Trying to implement YoloV4 in ML.NET but running into some trouble (I'm quite new to all of this) #5466
Comments
|
@Lynx1820 , I saw you self assigned yourself :), any idea's already? |
|
Hi @devedse, how are you reading your python labels? |
|
@Lynx1820 I'm debugging through the code. This is the screenshot with all labels: So you can see the array with 7, 16 and 1 (which are dog / bicycle / truck) |

|
@Lynx1820 , I see the input and output layers are different from the YOLO v4 model available in onnx/models. I did an implementation using this model here: YOLO v4 in ML.Net. Few comments:
Also, I think this bit of code in your repos is not correct: if (boxes.Count != confs.Count)
{
throw new InvalidOperationException("Errrorrrr");
}This is the input and output of your model: |

|
Hi @devedse, Your YOLOV4 file seems to be corrupted. Do you mind updating it? |

|
@Lynx1820 , the file is not corrupted, it's checked into Github using Git LFS. If you use the latest version of git then it will automatically checkout files from Git LFS as well. (Without LFS you can only commit files up to a maximum of 50mb to Github). So if you want the model to work you need to either manually downoad it from Github or update your git command line tools :). |
|
@BobLd , thanks for that elaborate answer. Using your fix mentioned in the first comment I finally managed to get some data from the model that makes sense (the dog, bicycle and truck are all detected): What I can't figure out though is why the boxes seem to be at the wrong location. When I check the python code, there seems to be no post processing whatsoever on the boxes. They pass just use it to call cv2 to draw a rectangle: In my code rather then 2 coordinates we need the width and height, so I'm doing a tiny bit of post processing: The OriginalStuff array however also contains values at position 1 and 3 that don't really make sense. The first value (y) is
Could it be that I need to do RGB -> BGR conversion or something? Besides my own problems I do have some questions about your comment / code though 😄:
|


TLDR:Try using
More details:Could it be that I need to do RGB -> BGR conversion or something? My first impression was no, as they extract it using the following (cv2 extract in BGR afak, they convert to RGB): sized = cv2.cvtColor(sized, cv2.COLOR_BGR2RGB)but looking in more details at the input preprocessed image: but then they do a transpose, and the values seems to appear in BGR order: So do try to extract in BGR order using Also, I think you need to use sized = cv2.resize(img, (416, 416))EDIT: 1. In your code you're using a predictionengine whereas in my code (that I got from the Microsoft samples) I call pipeline.Fit(...) somewhere and then use model.Transform(...). Do you know the difference? 2. What is the use of the shapeDictionary you're using? What I can't figure out though is why the boxes seem to be at the wrong location. When I check the python code, there seems to be no post processing whatsoever on the boxes. They pass just use it to call cv2 to draw a rectangle: 4. In your model you seem to have 3 outputs that are all the same. Why doesn't the model just generate one output then? These outputs are merged in your model (and this is why you don't need to deal with anchors I guess). You can find more info here. The part of interest is: 5. I thought Yolov4 was simply Yolov4, but apparently there's numerous models that are called Yolov4. Any ideas? 6. When I run the Yolov4 model I got through C# and Python. Should the output of the model be exactly the same? (Or can there be some difference in the way C# executes the .onnx file and the way Python does it?) |



|
@BobLd thanks again for your amazingly elaborate answer. I'll check it out later once I'm at my pc. |
|
@BobLd , I just managed to implement your fixes / ideas. The confidence is a bit higher now, but the boxes however still don't line up.
|

|
Ok I just fixed it finally 😄, apparently an issue on my side. I was doing some wrong comparisons with indexes.
|

|
amazing! Great to see you managed to make it work! |
|
I do have a few more questions, not sure if you know the answer though:
|
|
Thank you for your elaborate answer @BobLd!
Closing this issue, but feel free to follow up if you have more questions. |
System information
Introduction
I'm currently trying to use the YoloV4 model inside ML.NET but whenever I try to put an image through the model I get very strange results from the model. (It mainly finds backpacks, handbags, some apples and some other unexpected results). The image I'm using:

I created a repository to reproduce my issue as well:
https://github.com/devedse/DeveMLNetTest
Disclaimer: I'm quite new to all of this 😄
Steps I've taken
I first wanted to obtain a pre-trained model which I was sure worked so I did the following steps:
checkpoints\Yolov4_epoch1.pthdemo_pytorch2onnx.pywith debug enabled.When you do this you can step through the code where the output from the model is parsed (this shows the labels for all boxes with a confidence higher then 0.6):
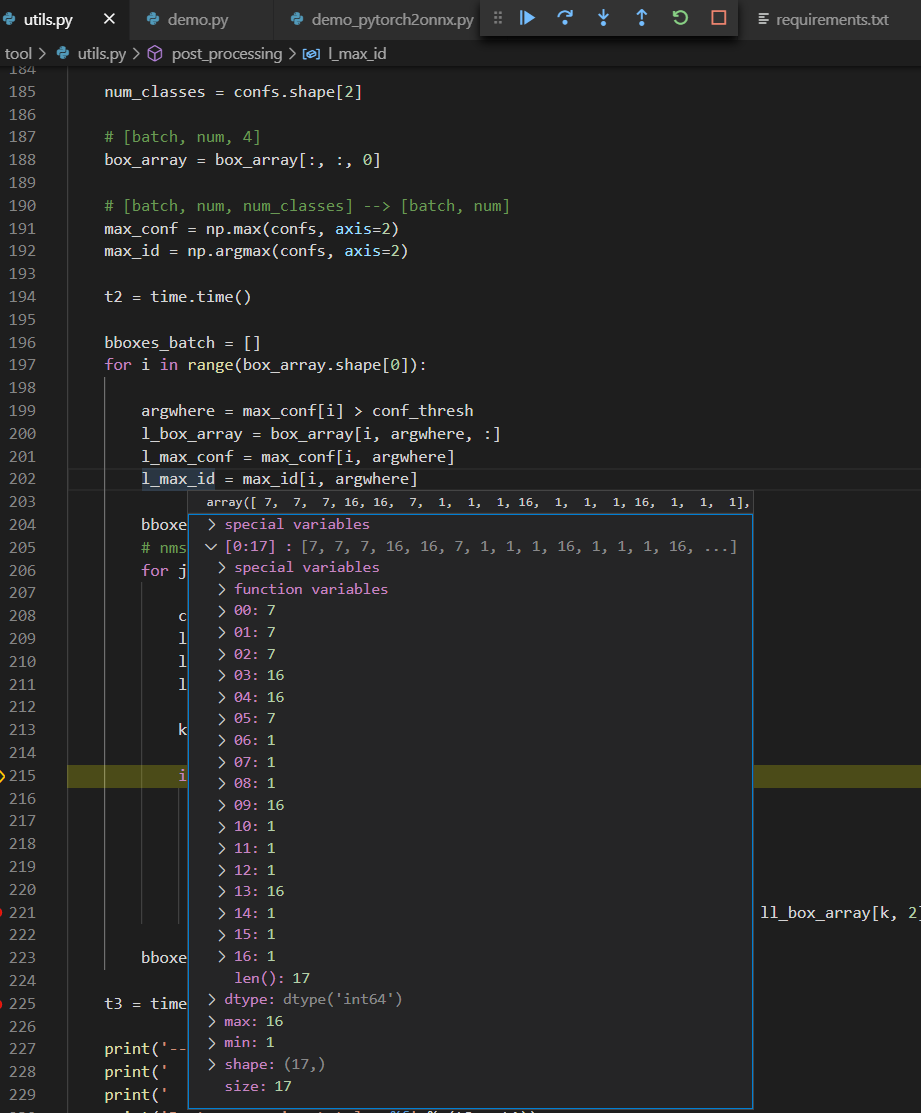
When we look up these labels, we can see that (all +1 since it's a 0-index array):
So the results in Python seem to be correct. This python script first converts the model to an ONNX model and then uses that model to do the inference.
When I now start using the model inside C# though and try to parse through the results in exactly the same way I find completely different results:
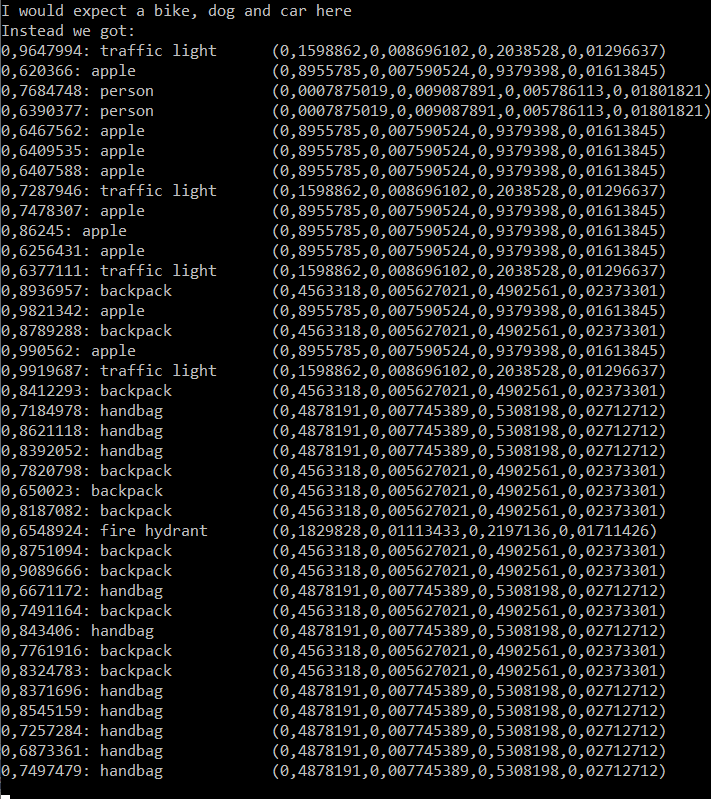
Could it be that the model is somehow creating garbage data?
Anyway, here's the code that I'm
MLContext:
Code to parse model output:
Can someone give me some hints / ideas on why I could be running into this issue?
Also feel free to clone the repo and press F5. It should simply build / run.
https://github.com/devedse/DeveMLNetTest
The text was updated successfully, but these errors were encountered: