cosmosdb statestore partitioning broken under load #3716
Comments
|
This seems to be a hot partition problem in CosmosDB. I recommend going through this documentation first: https://docs.microsoft.com/en-us/azure/cosmos-db/partitioning-overview#physical-partitions Then, see if your provisioned throughput is enough to sustain this load. The throughput is evenly split across partitions, so there might be a need to overprovision to compensate for a hot partition. Another strategy to minimize the hot partition problem is to play with the partition count. For example, try using a prime number. In your scenario, the next prime number is 53. |
|
ok, thx. We will try the prime approach first. |
|
The fact that you see Key "actors||ACTOR_TYPE" with PartitionKey "a7e27bd7-dc5b-45cc-8760-60d615d3b455" is odd because the first is the old way data was saved while the second is partitioned - which means the Id was supposed to be per reminder partition and not for the global "old" way. |
|
I am looking into this issue. |
|
To clarify, any instance of id "actors||ACTOR_TYPE" should have a partitionKey of "actors||ACTOR_TYPE" as well. |
|
I reproduced a slightly different problem. The issue I found is that the "actors||ACTOR_TYPE" record is created even after the partition is set and none of the partition reminder records were used. I will find the root cause for this, which might lead to fix the issue you are seeing.
|

|
Hi @artursouza , sounds promising. It would be great, to have a fix available soon. |
|
@javageek79 I found the root cause for the behavior I was seeing before. Let me explain my test scenario: test client ---> dapr sidecar A -----> dapr sidecar B ---> actor app The issue I was facing is because sidecar A was being invoked to register a reminder but it was not configured with the Can you confirm if the same is going on in your test scenario? Please, make sure that all sidecar instances have this preview feature enabled: spec:
features:
- name: Actor.TypeMetadata
enabled: true |
|
Hi @artursouza, the feature is enabled in a |
|
Do a |
|
In the one Service that uses the statestore or in all services that have sidecars? |
|
Start with the ones that use state store first. |
|
I've checked, only the ones using statestore ( 1 Service with 2-6 replicas) have config annotation set. |
|
Moving this to 1.6. The action item is to remove the transaction logic and use batch write instead since transaction is not really required. Also, we will change the partitionKey to be simply the key - which is a breaking change and will need to provide a script to migrate the data. |
|
We have changed how reminder partitions are migrated in 1.6 by using batch instead of transaction, migrating only at start up and not on registering/unregistering reminders and blocking multiple migrations in parallel from the same process. This should reduce contention in reminder persistence. In addition, we also fixed a bug that was allowing multiple state stores for actors to be randomly selected instead of failing the sidecar right away. We also found an issue on how first-write-wins was being used when the record was being written for the first time and eTag was still nil, it ended up falling back to last-write-wins. This was also fixed. Please, observe these in 1.6 release to confirm if issues continues. |
|
I am closing this issue as part of the release activities since we made changes to address this problem. Please, reopen if it can still be reproduced after 1.6 release. |
In what area(s)?
/area runtime
What version of Dapr?
1.4.0
Expected Behavior
Having only one db entry called
actors||ACTOR_TYPE||metadataand n buckets, where n is the number of partitions.Actual Behavior
There are multiple parent entries in db with name
actors||ACTOR_TYPEfor eachidvalue, there are n partition-entries, in db containing 200 - 400 reminder entries.valueproperty is set to null.There is also one single
actors||ACTOR_TYPE||metadatawith also n partitions and a properly initializedvaluefield.Table shows parent entries in statestore. For each entry, there are also 50 partiotion-bucket entries as mentioned above.
The screenshots show the time frame in which the loadtest took place.

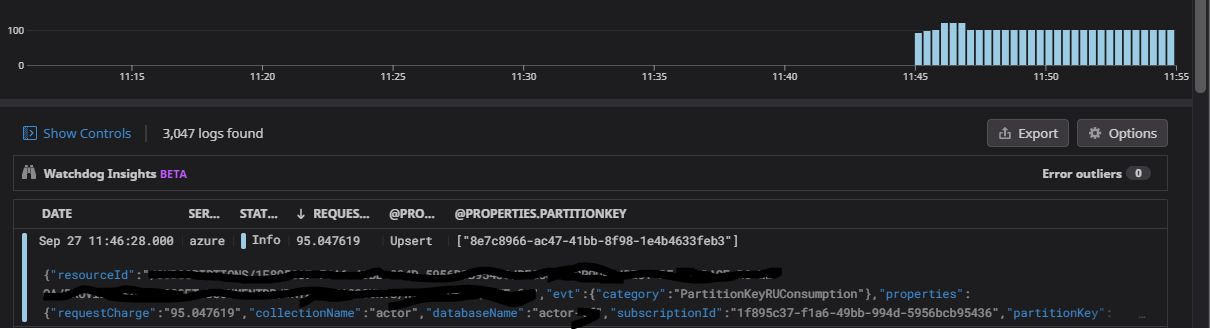


The loadtest started at 11:12:23am and created 2k actors each registering 7 reminders.
2k reminders where supposed to execute at 11:45. After registering those reminders, all actors have been deactivated before 11:45 and recreated with an execution tim at 11:35.
The reregistration started at 11:19:47am
actors||ACTOR_TYPE||metadata->id == 8e7c8966-ac47-41bb-8f98-1e4b4633feb3actors||ACTOR_TYPE->id == 8e7c8966-ac47-41bb-8f98-1e4b4633feb3actors||ACTOR_TYPE->id == a7e27bd7-dc5b-45cc-8760-60d615d3b455actors||ACTOR_TYPE->id == 6c8f8b84-d4bd-405e-a349-57065e644d73Steps to Reproduce the Problem
It was revealed only through our loadtest session. In normal load situation, error situation did not occur.
Release Note
RELEASE NOTE:
The text was updated successfully, but these errors were encountered: