Policy Gradient logp(a∣s) 的计算 #20
Comments
|
请参考 Policy Gradient 的代码实现: |
|
这里他是手动算的,不是调用现成交叉熵函数。 看到这个代码,我还有一个疑惑是 相关代码片如下: |
|
|
|
谢谢,类似 至于交叉熵函数,我看 Mofan Zhou 使用的是
|
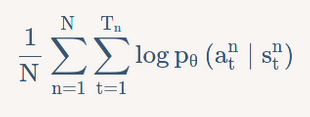
|
关于交叉熵函数,你的理解有两个问题。
# to maximize total reward (log_p * R) is to minimize -(log_p * R), and the tf only have minimize(loss)
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # this is negative log of chosen action
# or in this way:
# neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # reward guided loss |

|
谢谢,没注意到注释的部分,结合注释看理解了一些。关于 这一行中的 是和 第四章 策略梯度 中下图一致
我不太理解的是图中红框部分为什么是那样表示,我的理解是 其中
照我这样想的话,代码应该是 而不是 mofan 的 请问是我的理解哪里有问题么? |

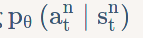
|
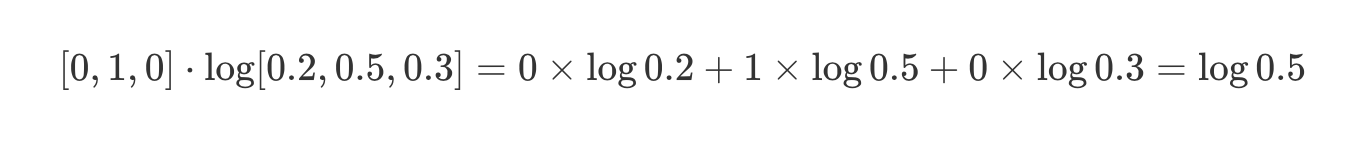
|
现在一想,有点忘了为啥当初没理解 tf.log[0.2, 0.5, 0.3] 计算就是依次对 list 里的每个元素求 log。 exp_list = [tf.math.exp(tf.constant(1.0)), tf.math.exp(tf.constant(2.0))]
print(tf.math.log(exp_list))
# tf.Tensor([1. 2.], shape=(2,), dtype=float32)现在反倒没想明白的是为啥是两个行向量相乘,估计只是一种表现形式吧... |
在 第四章 策略梯度 的 Tips 小节上面一点有如下表述:
对于 “TensorFlow 上调用现成函数”,我看到 SO 上有个 How to choose cross-entropy loss in TensorFlow? 这个问题,你建议 PG 这里怎么选呢?
The text was updated successfully, but these errors were encountered: