




"Understanding Big Data" is a comprehensive and multifaceted field of study that focuses on the exploration, analysis, and management of extremely large and complex datasets. It is a critical area of knowledge in the modern era, where data is generated at an unprecedented scale and plays a central role in decision-making, research, and innovation across various industries and disciplines.
Big data refers to the vast and complex datasets characterized by their enormous volume, high velocity, and diverse variety. This data, often generated in real-time, includes structured, semi-structured, and unstructured information. Managing and deriving insights from big data require specialized technologies like Hadoop, Spark, and NoSQL databases, as well as machine learning algorithms. The impact of big data spans across industries, enabling data-driven decisions in business, advancements in healthcare, insights in finance, and innovations in research and smart city development. Understanding big data is essential as it underpins a data-centric world, shaping how we analyze, process, and leverage information for improved decision-making and innovation.
A. Defining Big Data
B. Characteristics of Big Data
C. Sources of Big Data
D. Challenges in Dealing with Big Data
The definition of big data is data that contains greater variety, arriving in increasing volumes and with more velocity. This is also known as the three Vs. Big data is a combination of unstructured, semi-structured or structured data collected by organizations. This data can be mined to gain insights and used in machine learning projects, predictive modeling and other advanced analytics applications.
Put simply, big data is larger, more complex data sets, especially from new data sources. These data sets are so voluminous that traditional data processing software just can’t manage them. But these massive volumes of data can be used to address business problems you wouldn’t have been able to tackle before.
According to Gartner (2012), Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
Big data can be used to improve operations, provide better customer service and create personalized marketing campaigns -- all of which increase value. As an example, big data can provide companies with valuable insights into their customers that can then be used to refine marketing techniques to increase customer engagement and Conversion rates. Big Data refers to large and complex datasets that surpass the capabilities of traditional data processing and analysis tools.
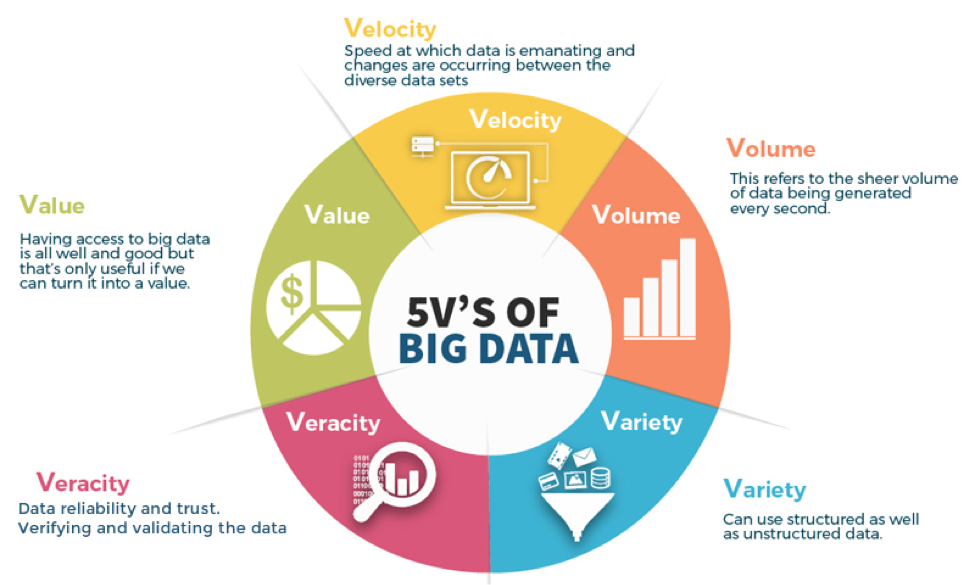
The characteristics of Big Data encapsulate the defining attributes of exceptionally large and complex datasets that have become a central component of our modern, data-driven world. These characteristics, often referred to as the "5 V's" (Volume, Velocity, Variety, Veracity, and Value).
- Definition: The "Volume" aspect of Big Data refers to the vast amount of data generated and collected. It typically involves datasets that are too large to be effectively managed and processed using traditional data management systems.
- Scale: Big Data is often measured in terms of terabytes, petabytes, exabytes, or even larger units of data storage.
- Sources: The sources of this voluminous data can vary widely and include social media interactions, sensor data, e-commerce transactions, and more.
- Importance: The sheer volume of data presents challenges in terms of storage, data transfer, and processing. Organizations need scalable and distributed storage solutions to handle such data.
- Definition: "Velocity" refers to the speed at which data is generated and the rate at which it flows into a system. Big Data often involves real-time data streams.
- Real-time Data: Examples of high-velocity data sources include social media updates, financial market transactions, and IoT sensors. The data arrives rapidly and continuously.
- Importance: Real-time or near-real-time processing of high-velocity data is crucial for making instant decisions, detecting anomalies, and reacting to changing conditions. It necessitates the use of specialized data streaming and processing tools.
- Definition: "Variety" refers to the diverse types of data that are part of the Big Data landscape. This data comes in various formats, including structured, semi-structured, and unstructured data.
- Structured Data: This includes data stored in traditional relational databases, with well-defined schemas, such as customer information, sales records, or financial data.
- Semi-Structured Data: Examples are data in formats like JSON or XML, which have some structure but are not as rigid as structured data.
- Unstructured Data: Unstructured data comprises text, images, videos, audio, and other types of data that lack a predefined structure.
- Importance: Managing and analyzing such diverse data is challenging. Big Data systems must be capable of handling and extracting valuable insights from structured and unstructured data sources.
- Definition: "Veracity" deals with the trustworthiness of the data. Big Data often contains noise, errors, and inconsistencies due to the diversity and volume of sources.
- Data Quality: Veracity is concerned with ensuring data quality and accuracy. High veracity data is trustworthy and reliable for analysis and decision-making.
- Importance: Dealing with data veracity involves data cleansing, data validation, and error detection methods to ensure that the insights derived from Big Data are meaningful and reliable.
- Definition: "Value" represents the ultimate goal of working with Big Data. It refers to the potential insights, knowledge, and economic value that can be derived from analyzing and extracting information from the data.
- Data Monetization: Organizations aim to generate value from Big Data through better decision-making, improved operations, new revenue streams, and cost savings.
- Importance: The value derived from Big Data is the driving force behind the investments made in Big Data Analytics. It can lead to competitive advantages, innovation, and better understanding of customer behavior.
Understanding these five Vs is essential for businesses and organizations to effectively harness the power of Big Data and leverage it for strategic decision-making, innovation, and growth.
In the modern era, the world is awash with an unprecedented amount of digital information, and this wealth of data has come to be known as "Big Data." These vast and complex datasets are generated from a multitude of sources, and they play a pivotal role in shaping how businesses, organizations, and researchers operate. The sources of Big Data are both diverse and expansive, representing the lifeblood of the digital age.
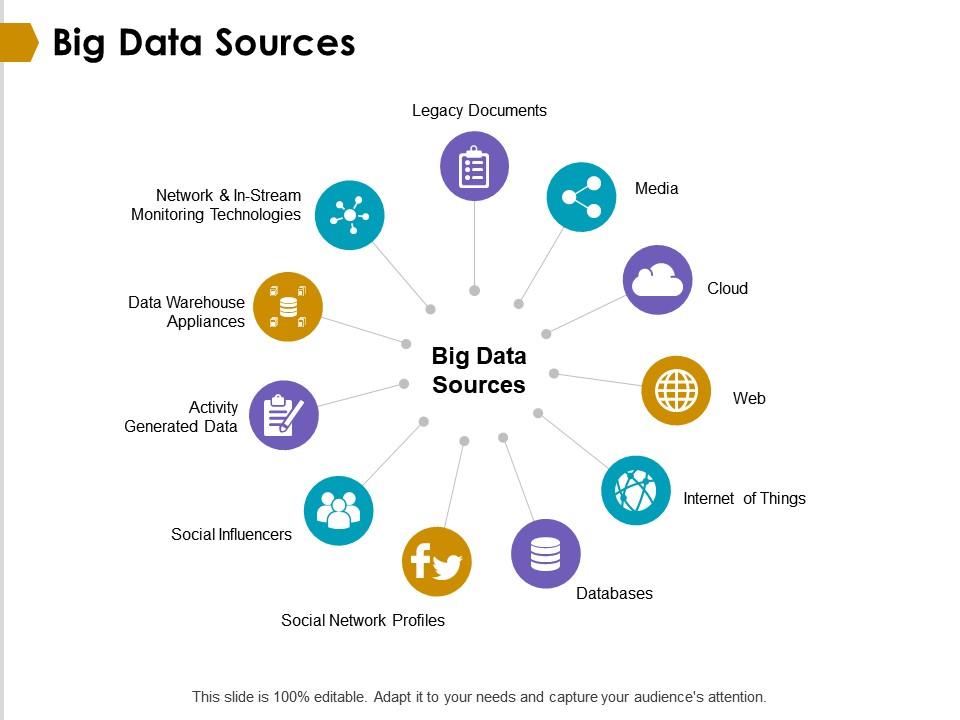
Big Data originates from various channels, including social media, the Internet of Things (IoT), websites, financial transactions, sensors, and much more. It encompasses structured data, such as traditional databases and spreadsheets, as well as unstructured data like text, images, and video. Understanding these sources and their characteristics is crucial for harnessing the potential of Big Data. Sources of Big Data:
-
Social Media: Platforms like Facebook, Twitter, Instagram, and LinkedIn generate vast amounts of data daily. This includes user-generated content, social connections, and user behavior data.
-
IoT Devices: The Internet of Things (IoT) comprises interconnected devices like smart sensors, wearable technology, and connected appliances. These devices generate real-time data, including temperature, location, health metrics, and more.
-
Websites and Online Content: Weblogs, online forums, and e-commerce sites continuously produce data, including user clicks, browsing behavior, and content interaction.
-
Transaction Data: Financial transactions, including credit card purchases, online banking, and e-commerce transactions, produce significant data volumes.
-
Sensors and Monitoring: Industrial sensors, weather stations, and environmental monitoring systems generate data related to temperature, humidity, air quality, and more.
-
Mobile Devices: Mobile phones and tablets generate data through GPS, app usage, call logs, and text messages.
-
Machine and Sensor Data: Machines and equipment in manufacturing and industrial settings produce data on performance, maintenance needs, and operational status.
-
Genomic Data: Advancements in genomics have led to the generation of large volumes of data related to DNA sequencing and genetic information.
-
Government and Public Records: Government agencies maintain databases containing data on demographics, public health, crime statistics, and more, which can contribute to Big Data.
-
Surveillance and Security Systems: Video surveillance cameras, facial recognition systems, and security cameras capture large amounts of data on movements and activities in public and private spaces.
-
Log Files: Servers, applications, and network devices generate log files that record events, errors, and activities, which can be valuable for troubleshooting and analysis.
-
Satellite and Remote Sensing: Remote sensing technologies like satellites and drones capture data related to Earth's surface, climate, and environmental changes.
-
Customer Feedback: Customer feedback from sources like surveys, reviews, and customer support interactions can provide valuable insights into customer preferences and satisfaction.
-
Biometric Data: Biometric systems collect data related to fingerprints, retina scans, and facial recognition for identity verification.
-
Scientific Research: Scientific experiments and simulations generate vast amounts of data in fields like physics, astronomy, and climate science.
-
Text and Documents: Unstructured text data from sources like books, articles, and legal documents can be analyzed to extract information and insights.
-
Audio and Video Data: Multimedia content from sources such as video streaming platforms, audio recordings, and podcasts contribute to the growing repository of Big Data.
-
Crowdsourced Data: Data collected from crowdsourcing platforms and citizen science initiatives often provides real-world information and opinions.
-
Healthcare Records: Electronic health records (EHRs), patient histories, and medical imaging data are integral to the healthcare sector's Big Data.
-
Financial Markets: Stock exchanges, trading platforms, and financial institutions generate vast datasets related to market activity, stock prices, and economic indicators.
These diverse sources collectively contribute to the ever-expanding pool of Big Data, and organizations across various sectors leverage these data sources to gain insights, make informed decisions, and create innovative solutions.
The sources of Big Data are continuously evolving and expanding, driven by advances in technology and the growing interconnectedness of our world. As data continues to proliferate, the ability to collect, manage, and analyze this information becomes an increasingly vital skill for businesses, governments, and individuals. Exploring the sources of Big Data provides valuable insights into the foundations of our data-driven society and the boundless opportunities it offers for innovation and decision-making.
