请教:关于pg_trgm中文支持问题 #17
Comments
|
PG10我自己测试在有的平台上也不行,可以试试自己安装一个pg_bigm插件 ,对中文支持更好,而且对于一个字及两个字的like优化更好,缺点是只支持like不支持正则 |
|
|
|
@yjhatfdu 好插件,我试试 |
|
@digoal 2,如果单独再设置一个索引 IDX_456(COL2,col1) 3,如果col2 LIKE 'YYYY%'; 处于1和2之间,优化器就很难选择哪一个更好了 |
|
环境 macOS 10.14.1
|
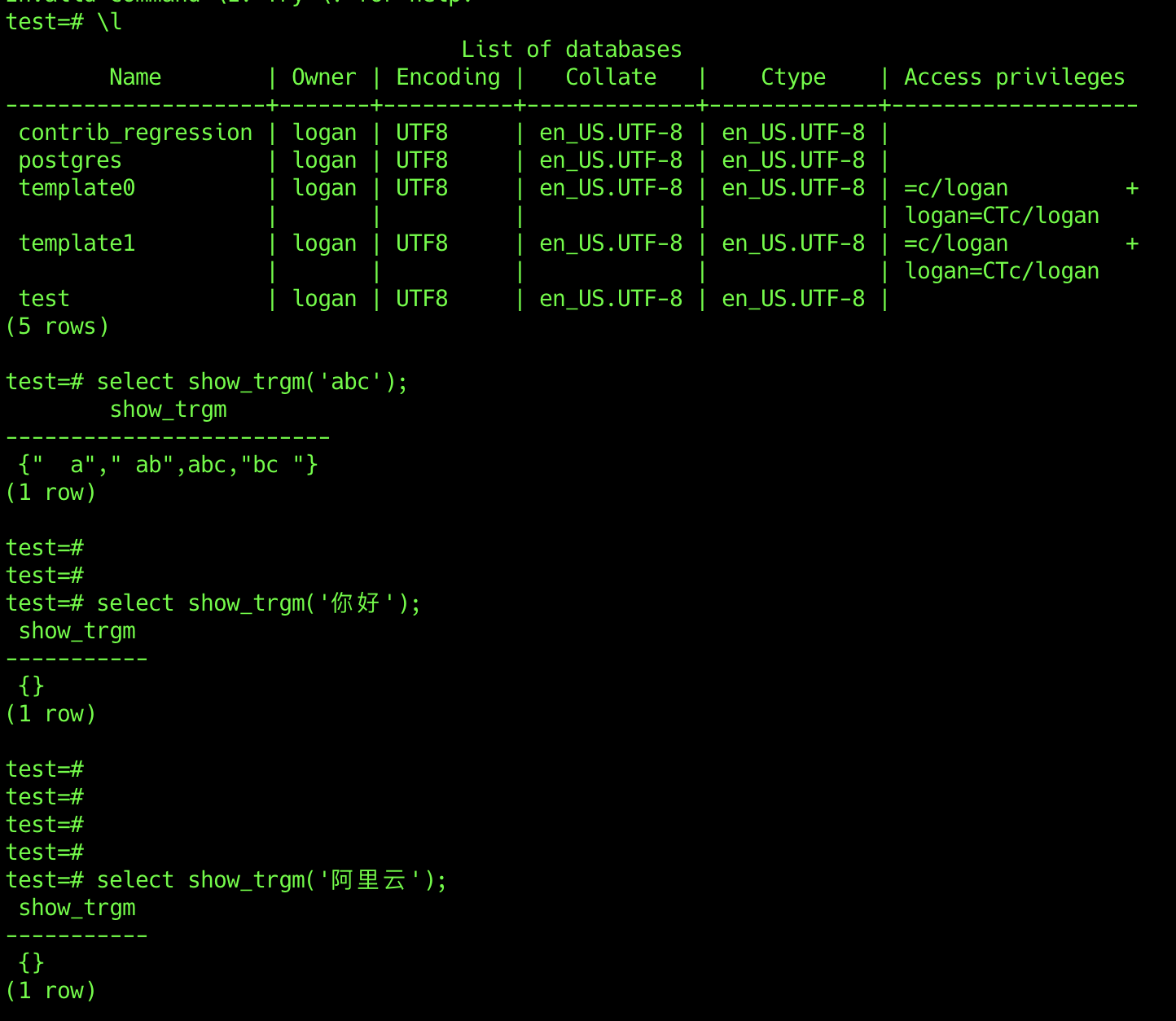
|
@lustres 看来mac系统的都有这个问题 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
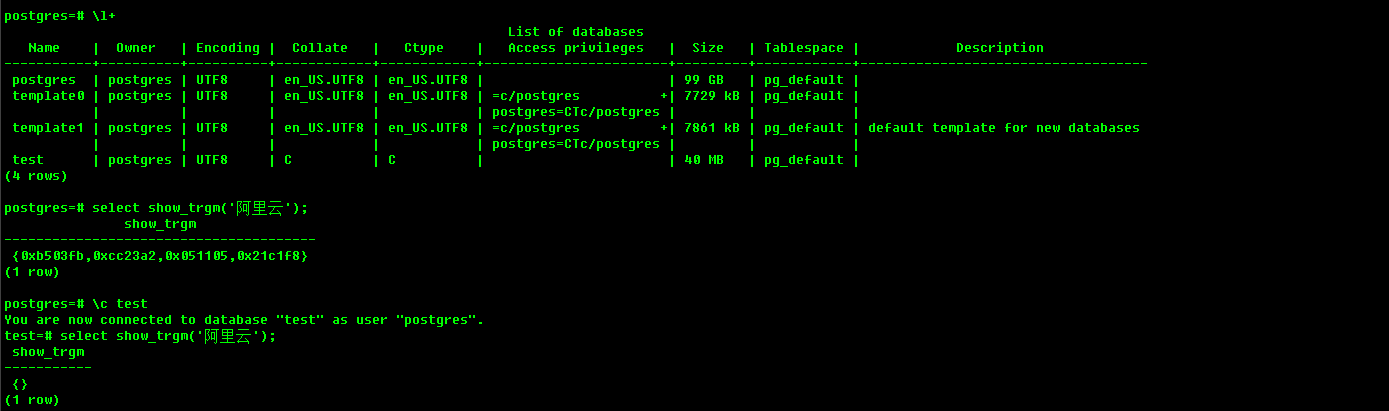
参考 中文模糊查询性能优化 by PostgreSQL trgm 及网上其他文章,都说pg_trgm已经支持multi-byte character,只要collate和ctype不是C就行,但是我自己实验还是不行
我在本地安装的10.1版本,或者是在Aliyun创建的9.4版本,结果都是一样
请问可能是什么地方出了问题?
The text was updated successfully, but these errors were encountered: