Orleans Transactions #3369
Comments
|
Thanks for the issue explaining the steps.
I understand, and agree that we should avoid inheritance and use DI/facets to make it work. I dream with a day we will have (almost) POCO grain classes. However, I don't understand the change from locking to timestamp. Are you saying that you are using optimistic concurrency on this implementation instead of the weak-lock we have first phase of 2PC? If that is the case, doesn't it break all the "new" strategy defended by @philbe paper? Can you elaborate more on that? Thanks |
|
Also:
That get back to my question on #3358. Are we introducing a new provider interface here? Or will it just be an enhanced version of current state storage provider ones? |
|
@galvesribeiro this introduces new interfaces, since simple small blob storage (like what we use for grain state) is not sufficient for storing transaction logs. |
|
@galvesribeiro, regarding timestamp-based concurrency control. Yes, this replaces two-phase locking for this first release. It's not optimistic. It just requires that operations on a grain execute in timestamp order, where the timestamp is assigned when the transaction begins. The mechanism rejects an operation on a grain with a small timestamp that would invalidate a previously executed operation on the grain with a larger timestamp. It doesn't break the new strategy. A transaction that modified a grain G and is in the midst of 2PC does not prevent a later transaction from operating on G in parallel with 2PC. In fact, there could be a sequence of such transactions that operate on G, if they execute fast enough and if 2PC is slow enough (due to the latency of the two write operations required by 2PC). |
|
Seems like this is going to rely on exceptionally accurate time-keeping, which more-or-less precludes too-distributed work on a given grain G (or subsets) across multiple machines. What kind of timestamp verification and vetting is going on to ensure that they're "correct" (or, at least, "correct in context") for parallel workloads? |
|
To stress the last comment, could you please describe the timestamp allocation process. I would assume it is done by the tx coordinator. Is there an RPC to the coordinator per tx? Or in batches? What happens when coordinator fails? How do u ensure timestamp order in case of coordinator failover? And finally, @philbe, can u please shed some light on the reason for the change? Did u get convinced it is more efficient in our context, or easier to implement? |
|
@volcimaster The accuracy of timekeeping has no effect on the correctness of timestamp-based concurrency control. However, it can affect performance. It is important that transaction timestamps are usually consistent with the order in which transactions are initiated in real-time (even across silos). For example, if a silo consistently assigns timestamps that are smaller than those assigned at other silos, then its transactions' updates on a given grain will frequently be rejected because another transaction with larger timestamp has already been executed. @gabikliot To address this issue, the cluster-wide transaction manager assigns timestamps. Communication from a silo's transaction agent to the central transaction manager (TM) is batched. The TM periodically persists a timestamp high-water mark that is an upper bound on any timestamp it assigns. If it fails and recovers, it starts assigning timestamps that exceed the previous high-water mark. RE: reason for the change. We had an implementation of the timestamp-based solution that was closer to production quality than our locking-based solution. We believe locking will perform better, and plan to incorporate it in the future. |
|
The latest PR "Minimal implementation of transaction orchestration #3382" should provide some insight into how the timestamps are managed. While conceptually the transactions need be ordered in time (by timestamp), what is critical to the algorithm is a consistent ordering, which is, in this initial implementation, provided by having a single authoritative source of transaction order, the Transaction Manager (TM). The TM assigns ordered transaction IDs to each transaction across the cluster and the order of these IDs acts as the timestamp. The single authoritative TM, while providing well ordered transactions, is both a bottleneck and a single point of failure. In the short term we're willing to accept these shortcomings to get the system up and running, but in the longer term we'll move away from a centralized transaction manager (as @philbe eluded to). See TransactionManager.cs |
|
Jason, I thought Phil wrote that consistent ordering is NOT critical for correctness, only for performance (to minimize aborts). That is how I thought about it too. The correctness is via 2pc. |
|
@philbe - you say, "accuracy of timekeeping has no effect on the correctness of timestamp-based concurrency control," then immediately follow it up with, "if a silo consistently assigns timestamps that are smaller than those assigned at other silos, then its transactions' updates on a given grain will frequently be rejected". This sounds like timestamping is vital: otherwise you're redoing work anytime a silo is noticeably behind on its timestamps. That's a problem. |
|
@gabikliot My comment was not intended as a contradiction of @philbe's assertions, only an explanation of how the initial implementation deals with ordering. In general, and especially in regards to transactions, if anything I say contradicts @philbe, the safe assumption is that I misspoke or am wrong. :) As for the overall properties of the general algorithms, I'll refrain from commenting as my core focus has been on correctness and performance of the initial implementation. |
That's one reason. Another is that operations on a contended grain will not necessarily execute in timestamp order, which creates needless aborts.
It degrades throughput. However, it's mitigated by the batched communication from each per-silo transaction agent to the transaction manager (TM). @voicimaster You're right that clock skew would be a problem if each silo independently assigned a timestamp to each transaction. However, in our implementation, the centralized TM is assigning timestamps (actually, sequentially-assigned transaction id's). A silo S would still be disadvantaged if it had sluggish communication with the TM, since it would be just like having S use a slow clock to timestamp transactions. But even in this case, throughput will be ok as long as S's transactions are only accessing lightly-contended grains. |
|
It is stated that "Grain Based Transaction Manager, backed by azure storage." is planned in scope of this feature. Is integration with SQL server also considered or will there be any means to implement one? |
|
@raufismayilov I believe this feature will evolve over time, so a provider model will make possible to implement different backends for TM state. |
|
@raufismayilov, @galvesribeiro, TM state storage is critical both to correctness and performance. We'll be placing an abstraction layer over the storage to allow for other implementations, but due to the critical nature of this component, it will likely be in flux for a bit longer. The current abstraction for this is Orleans.Transactions.Abstractions.ITransactionLogStorage, which is currently pluggable with only an in-memory version available, but we are already in the process of redesigning that. |
|
@jason-bragg good to know the abstractions are already in place. As usual, Azure storage will serve perfectly as a model for other backend implementations. Once it is done, others will come up soon I believe. :) |
|
|
|
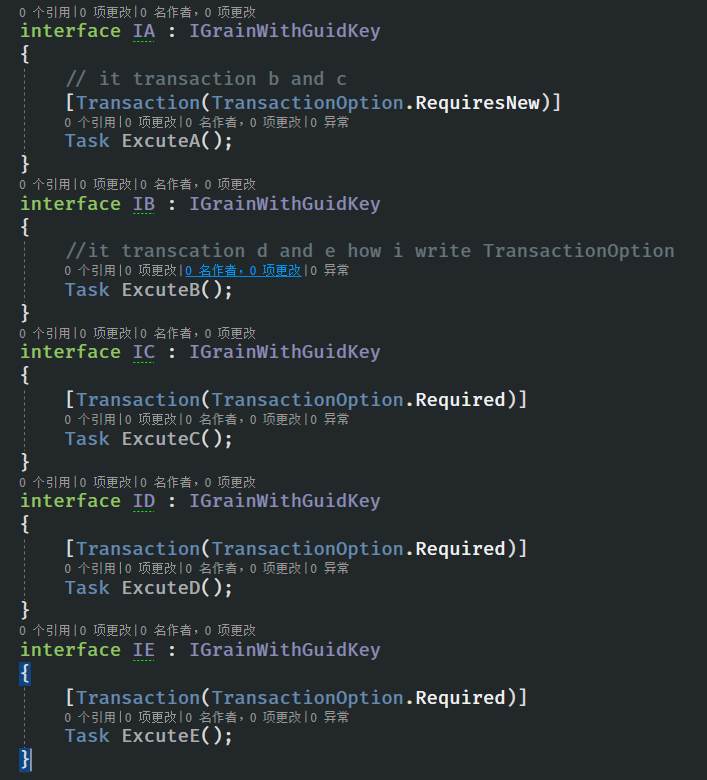
@zhaoqinghai i think default |
|
We are marking this issue as stale due to the lack of activity in the past six months. If there is no further activity within two weeks, this issue will be closed. You can always create a new issue based on the guidelines provided in our pinned announcement. |
|
This issue has been marked stale for the past 30 and is being closed due to lack of activity. |
Over the course of the next few weeks we’ll be introducing a series of code changes to make a Microsoft Research (MSR) developed implementation of Orleans Transactions publicly available. This initial version of Orleans Transactions is based off this paper from @philbe and Tamer Eldeeb, with the exception that it will use a timestamp based concurrency control instead of locking, and dependency injection (via the Facet System) instead of inheritance.
Related work:
Facet System - #3223
Orleans transaction core - #3358
Transaction Orchestration - #3382
Transactional State - #3397
Transaction manager tests - #3473
Reusable storage bridge - #3360
Orleans.Transactions.Azure - #3426
Simple account transfer transaction example - #3653
Upcoming:
Design Documentation
ITransactionalJournaledState Facet + testing
User Documentation
The text was updated successfully, but these errors were encountered: