Re-use intermediates across various contractions (Common Subexpression Elimination) #9
Comments
|
I need to think a bit on the optimization logic and how to implement it. Im kind of thinking if we are going to build another interface we should only build one that is relatively bullet proof. What if we had something like the following: This could even be extend to: This would be similar to something like |
|
I might be bikeshedding the interface question, but to me, your suggested call signature seems unnecessarily complicated in two regards,
|
contract(["A_ab B_bc C_cd", "A_ab B_bc D_cd"], ...)
|
|
This is now possible using the new backend support #17 (to an extent - you need to use |
|
That's exciting! If you could give me a hint on how to start that would be most welcome. |
|
Here's a quick demonstration: Set up to get the to the point where we have the 5 numpy arrays and two expression: import opt_einsum as oe
import numpy as np
import dask.array as da
from dask import delayed
sizes = {l: 10 for l in 'abcde'}
contraction1 = 'ab,dca,eb,cde'
terms1 = contraction1.split(',')
contraction2 = 'ab,cda,eb,cde'
terms2 = contraction2.split(',')
# define the intial set of arrays
inputs = sorted(set((*terms1, *terms2)))
np_arrays = {s: np.random.randn(*(sizes[c] for c in s)) for s in inputs}Now convert them to da_arrays = {s: da.from_array(np_arrays[s], chunks=1000) for s in inputs}
# select dask arrays for each expression
ops1 = [da_arrays[s] for s in terms1]
ops2 = [da_arrays[s] for s in terms2]
# contract!
dy1 = oe.contract(contraction1, *ops1, backend='dask')
dy2 = oe.contract(contraction2, *ops2, backend='dask')
# just wrap them in delayed so as to combine in the same computation
dy3 = delayed([dy1, dy2])
dy3.compute()
[77.13078823390276, -41.30794090122288]And we can check that the intermediaries are being used by visualizing the task graph: dy3.visualize(optimize_graph=True)
|
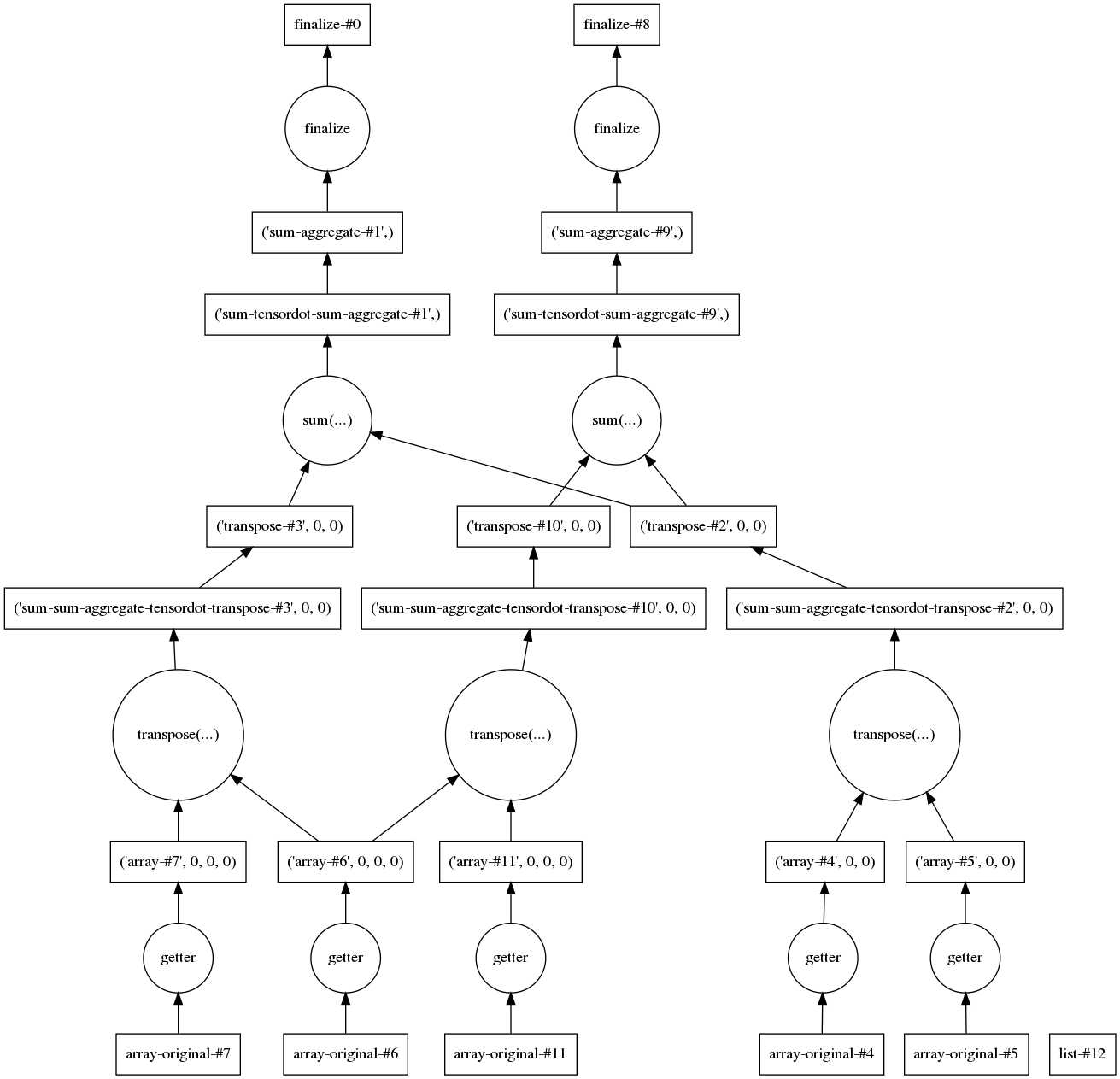
|
@jcmgray Thats really neat, could you write this up in the docs? |
|
We're achieving shared computation in Pyro by creating a custom deferred backend that cons hashes expressions. It can then use any other backend during evaluation (we're using the torch backend for evaluation). The syntax is x = torch.randn(2, 3)
y = torch.randn(3, 4)
z = torch.randn(4, 5)
with shared_intermediates():
x_, y_, z_ = map(deferred_tensor, [x, y, z])
a_ = opt_einsum.contract('ab,bc,cd->a', backend='pyro.ops.einsum.deferred')
b_ = opt_einsum.contract('ab,bc,cd->b', backend='pyro.ops.einsum.deferred')
c_ = opt_einsum.contract('ab,bc,cd->c', backend='pyro.ops.einsum.deferred')
d_ = opt_einsum.contract('ab,bc,cd->d', backend='pyro.ops.einsum.deferred')
a = a_.eval(backend='torch')
b = b_.eval(backend='torch')
c = c_.eval(backend='torch')
d = d_.eval(backend='torch')Do you have any interest in us moving this backend upstream into cc @eb8680 |
|
I think this would be neat. We might need to play a bit with the interface, but the overall idea of being able to tie intermediates together is a very positive one, and the solution is elegant. |
|
It would be really nice to have. I did play around with something similar very briefly (e.g. this gist which can act as a backend), but actually hashing the arrays using A context manager is what I had in mind as well, since it nice and explicitly limits the scope/size of the cache. My first thought would be, is the completely delayed |
That's a good point. I think we could change this to eagerly evaluate. It would also be nice to avoid the need to wrap inputs in |
|
