/chapter2/chapter2 #36
Comments
|
在全期望公式下面的证明中 令S_t = s后面 从期望形式展开成两个求和操作的那一步能不能再细说一下 |
|
感谢您的反馈,笔记已更新。
|
|
Prediction and Control那边例子Gridworld给的背景是不是有问题,由给的条件一开始理解不了,搜了一下Gridworld,好像条件不大一样 |
感谢您的反馈,背景应该是没有问题的,Gridworld 有很多例子,笔记中列出的只是其中一个例子。 |
|
在 FrozenLake 演示中,Policy-Iteration 在第 5 步收敛,而 Value-iteration 在迭代 1373 收敛。为什么前者比后者快得多?(In the FrozenLake demo , Policy-Iteration converged at step 5 whereas Value-iteration converged at iteration 1373. Why former is much faster than the latter?) |
首先可以肯定的是,一般策略迭代(PI)比值迭代(VI)快得多。个人认为通俗的理解就是,PI每次是在上一次迭代后的策略基础上进行优化的,而VI是一次性的从一开始一直迭代到最优策略,比如在一个大地图上找东西,PI每次学到一点就会运用之前学到的东西也就是以非线性的方式扩大视野再进一步找,而VI则是不断的找最优点(即每次找max的点),每次都是固定的视野范围,需要的迭代次数也更多,也可以参考stackoverflow的回答 |
感谢精彩的回答! |
|
请问为什么价值函数计算那里是从Rt+1开始的呢?即时奖励的话不应该是Rt吗 |
|

|
感谢博主~ |
能对您有所帮助就好,XD |
|
我有一个小小的疑问~ RL问题都需要建模为MDP吗?他们俩是什么关系呀?s,a,r,p是属于MDP而非RL的对吗? |
|
解答见下图:
|

谢谢博主的回答~ |
|
Policy evaluation的例子1表述似乎有一点问题,"现在的奖励函数应该是关于动作以及状态两个变量的一个函数。但我们这里规定,不管你采取什么动作,只要到达状态$$s_1$$,就有 5 的奖励。只要你到达状态 之前笔记中对reward的介绍是$R(s,a)$,只是当前状态s的函数而非$$R(s,s',a)$$即s和$s'$的函数。 而且,按照后面的计算结果和$R$向量的一维性来理解,更符合结果的表述是“只有当前处于状态$s_1$,就有5的奖励,只要当前处于$s_7$,就有10的奖励,与采取任何动作无关”。 不知道我理解的错了没有? |
Hi,感谢您的反馈,回复见下图: |

|
策略迭代 初始化一个 policy 和 value 价值迭代 不需要 policy 的参与,初始化 value policy 生成过程区别 价值迭代过程中没有初始化一个 policy 参与,通过迭代后是最后才生成 博主我有理解正确吗? |
|
|
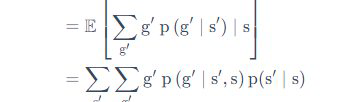
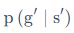
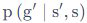
|
感谢博主的教程,我收获很多,只是我还有两个问题: sweep 词语是我在博主推荐可视化网站看到的就是 'Policy Evaluation (one sweep) '按钮 |
|
请问纸质书第62页的价值迭代算法的第(3)步公式是否有误,以我的理解应该在argmax后有一个方括号,且V的下标应该是H,在电子版同一个章节并没有看到对应的内容。如果我的理解有问题,恳请博主指点一下迷津,对这章的数学部分确实有点一知半解的感觉。 |
感谢您的反馈,arg max 后是应该有一个方括号,V 的下标应该是 H+1,具体细节见勘误: |
|
您好,Policy Evaluation(Prediction)中的QA里的迭代公式好像漏了\pi的累加?和前面给的公式不同,不知道是不是有问题? |
@Tricol-Viola 感谢您的反馈,您所提到的迭代公式是状态价值函数 v 的迭代公式,前面给的公式是 Q 函数的迭代公式,这两者不同 : ) |
@VZGVainglory 感谢您的反馈,具体推导见下图: |

价值迭代做的工作类似于价值的反向传播,每次迭代做一步传播,所以中间过程的策略和价值函数是没有意义的。而策略迭代的每一次迭代的结果都是有意义的,都是一个完整的策略。 |
|
作者好,第二章中好多公式无法正常显示。 |

@guoruiqi01 感谢您的反馈,公式解析的链接出问题了,我们会尽快修复这个问题,建议您先看 pdf 版: |
@guoruiqi01 感谢您的反馈,公式解析链接已修复。 |
|
感觉这一章好难啊 |
|
每节课没有对应的代码可以跟着实践吗? |
|
最大的缺点就是缺少配套代码 |
有的 |
请查看: |
|
2.2.2贝尔曼方程 -> 2.5图下面的矩阵等式的最右侧,不应该是v(s`)么? |
您好,可以标注一下代码分别对应书上的哪个章节吗?还有就是代码的注释也有点少,辛苦了 |
|

@Gaben21 另外,蘑菇书代码还在迭代中,后续版本会加入更多注释。 |

好的,谢谢您 |
客气啦~ |
|
2.3.10马尔可夫决策过程控制 倒数第二段的第一句话不对吧:对于一个事先定好的马尔可夫决策过程,当智能体采取最佳策略的时候,最佳策略一般都是确定的。 |
您好,这句话是没问题的,当智能体采取最佳策略的时候,最佳策略一般都是确定的,即确定性策略: |

|
在本章的配套代码中from envs.simple_grid import DrunkenWalkEnv的envs找不到,能不能看一下完整代码? |
https://datawhalechina.github.io/easy-rl/#/chapter2/chapter2
Description
The text was updated successfully, but these errors were encountered: