About metric learning output embedding #4
Comments
|
这个问题我们也没有确切的答案,在一定范围内应该都是合理的。我们的一个经验是对于分布复杂的数据用高一些的维度可能更有利,对于分布简单的数据则不需要 |
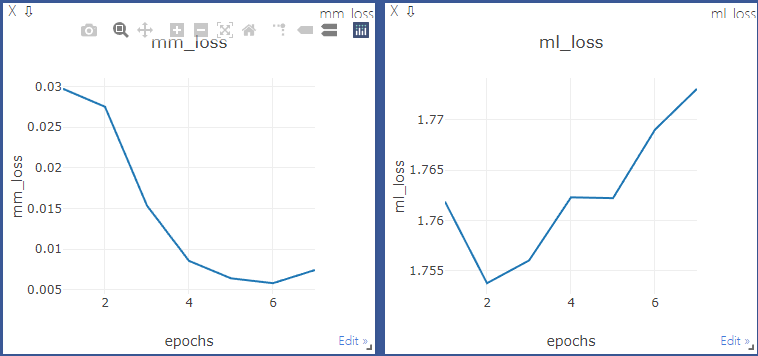
好的,感谢。另外,使用MVM进行训练,流行匹配的loss是下降的,度量学习部分的loss呈上升趋势,这是否意味着训练失败了? |
|
训练稳定的话mm_loss的确在下降,ml_loss在一定区间内振荡,如果不是的话训练可能就失败了,不过这是稳定训练的必要条件不是充分条件 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
作者您好,论文中您在Unconditional Image Generation和Single Image Super-Resolution这两个任务上为netML设置了不同的output embedding(分别为10和32),如何根据自己的任务来选择合适的output embedding呢?比如Image-to-Image translation这样的任务。
The text was updated successfully, but these errors were encountered: