Este es el repositorio del Proyecto Final para la materia de Arquitectura de Productos de Datos del semestre 2021-2 en la Maestría en Ciencia de Datos, ITAM.
- Introducción
- Resumen
- Pregunta analítica
- Frecuencia de actualización de los datos
- Pipeline
- Sobre el Modelado y Bias Fairness
- Requerimientos_de_Infraestructura
- Instalación_y_configuración
- Ejecución
- DAG con tasks Checkpoint 5
- Estructura básica del proyecto
- Integrantes del equipo
El presente trabajo analiza el dataset Chicago Food Inspections que incluye información sobre las inspecciones de restaurantes y otros establecimientos de comida en Chicago desde el 1 de Enero 2010 al presente con el fin de predecir para nuevas observaciones si el establecimiento pasará o no la inspección.
-
Número de registros: 215,026 (esta base fue extraída el día 15/01/2021 y el número de registros varía con una nueva fecha.)
-
Número de columnas: 17
-
Las variables originales, así como su descripción (tomada directamente de la referencia oficial sugerida para su consulta dentro del portal Chicago Food Inspections) son:
- Inspection ID: Es el ID o número único asignado a la inspección.
- DBA Name: Nombre legal del establecimiento. DBA significa: 'Doing business as'.
- AKA Name: Nombre comercial del establecimiento, es decir, el nombre con el que sus clientes identifican al restaurante. AKA significa 'Also known as'.
- License #: Es el ID o número único asignado al establecimiento para el propósito de asignar una licencia por parte del Departamento de Asuntos de Negocios y Protección al Consumidor.
- Facility Type: Tipo de Establecimiento. Se clasifican en uno de los siguientes tipos: 'Bakery', 'Banquet Hall', 'Candy Store', 'Caterer', 'Coffee shop', 'Day Care Center (for ages less than 2)', 'Day Care Center (for ages 2 – 6)', 'Day Care Center (combo, for ages less than 2 and 2 – 6 combined)', 'Gas Station', 'Golden Diner', 'Grocery store', 'Hospital', 'Long term Care Center(nursing home)', 'Liquor Store', 'Mobile Food Dispenser', 'Restaurant', 'Paleteria', 'School', 'Shelter', 'Tavern', 'Social club', 'Wholesaler', o 'Wrigley Field Rooftop'.
- Risk: Riesgo asociado a la Categoría del Establecimiento. Cada establecimiento es categorizado de acuerdo al riesgo asociado a dañar la salud de los consumidores, siendo 1 el mayor riesgo y 3 el de menor riesgo. La frecuencia de la inspección está relacionada con el nivel de riesgo, donde el riesgo 1 corresponde a los establecimientos inspeccionados con mayor frecuencia y el riesgo 3 a los establecimientos inspeccionados con menos frecuencia.
- Address: Dirección completa donde se localiza el establecimiento.
- City: Ciudad donde se localiza el establecimiento.
- State: Estado donde se localiza el establecimiento.
- Zip: Código postal donde se localiza el establecimiento.
- Inspection Date: Fecha en la que se llevó a cabo la inspección. Es probable que un establecimiento en particular tenga varias inspecciones que son identificadas por diferentes fechas de inspección.
- Inspection Type: Tipo de inspección que se realizó.Se dividen en: 'Canvass', inspección más común cuya frecuencia se relaciona con el riesgo relativo del establecimiento; 'Consultation', la inspección se realiza a solicitud del dueño del establecimiento previo a su apertura; 'Complaint', la inspección se realiza en respuesta a una queja contra el establecimiento; 'License', la inspección se realiza como parte del requisito para que el establecimiento reciba su licencia para operar; 'Suspect Food Poisoning', la inspección se lleva a cabo en respuesta a que una o más personas reclaman haberse enfermado como consecuencia de haber comido en el establecimiento; 'Task-force inspection', cuando se realiza la inspección a un bar or taverna. 'Re-inspections' o reinspecciones pueden llevarse a cabo en la mayoría de estos tipos de inspección.
- Results: Corresponde al resultado de una inspección: 'Pass', 'Pass with conditions' o 'Fail' son posibles resultados. En los establecimientos que recibieron como resultado ‘Pass’ no se encontraron violaciones de caracter crítico o serio (que corresponden a los números de violación del 1 al 14 y 15 al 29, respectivamente). En los establecimientos que recibieron ‘Pass with conditions’ se encontraron violaciones críticas o serias pero fueron corregidas durante la inspección. En los establecimientos que recibieron ‘Fail’ se encontraron violaciones críticas o serias que no fueron corregidas durante la inspección. Si un establecimiento recibe como resultado ‘Fail’ no necesariamente significa que su licencia es suspendida. Establecimientos que fueron encontrados cerrados de manera permanente 'Out of Business' o sin localizar 'Not Located' están indicados como tal.
- Violations: Un establecimiento puede recibir una o más de 45 violaciones diferentes (los números de violación van de 1 al 44 y el 70). Para evitar cada número de violación listado en un establecimiento dado, el establecimiento debe cumplir con cada requisito para no recibir una violación en el reporte de la inspección, donde se detalla una descripción específica de los hallazgos que causaron la violación por la que fueron reportados.
- Latitude: Coordenada geográfica de latitud donde se localiza el establecimiento.
- Longitude: Coordenada geográfica de longitud donde se localiza el establecimiento.
- Location: Coordenadas geográficas de (longitud y latitud) donde se localiza el establecimiento.
La pregunta analítica a contestar con el modelo predictivo es: ¿El establecimiento pasará o no la inspección?
La frecuencia de la actualización del dataset Chicago Food Inspections es diaria. Sin embargo, la frecuencia de actualización de nuestro producto de datos será semanal.
El pipeline diseñado para el proyecto incluye dos posibles caminos que inician con un proceso de ETL común.

- Extract: Mediante una conexión programática vía API, descargamos los datos (Task de Ingesta) del sitio de Chicago Food Inspections cuya documentación puedes encontrar aquí.
- Load: Los datos se cargan (Task de Almacenamiento) en un bucket de S3 en AWS en formato .pkl.
- Transform: Se aplican tareas de Cleaning & Preprocessing y Feature Engineering para obtener las columnas que el modelo requerirá. Las tablas corresponientes así como los metadatos asociados a cada una de las tarea se cargan en RDS.
El objetivo de este camino es encontrar el mejor modelo usando la información histórica.
- Modelado: Se realiza una extracción de una muestra de los datos (Task de Entrenamiento o Training) con el propósito de realizar el modelado sobre la variable a predecir: si pasará (etiqueta positiva) o no la inspección. Luego, mediante un magic loop, se obtiene el mejor modelo (Task de Model Selection) para predecir con base en la métrica seleccionada: Precision (porque quieres ser preciso en decirle al establecimiento que no pasará la inspección) a partir de los algoritmos de Decision Trees y Random Forest que cuentan con distintos hiperparámetros. El modelo seleccionado queda almacenado en un pickle en S3. En esta etapa también se guardan las predicciones del conjunto de entrenamiento (PredictTrainTask) para el monitoreo.
- Sesgo e Inequidad: Se identifica y cuantifica los sesgos e inequidades generados por los resultados de las predicciones del modelo en los grupos conformados por las zonas sociodemográficas: zone y tipos generales de negocios facility_group (definidos a partir de una agrupación de las variables de zip code y facility type -catálogo que vive en RDS-) apoyados por el toolkit de "Aequitas" (Task de Bias & Fairness).
El objetivo de este camino es, usando el mejor modelo, hacer las predicciones del período requerido.
- Predicciones: Usando los parámetos introducidos (tipo de ingesta, y fecha), se realiza la predicción con el modelo seleccionado (Task de Prediccion). Posteriormente se reprocesa esta información dos veces, una para construir la tabla que consulta la Api (Task de Almacenamiento Api), y otra para el monitoreo (Task de Monitoreo).
Cabe mencionar que por cada una de las tareas o Task mencionadas, se realizaron distintas pruebas unitarias o unit test con el propósito de probar una unidad/funcionalidad de código aislada para cada verificar que cada una haga lo que esperamos que realice y evitemos arrastrar errores en las tareas subsecuentes.
A continuación, respondemos algunas preguntas que nos proporcionan más contexto sobre el Modelado y Sesgo e Inequidades:
- ¿Tu modelo es punitivo o asistivo? ¿por qué?
- Se consideró que nuestro modelo es de tipo asistivo, pues el uso del modelo está pensado para ayudar al establecimiento con una predicción de si pasará o no una inspección. Esto le brindará información valiosa a la empresa indpendientemente de si se estima que pasará o no una próxima inspección, es decir, es un modelo del estilo preventivo en el sentido de que si se predice que no pasa la inspección pueda tomar ciertas acciones para mejorar antes de que una inspección real suceda.
- ¿Cuáles son los atributos protegidos?
- Tomamos como atributos protegidos zone y facility group. Que como mencionamos previamente, son variables que fueron generadas a partir de una agrupación de las variables de zip code y facility type respectivamente a partir de los catálogos que viven en RDS (tablas: zip_zones y facilite_group en el esquema clean)
- ¿Qué grupos de referencia tiene cada atributo protegido?, explica el por qué
- El grupo de referencia dentro del atributo zone es 'West' y dentro del atributo facility group es 'grocery'. Para definir qué grupo de referencia seleccionamos en cada atributo, se calculó el FNR y así el grupo que consistentemente mostró un nivel relativamente bajo de FNR (más favorecido) fue el escogido para ayudarnos a verificar qué tan alejados estaban los demás grupos.
- ¿Qué métricas cuantificas/ocupas en sesgo e inequidad? explica por qué
- Debido a nuestro enfoque asistivo, calculamos las métricas de False Omission Rate (FOR) y False Negative Rate (FNR). FOR se utiliza cuando nos interesa conocer si hay un sesgo hacia algún grupo de no ser seleccionado como etiqueta positiva (1, que significa que sí pasó la inspección), por lo que se busca tener paridad entre los FNR de todos los grupos con respecto al atributo "protegido" asociado a los modelos asistivos, de tal forma que ambas métricas van de la mano con nuestro enfoque.
Los datos que se utilizan son almacenados en un bucket de Amazon S3. Una instancia EC2 de AWS llamada Bastión se utiliza como un filtro de seguridad el cual se conecta con otra EC2 (que se generó a partir de una imagen de la EC2 de bastión) utilizada para correr todo el código; y los resultados de cada etapa son almacenados en s3 o bien en un servicio RDS de AWS.
Infraestructura: AWS
+ AMI: ami-025102f49d03bec05, Ubuntu Server 18.04 LTS (HVM)
+ EC2 Instance Bastion: T3.small
+ GPU: 1
+ vCPU: 2
+ RAM: 2 GB
+ OS: Ubuntu Server 18.04 LTS
+ Volumes: 1
+ Type: gp2
+ Size: 20 GB
+ AMI: ami-0dfa90bae725936dc, Ubuntu Server 18.04 LTS (HVM)
+ EC2 Instance: c5.xlarge
+ GPU: 1
+ vCPU: 4
+ RAM: 8 GB
+ OS: Ubuntu Server 18.04 LTS
+ Volumes: 1
+ Type: gp2
+ Size: 20 GB
+ RDS: PostgreSQL
+ Engine: PostgreSQL
+ Engine version: 12.5
+ Instance: db.t2.micro
+ vCPU: 1
+ RAM: 1 GB
+ Storage: 100 GB
Para poder interactuar con este repositorio, debes clonar la rama main para hacer una copia local del repo en tu máquina. Es necesario crear un pyenv-virtualenv con la versión de Python 3.8.6, activarlo e instalar los requirements.txt ejecutando el siguiente comando una vez estando dentro del ambiente virtual:
pip install -r requirements.txtLa corrida del pipeline involucra la lectura de una serie de credenciales relacionadas con los servicios S3 y RDS de AWS así como un App Token generado de Food Inspections antes mencionado. Por lo que se debe crear un archivo: ./conf/local/credentials.yaml que debe contener lo antes mencionado.
- A continuación se muestra un ejemplo genérico del contenido que debe tener este archivo:
s3:
aws_access_key_id: "your_key_id"
aws_secret_access_key: "your_secret_key"
food_inspections:
api_token: "your_session_token_for_API_Chicago_Food"
db:
user: "your_user"
password: "your_databse_password"
database: "food"
host: "your_end-point"
port: "your_port"Una vez que se tienen las credenciales, deben crearse cada una de los esquemas y tablas que se usarán usando los scripts en **./sql/ ** (excepto el código de drop_db.sql).
Los scripts se ejecutan en postgres, desde el home del repositorio, de la siguiente forma:
\i ./sql/create_db.sql
\i ./sql/create_bias_fairness_table.sql
\i ./sql/create_clean_table.sql
\i ./sql/create_facility_table.sql
\i ./sql/create_feat_eng_table.sql
\i ./sql/create_metadata_table.sql
\i ./sql/create_models_table.sql
\i ./sql/create_monitoreo_table.sql
\i ./sql/create_predict_table.sql
\i ./sql/create_predict_train_table.sql
\i ./sql/create_scores_table.sql
\i ./sql/create_zip_table.sqlPara ejecutar los tasks, es necesario estar posicionado en la carpeta de data-product-arquitecture y ejecutar en terminal:
export PYTHONPATH=$PWDDentro de src/utils/constants.py se guardaron las constantes de nuestro proyecto: PATH_CREDENCIALES, NOMBRE_BUCKET y ID_SOCRATA para referenciar la ruta del archivo ./conf/local/credentials.yaml, colocar el nombre del BUCKET para conectarnos a S3 y guardar el ID de la API para la extracción de los datos con el objetivo de que se puedan editar si se quiere reproducir el proyecto.
Para la creación de los tasks, se utilizó Luigi que es un Orquestador de pipelines que utiliza un DAG para administrar el orden de las tareas en el pipeline. Puedes consultar la documentación de Luigi aquí. Para habilitar su scheduler desde el browser de tu navegador debes abrir otra terminal, activar el pyenv y escribir el siguiente comando desde otra terminal:
luigid- Para la ejecución de nuestro pipeline hasta el momento, debemos ejecutar el siquiente comando:
PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi MonitoreoTask --date-ing 2021-05-10 --type-ing consecutiveDicho comando ejecuta la tarea correspondiente al último nodo de nuestro DAG, por lo que en forma retrospectiva ejecuta cada una de las tareas (tasks) del Pipeline, hasta generar la tabla de scores asociados al Monitoreo. A lo largo del proceso construido con las tareas de luigi se generan tablas/bases que se guardan ya sea en local (respaldos de las descargas de la API de Chicago Foods), S3 (tanto las descargas de la API de Chicago Foods como el mejor modelo seleccionado), o bien en RDS (la mayoría de las tablas). Cabe señalar que la clase de Luigi MonitoreoTask debe recibir como parámetros:
- nombre del bucket (en nuestro caso el default es: data-product-architecture-4) donde se desea guardar el archivo con los datos históricos en formato .pkl
- la fecha de ejecución en formato 'YYYY-MM-DD' (la cual indica el día de corte hasta donde se descargarán los datos, donde el default la fecha del día en que se ejecuta)
- el tipo de ingestión deberá ser *initial*, para obtener la información desde Enero de 2010 y *consecutive* (default) para obtener una actualización de los últimos 7 días incluyendo la fecha de corte.
Una vez ejecutada esta instrucción, puedes abrir un browser y escribir localhost:8082/ para ver el DAG con los tasks.
Como vemos, para Luigi no es necesario correr los tasks previos de forma individual, ya que cada task tiene asociado una tarea que le precede, y en caso de que se detecte que ésta no ha sido ejecutada, primero correrá dicha tarea y luego la solicitada, y de esa forma es posible correr todo el proceso ejecutando únicamente el último task, que corresponde a MonitoreoTask. En Luigi los pipelines se diseñan de tal forma que para correr todo el proceso se ejecuta la última tarea o task, y en forma recursiva y retroactiva ejecutará todas las tareas que le precedan requeridas para llegar al resultado del último task.