In the hash, I don't think we need to hash all of the data. Looking at the interface of a non-writeable view would be sufficient I believe? Dask probably has an optimal way of getting, but I didn't see the hashing function on a quick browse. I don't think a bit of overhead checking if a result is in a cache would hurt |
👍 I've updated my prototype to be eager (as @jcmgray suggested), and it now clearly hashes by the |
|
Looks cool! I like the idea of doing this kind of thing: with oe.shared_intermediaries() as cache:
# do some stuff
oe.contract(...)
# do some non cached stuff
# use the same cache again
with oe.shared_intermediaries(cache):
# do even more stuff
oe.contract(...)Which looks possible with my brief reading of your code. Also, yes with an explicitly managed scope I think hashing just using key = 'tensordot', backend, id(x), id(y), axesThus keeping all the logic in the context manager and backend functions. While I remeber, I think this kind of change might require modifying |
|
Interestingly Steps: The other thing to consider is the "switched case": Normal ordering should be applied to the key to watch for these cases. A simple |
Suppose you want to compute two contractions of the same tensors, e.g. contraction strings
['ab,dca,eb,cde', 'ab,cda,eb,cde']The (globally) optimal way to do this would be to first perform the contractions over indices a,b and e, and then perform the remaining contractions over c and d for the two sets of contractions. The current opt_einsum implementation does not allow for such a global optimization of contraction order and re-use of common intermediates.
I'm still organizing my thoughts on this, and all input would be most welcome. On a side note, I believe implementing such a more general optimization strategy will also fix #7 as a by-product.
Optimization logic
A relevant publication suggesting a concrete algorithm for this optimization problem is
Hartono et al, Identifying Cost-Effective Common Subexpressions to Reduce Operation Count in Tensor Contraction Evaluations
I do not know to what extent the current code can be re-used in this more general setup, but the single-term optimization should be under control with the current implementation.
Interface
Such a multi_contract function could be called with a list of tuples (contractionString, [tensors, ..]), and would return a list of results with the same length as the input list.
Internally, one would have to find out which tensors are actually identical between the various contractions, and then use the above contraction logic. Ideally this information should be deduced automatically and not rely on user input being in the correct form. In the same spirit, dummy indices should be allowed to have arbitrary names, i.e. they should not have to match across different contractions to be correctly identified as a common subexpression.
This may require transforming the input into a 'canonical' form first to make sure that common subexpressions are captured correctly.
In contrast to the setup outlined in Hartono et al, contraction strings should maybe remain in their current 'simple' form and not be generalized to allow for numerical expressions like sums of tensors etc. Such a behavior can be implemented a posteriori with the interface described here by computing the sum of the resulting tensors, e.g.
contract('ab,ab + ab,ba', N,M) --> 'sum'(multi_contract( [('ab,ab', N,M), ('ab,ba', N,M)] ))Thus, restricting contraction strings to be of the form currently used does not cause loss of generality, the only downside being that it might lead to a slightly increased memory-footprint as the function would return several arrays instead of one.
Other thoughts?
The text was updated successfully, but these errors were encountered: