Performing machine unlearning via gradient descent, instead of gradient ascent
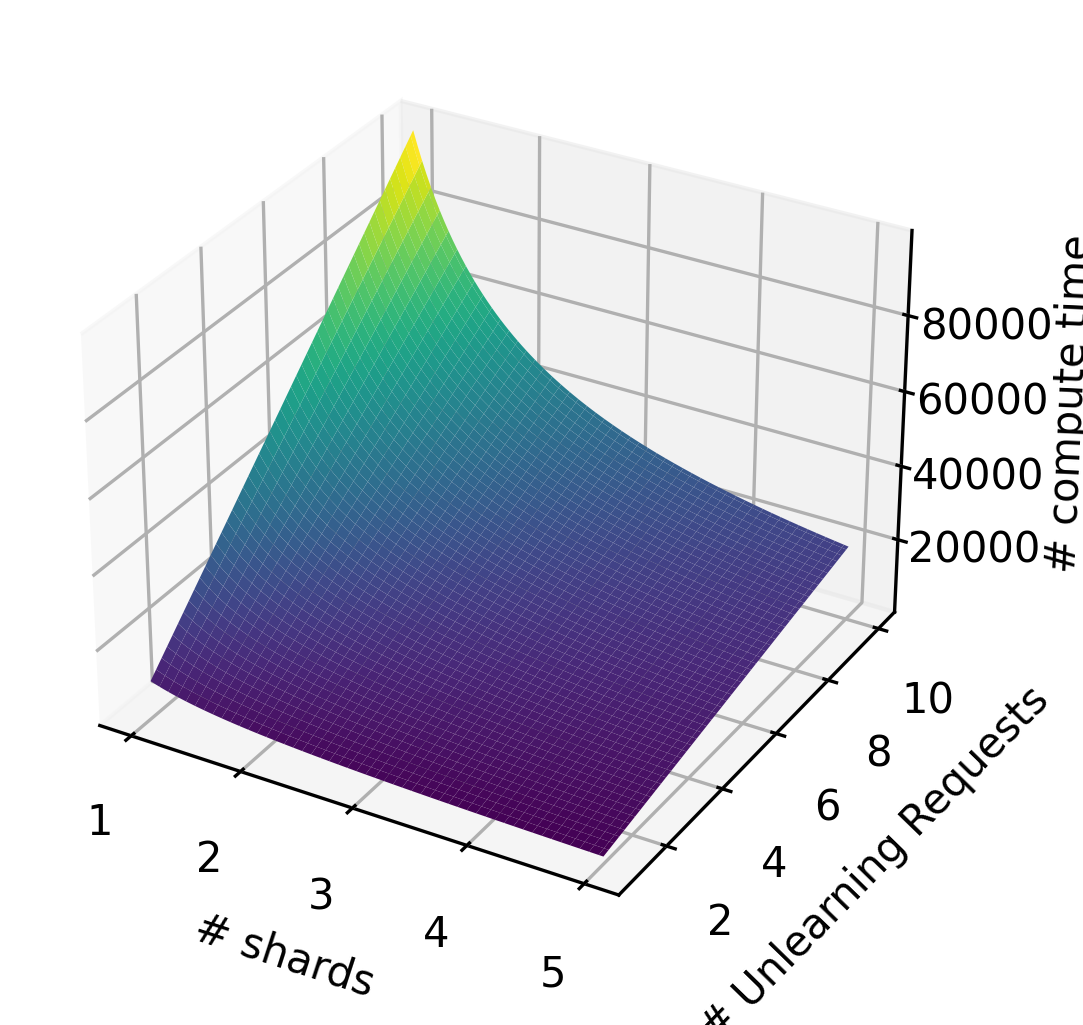
This work basically was inspired by the original Machine unlearning paper, and I was surprised that basic graident ascent was not considered in that paper. Instead of wierd training data allocation scheme was devised, which can have high storage and computation overhead, as compared to simple gradient ascent. This is evident from the first paper, where the number of unlearning samples leads to exponential computation overhead, which wouldnot be the case for gradient ascent.
But on the other hand, in later papers, machine unlearning via gradient ascent was considered.
I hereby replace the ascent with descent by minimizing
Following is the comparison of relationship between

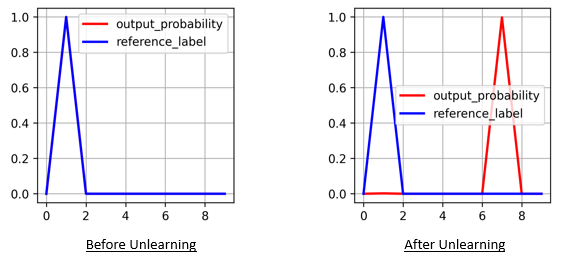
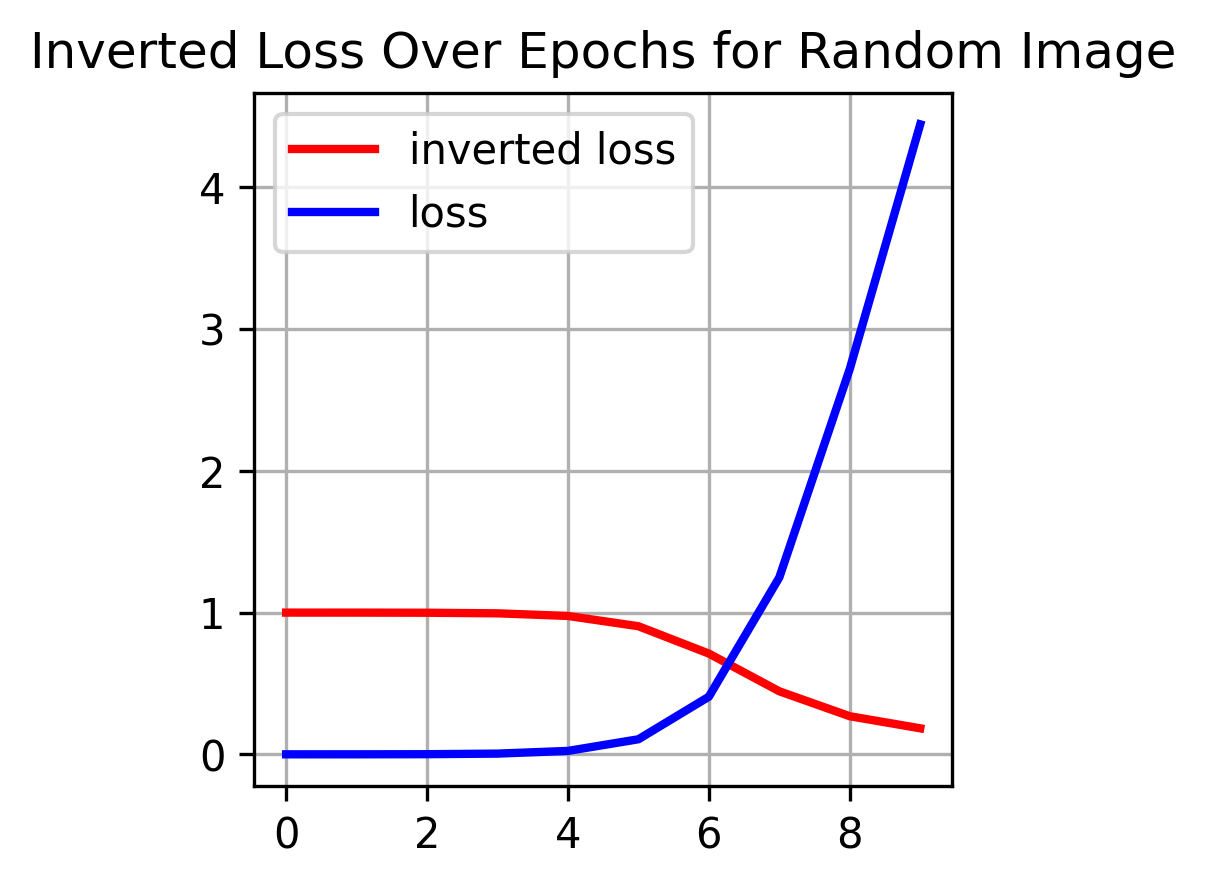
For the case of MNIST classification model, it can be seen that in remembering particular sample, we use gradient descent, which minimizes the inverted loss, while the original intended loss increases, indicating that the model is unlearning a particular sample.
Following is the comparison of output probability vector, before and after unlearning a particular MNIST sample.