A continuación añadimos el listado con los nombres de todas las tareas disponibles en nuestro pipeline que también se pueden ejecutar de forma individual así como la descripción y un ejemplo de cómo ejecutarla:
| Tarea | Descripción | Ejemplo de cómo correrlo |
|---|---|---|
| MonitoreoTask | Genera tabla monitoreo para Dashboard | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi MonitoreoTask --date-ing 2021-05-23 --type-ing consecutive |
| AlmacenamientoTask | Genera tabla scores para API | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi AlmacenamientoTask --date-ing 2021-05-23 --type-ing consecutive |
| PredictMetaTask | Genera metadatos asociados a predict | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi PredictMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestPredictTask | Revisa que la tabla de predicciones tenga al menos un registro y verifica que el número de columnas sea 9 | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestPredictTask --date-ing 2021-05-23 --type-ing consecutive |
| PredictTask | Genera tabla de predicciones para nuevos datos | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi PredictTask --date-ing 2021-05-10 --type-ing consecutive |
| PredictTrainTask | Genera tabla de predicciones para entrenamiento | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi PredictTrainTask --date-ing 2021-05-23 --type-ing consecutive |
| BiasFairnessMetaTask | Genera metadatos asociados a sesgos e inequidades | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi BiasFairnessMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestBiasFairnessTask | Checa que la tabla de sesgo e inequidad exista y verifica que el número de columnas sea 8 | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestBiasFairnessTask --date-ing 2021-05-23 --type-ing consecutive |
| BiasFairnessTask | Construye tabla de sesgos e inequidades | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi BiasFairnessTask --date-ing 2021-05-23 --type-ing consecutive |
| SeleccionMetaTask | Genera metadatos asociados a la selección del modelo | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi SeleccionMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestSeleccionTask | Se verifica que el mejor modelo seleccionado sea un Decision Tree (genera error si no) | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestSeleccionTask --date-ing 2021-05-23 --type-ing consecutive |
| SeleccionTask | Realiza selección del mejor modelo con base en la métrica Precision | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi SeleccionTask --date-ing 2021-05-23 --type-ing consecutive |
| TrainMetaTask | Genera metadatos asociados a Entrenamiento | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TrainMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestTrainTask | Se revisa que la base no esté vacía y además cuente con 8 columnas | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestTrainTask --date-ing 2021-05-23 --type-ing consecutive |
| TrainTask | Realiza entrenamiento del modelo | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TrainTask --date-ing 2021-05-23 --type-ing consecutive |
| FeatEngMetaTask | Genera metadatos asociados a Feature Engineering | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi FeatEngMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestFeatEngTask | Se revisa que la base no esté vacía y además cuente con 38 columnas | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestFeatEngTask --date-ing 2021-05-23 --type-ing consecutive |
| FeatEngTask | Se realiza feature engineering | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi FeatEngTask --date-ing 2021-05-23 --type-ing consecutive |
| PrepMetaTask | Genera metadatos asociados a limpieza y preprocesamiento | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi PrepMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestPrepTask | Se revisa que la base no esté vacía y además cuente con 13 columnas | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestPrepTask --date-ing 2021-05-23 --type-ing consecutive |
| PrepTask | Realiza preprocesamiento y limpieza de la base | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi PrepTask --date-ing 2021-05-23 --type-ing consecutive |
| AlmMetaTask | Genera metadatos asociados a almacenamiento | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi AlmMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestAlmTask | Se prueba que el pickle en S3 no esté vacío | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestAlmTask --date-ing 2021-05-23 --type-ing consecutive |
| AlmTask | Almacena los de datos en un pickle en S3 | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi AlmTask --date-ing 2021-05-23 --type-ing consecutive |
| IngMetaTask | Genera metadatos asociados a ingesta | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi IngMetaTask --date-ing 2021-05-23 --type-ing consecutive |
| TestIngTask | Verifica que el número de columnas de la base ingestada sea 17 | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi TestIngTask --date-ing 2021-05-23 --type-ing consecutive |
| IngTask | Genera la ingesta de datos | PYTHONPATH=$PWD luigi --module src.pipeline.tareas_luigi IngTask --date-ing 2021-05-23 --type-ing consecutive |
Finalmente, es posible acceder a nuestra base "food" introduciendo el siguiente comando:
psql -h NombreEndpoint&port -U nombreusuario -d foodY luego ejecutar el siguiente comando para poder ver los esquemas asociados a la base food para posteriormente hacer los querys que se deseen.
set search_path=api,clean,meta,models,pred,public;- Para la ejecución de nuestra API vía Flask, debemos ejecutar el siquiente comando, en una terminal con el Pyenv activado y posicionado en la carpeta data-product-architecture:
export PYTHONPATH=$PWD
export FLASK_APP=./infrastructure/Api/almacenamiento_api.py
flask run --host=0.0.0.0Una vez ejecutados los comandos anteriores, puedes abrir un browser y escribir localhost:5000/ para ver los dos endpoints para hacer consultas con respecto a un ID de establecimiento y una fecha determinada para generar predicciones.
- Para la ejecución del nuestro dashboard de monitoreo, debemos ejecutar el siquiente comando, en una terminal con el Pyenv activado y posicionado en la carpeta data-product-architecture:
export PYTHONPATH=$PWD
python ./src/utils/monitoreo.pyUna vez ejecutados los comandos anteriores, puedes abrir un browser y escribir localhost:8050/ para ver los dos histogramas de scores asociados al modelo, el primero muestra los datos del entrenamiento y el segundo la gráfica de las predicciones consecutivas que va generando el modelo.
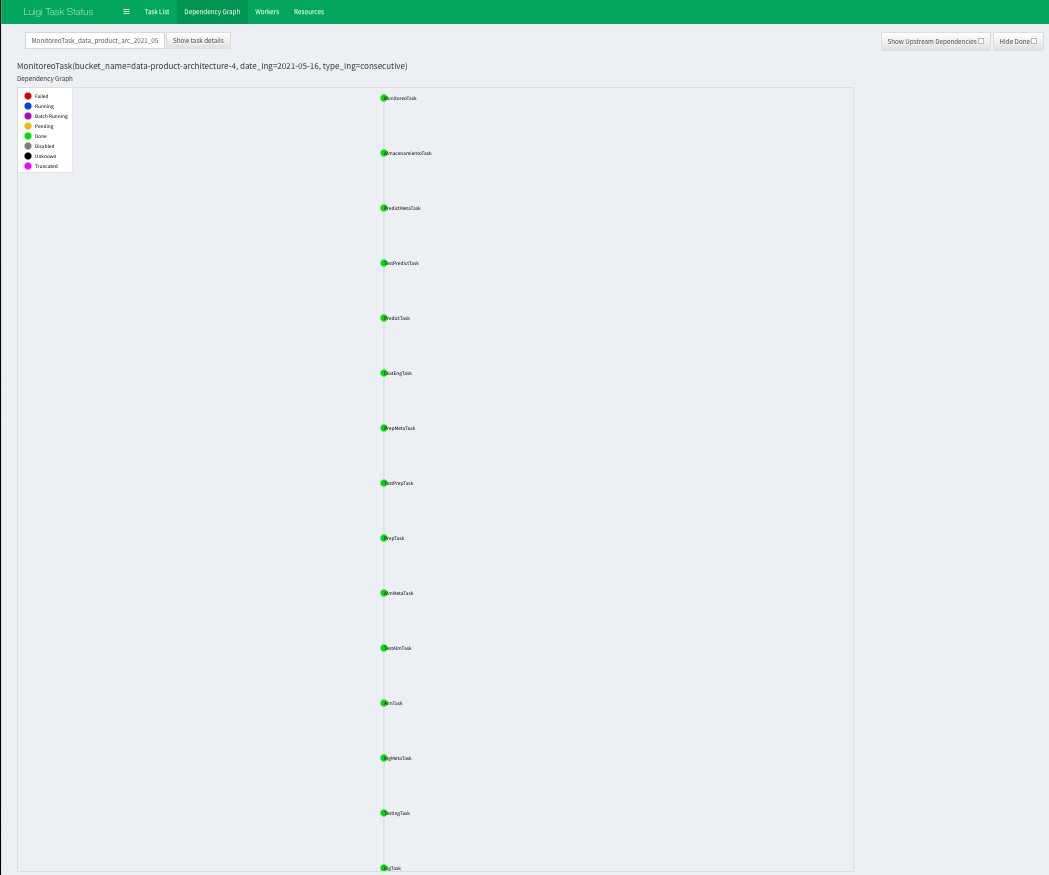
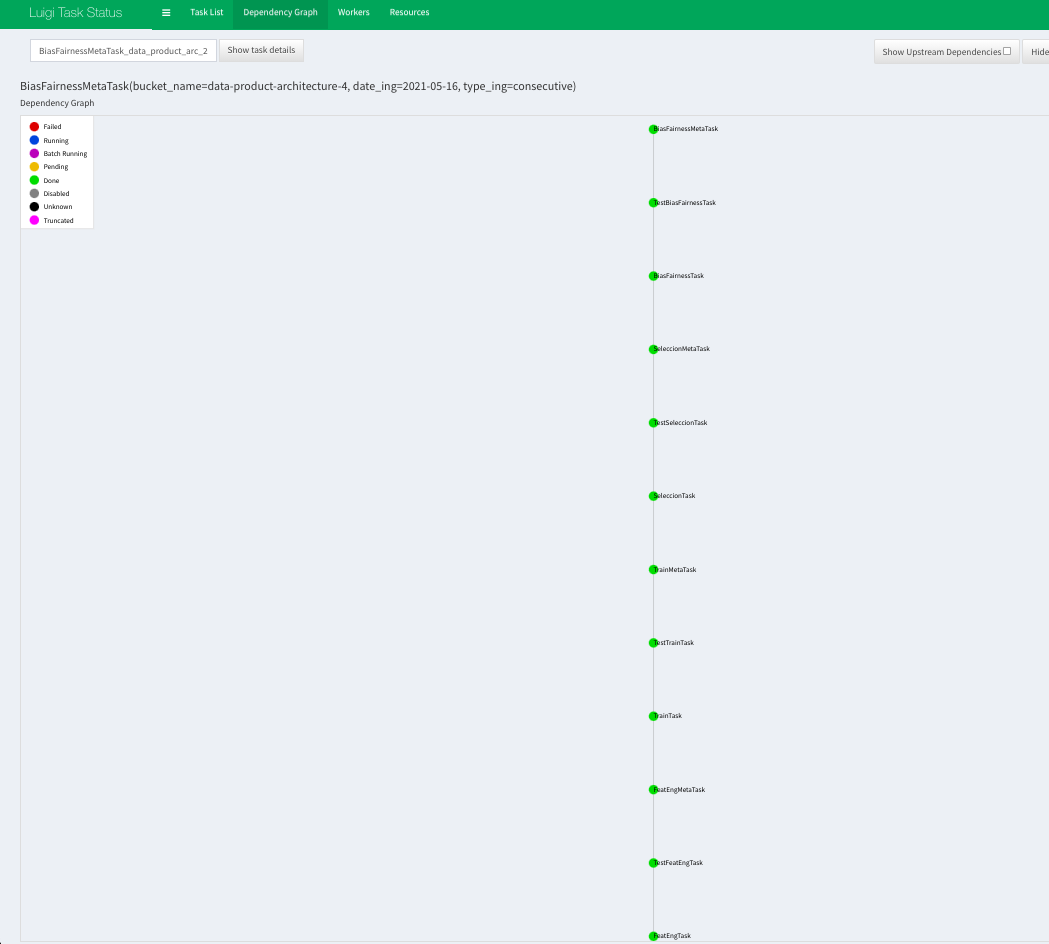
Una vez ejecutado los comandos anteriores, se presenta como ejemplo una captura de nuestro DAG final con todos los tasks en "Done".
10.1. DAG desde Task de Ingestión hasta Monitoreo
10.2. DAG desde Task de Feature Engineering hasta BiasFairnessMetaTask
├── README.md <- The top-level README for developers using this project.
├── conf
│ ├── base <- Space for shared configurations like parameters
│ ├── local <- Space for local configurations, usually credentials
│
├── docs <- Space for Sphinx documentation
│
├── notebooks <- Jupyter notebooks.
│ ├── eda <- In this folder you can find our Exploratory Data Analysis (EDA)
│
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│
├── results <- Intermediate analysis as HTML, PDF, LaTeX, etc.
│
├── requirements.txt <- The requirements file
│
├── .gitignore <- Avoids uploading data, credentials, outputs, system files etc
│
├── infrastructure
├── Api
├── sql
├── setup.py
├── src <- Source code for use in this project.
├── __init__.py <- Makes src a Python module
│
├── utils <- Functions used across the project
│
│
├── etl <- Scripts to transform data from raw to intermediate
│
│
├── pipeline <- Script with Luigi Tasks for ingestion and storage
├── tests <- Unit tests for Luigi Tasks Figura 1. Estructura básica del proyecto.
En la siguiente tabla se encuentran los integrantes del equipo:
| # | Persona | Github |
|---|---|---|
| 1 | Bruno | brunocgf |
| 2 | Dorely | DorelyMS |
| 3 | Guillermo | gzarazua |
| 4 | Yusuri | YusuriAR |