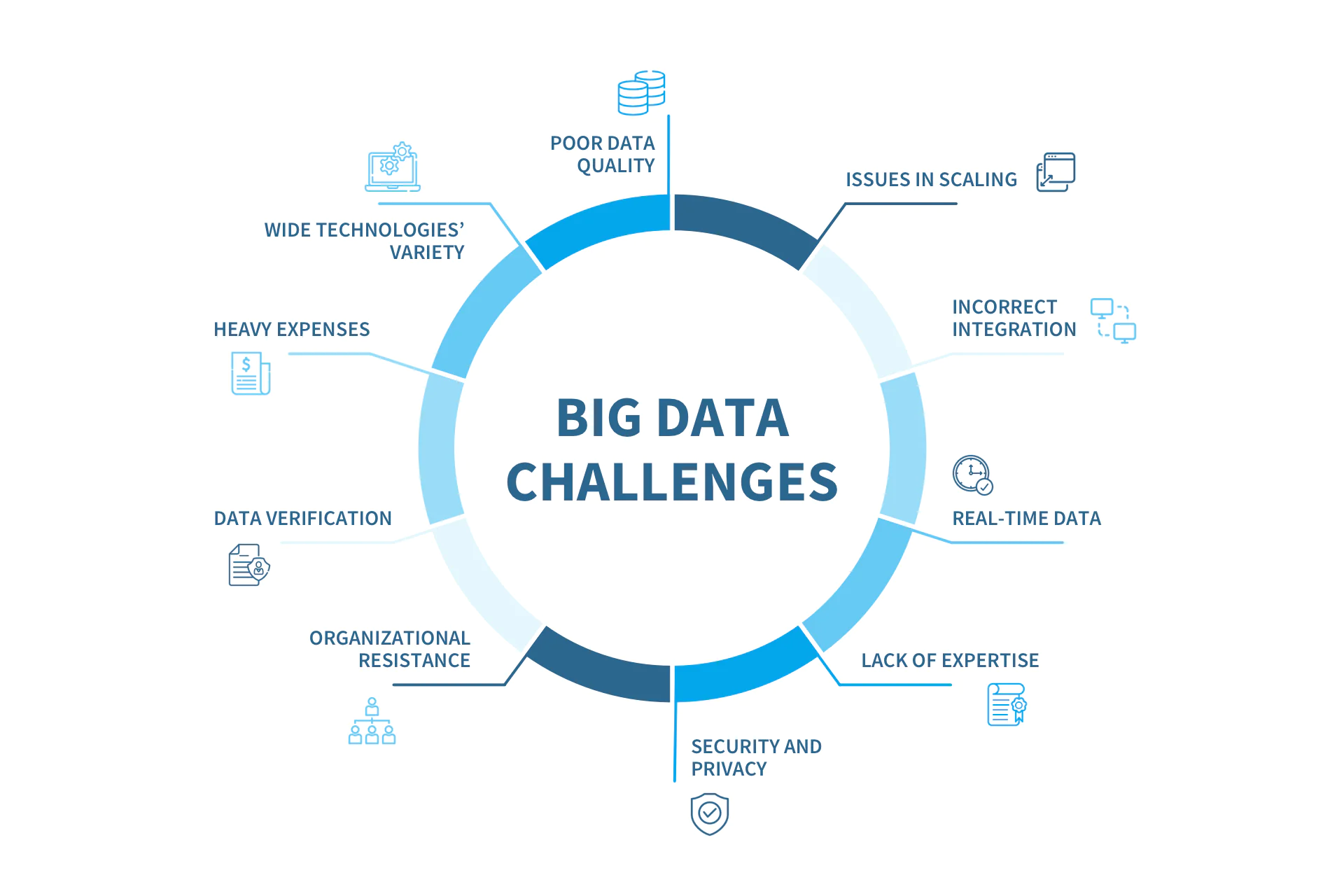
The challenges in dealing with Big Data are multifaceted and are not limited to the scale of the data alone. They encompass issues related to data quality, real-time processing, data security, and the need for advanced analytical techniques. Moreover, as data continues to grow exponentially, organizations and individuals must adapt to this new data landscape. Challenges:
-
Volume Overload: One of the most fundamental challenges with Big Data is its sheer volume. Storing, processing, and managing massive datasets can strain infrastructure and require significant investments in storage and computational resources.
-
Velocity: Big Data often arrives at high speeds and in real-time, as in the case of social media updates, sensor data, and financial transactions. Processing and analyzing data as it streams in can be demanding and require specialized tools.
-
Variety: Big Data encompasses various data types, including structured, unstructured, and semi-structured data. Managing this diversity is complex, as different data types require different processing and analysis techniques.
-
Veracity: Ensuring the accuracy and reliability of data in a Big Data environment is challenging. Data can be noisy, contain errors, or be inconsistent, making it essential to employ data quality measures and cleaning procedures.
-
Value Extraction: Despite the vast amount of data, deriving meaningful insights and value from Big Data is not guaranteed. Identifying relevant patterns and actionable information can be challenging, requiring advanced analytics and data science expertise.
-
Variability: Data can exhibit significant variations, such as seasonality or cyclical patterns. Handling these fluctuations and adapting to changing data patterns can be a complex task.
-
Complexity: Big Data is often intricate, featuring complex data structures and relationships. This complexity can make data processing, analysis, and interpretation demanding, necessitating sophisticated tools and algorithms.
-
Security and Privacy: Protecting Big Data from security breaches and maintaining data privacy is a critical concern. With the abundance of sensitive information, ensuring data security and compliance with privacy regulations is paramount.
-
Scalability: Big Data systems need to be scalable to accommodate data growth without compromising performance. Scaling infrastructure and algorithms to match data volume is a perpetual challenge.
-
Cost Management: The resources required to handle Big Data can be costly. Balancing the costs of data storage, processing, and analysis against the value gained from insights is a constant challenge.
-
Legal and Ethical Issues: Big Data often raises legal and ethical concerns, especially regarding data ownership, data usage, and compliance with data protection regulations. Organizations must navigate a complex legal landscape.
-
Data Integration: Big Data often originates from a variety of sources and systems. Integrating and reconciling data from these diverse sources can be technically challenging.
-
Skill Gap: Finding professionals with the expertise to work with Big Data, including data scientists and analysts, can be difficult, as the skills required are in high demand.
Dealing with Big Data requires a combination of advanced technologies, data management strategies, and a deep understanding of the unique challenges it presents. Success in the era of Big Data depends on organizations' ability to effectively tackle these challenges while extracting valuable insights and making data-driven decisions.

The workflow of Big Data Management involves a structured process of data ingestion, storage, processing, integration, analysis, visualization, security, scalability, governance, and real-time processing. It begins with the collection of data from various sources, followed by storage in distributed systems or cloud-based platforms. Data is then pre-processed and integrated to create a unified dataset. Analysis and visualization tools are applied to extract insights and present them visually. Data security, scalability, and governance ensure data is handled responsibly and compliant with regulations. In some cases, real-time processing is used for immediate decision-making. This comprehensive workflow empowers organizations to make informed decisions, enhance operational efficiency, and gain a competitive edge through data-driven insights.

The workflow of Big Data Management typically encompasses several key stages:
-
Data Ingestion: The process begins with data ingestion, where raw data is collected from various sources such as databases, sensors, logs, social media, and more. This data can be structured, semi-structured, or unstructured, and it needs to be brought into a central repository for further processing.
-
Data Storage: Once collected, the data is stored in a suitable storage system. Traditional relational databases may not be sufficient for big data, so organizations often opt for distributed storage solutions like Hadoop HDFS or cloud-based storage services, ensuring scalability and cost-effectiveness.
-
Data Processing: In this stage, data is pre-processed, cleaned, and transformed to make it suitable for analysis. This may involve data cleansing, data enrichment, and formatting to ensure data quality and consistency.
-
Data Integration: Big data often comes from diverse sources, and integrating this data is crucial to create a unified view. Data integration techniques are applied to combine data from different systems or sources, providing a comprehensive dataset for analysis.
-
Data Analysis: The heart of Big Data Management involves data analysis, where powerful tools and technologies are used to extract insights. This can encompass descriptive analytics to understand historical trends, predictive analytics to forecast future events, and prescriptive analytics to suggest actions based on data patterns.
-
Data Visualization: Visualizing the results of data analysis is essential for making the insights more understandable and actionable. Data visualization tools help in creating charts, graphs, and dashboards that convey the information effectively to decision-makers.
-
Data Security and Privacy: Protecting data is paramount, especially when dealing with sensitive information. Data security measures, encryption, and access controls are implemented to ensure data confidentiality and compliance with data privacy regulations.
-
Scalability: As data continues to grow, scalability is essential. The system should be capable of handling increasing data volumes without significant performance degradation or costly overhauls.
-
Data Governance: Effective data governance is established to ensure data is used responsibly, ethically, and in compliance with relevant laws and regulations. This includes defining data ownership, data quality standards, and maintaining data catalogs.
-
Real-time Data Processing: In certain use cases, real-time data processing is necessary for immediate decision-making. Technologies like Apache Kafka and stream processing platforms allow data to be processed and analyzed in real-time.
-
Cost Optimization: Managing the costs associated with big data infrastructure and tools is a critical consideration. Organizations need to balance performance requirements with cost-efficiency, often leveraging cloud-based solutions for cost optimization.
-
Data Monetization: Some organizations choose to monetize their data by selling it to other businesses, sharing it with partners, or using it to create new data-based products and services.
In conclusion, the workflow of Big Data Management involves a series of interconnected stages that transform raw data into valuable insights, ensuring data quality, security, and compliance along the way. It plays a pivotal role in helping organizations make informed decisions, improve operational efficiency, innovate, and gain a competitive edge in the era of big data.
Please create an Issue for any improvements, suggestions or errors in the content.
You can also contact me using Linkedin for any other queries or feedback.