PyTorch Mish - 1.5x slower training, 2.9X more memory usage vs LeakyReLU(0.1) #18
Comments
|
Hey @glenn-jocher Following is a table which shows the improvement in speed profiling for Mish: The implementation can be found here - https://github.com/thomasbrandon/mish-cuda Though this doesn't work well with Double Precision just to say. Let me know how the profiling looks using Mish CUDA. I'm working on optimizing Mish further and will keep you posted on the progress. |
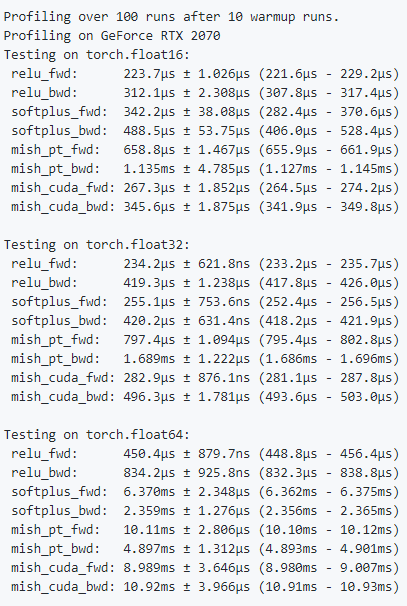
|
@digantamisra98 Hi, why you didn't integrate this ttps://github.com/thomasbrandon/mish-cuda CUDA-mish-implementation to your repository? |
|
@AlexeyAB I have added it in the Readme. To give him credits I kept his integration as his own repository and added only the baseline implementation in my own. Also his implementation was constructed recently based on a Fast.ai discussion forum long after Mish was already there. |
|
Just wondering how optimal it is to specify only Forward-implementation function without Backward-implementation? https://github.com/ultralytics/yolov3/blob/7ebb7d131078bd8357aeddf23fd68414d1593612/models.py#L124-L131 |
|
@AlexeyAB It isn't optimal. It's rather a quick start. For optimal performance, I will obviously go for both Forward and Backward Pass Implementation which has been followed by Mish CUDA, deeplearning4j, TensorFlow Addons for Mish including your implementation in darknet. |
|
Closing this issue due to inactivity. Feel free to re-open if not resolved. |
Hi, thanks for this interesting new activation function. I've tested it with YOLOv3-SPP on a V100 from https://github.com/ultralytics/yolov3 and have mixed feedback. The performance improves slightly, but the training time is much slower and the GPU memory requirements are much higher vs LeakyReLU(0.1). Any suggestions on how to improve speed/memory in PyTorch? Thanks!
From AlexeyAB/darknet#3114 (comment):
LeakyReLU(0.1)Mish()The text was updated successfully, but these errors were encountered: