicy, asset reconciliation sensors will often materialize assets that are not stale.Alarmingness of “stale”
The word “stale” has a negative connotation, and assets that are marked as stale are currently colored yellow.
However, in many cases, users are fine with their assets being in a “stale” state. E.g. they have an upstream dataset that’s updated frequently, but don’t need to update their downstream dataset as frequently.
Changes we’re considering
In light of the above, we’re considering a few potential changes to our declarative scheduling ontology.
Replace “stale” with more specific statuses
In the asset graph, instead of labeling an asset as “stale”, they could be labeled as one of:
This could remove the need for users to understand a “stale” concept, as well make it seem less alarming when an asset is in one of these states.
Color assets green instead of yellow
If an asset matches Dagster’s current definition of “stale”, i.e. its code version or upstream data has changed since its latest materialization, it shows up colored yellow in Dagster’s UI.
We could instead color it green, and just include a subtle icon to still make it possible to visually distinguish these assets from other assets when you’re interested.
This would make it seem less alarming when an asset is in this state.
Let us know what you think
If you use these Dagster concepts in your data pipelines or have considered using them, we’d love to hear from you. Any of:
Beta Was this translation helpful? Give feedback.
All reactions