Status and roadmap #1
Comments
|
Can I make a request for an additional section for Administrative topics like packaging, documentation, etc.. What do we need for Dask.dataframe integration? Presumably we're depending on |
|
Yes, passing a file-like object that can be resolved in each worker would do: core.read_col currently takes an open file-object or a string that can be opened within the function. It probably should take a function to create a file object given a path (a parquet metadata file will reference other files with relative paths). |
|
Hi there, Are you guys aware of ongoing PyArrow development? It is also already on conda-forge and also has pandas <-> parquet read/write (through Arrow), although I don't think it supports multi-file yet. |
|
@lomereiter Yes, we're very aware. We've been waiting for comprehensive Parquet read-write functionality from Arrow for a long while. Hopefully fastparquet is just a stopgap measure until PyArrow matures as a comprehensive solution. |
|
Hi, amazing work. Two things I noticed:
|
|
Since @lomereiter mentioned PyArrow, I will just leave this link here: Extreme IO performance with parallel Apache Parquet in Python |
|
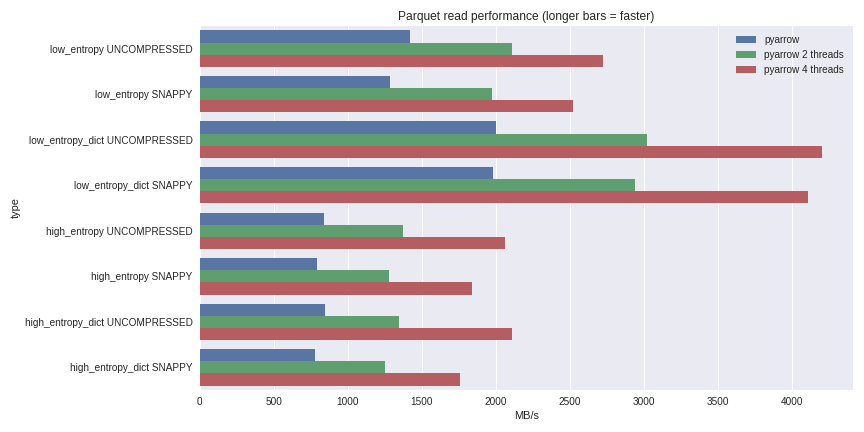
Thanks @frol . That there are multiple projects pushing on parquet for python is a good thing. You should also have linked to the previous posting python-parquet-update (Wes's work, not mine) which shows that fastparquet and arrow have very similar performance in many cases. Note also that fastparquet is designed to run in parallel using dask, allowing distributed data access, and reading from remote stores such as s3. |
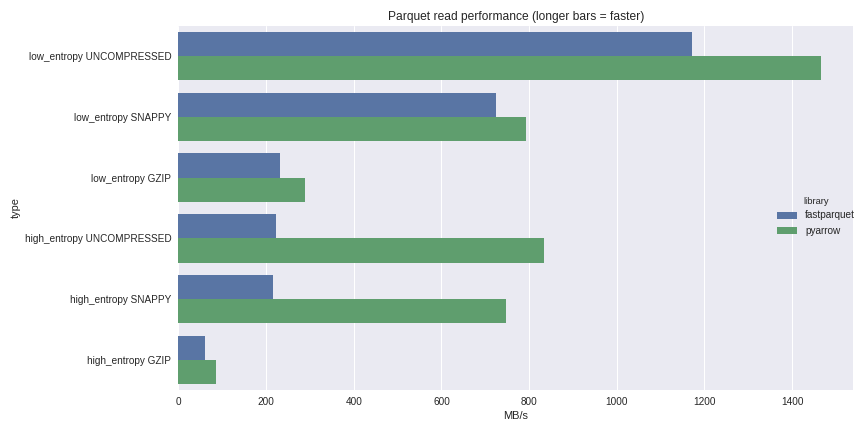
|
@martindurant Thank you! I was actually looking out there for some sorts of benchmarks for fastparquet as I am going to use it with Dask. It would be very helpful to have some info about benchmarks in the documentation as "fast" suffix in the project name implies the focus on speed, but I failed to find any info on this until you pointed me to this article. |
|
There are some raw benchmarks in https://github.com/dask/fastparquet/blob/master/fastparquet/benchmarks/columns.py My colleagues at datashader did some benchmarking on census data at the time when we were focusing on performance. Their numbers include both loading and performing aggregations on the data. |
Features to be implemented.
An asterisk shows the next item(s) on the list.
A question mark shows something that might (almost) work, but isn't tested.
Reading
Writing
Admin
Features not to be attempted
The text was updated successfully, but these errors were encountered: