Timeout handling #472
Comments
|
I'm not sure, what you assume that timeout should be related. |
|
I'm interested if the notify from the server is acknowledged by the client, to check if the client still is connected properly. Also i'm interested in handling reconnection on the client side. If a client observes a resource, and e.g the server crashes and restarts, the client will no longer get updates from the server. In the case the server doesnt notify the clients in a given time, i'd like to check if the server is still available, otherwise i want to try to request a new observation until the server is available again |
|
For the coap-server (the observed): if either the count or the time is reached, the coap-server uses a CON notify to check, if the coap-client is still interested. For the coap-client (the observer): |
Is there any method which will get invoked after the notify gets canceld? I want to handle those disconnects but I only get a console output :
On the client the onError() on the CoapObserveRelation gets invoked, but it takes up to 2 min and doesnt result in a reconnect. Where do i have to set MAX_AGE to to speed up the invocation? |
Have a look at
OK, if that gets invoked, then you not using a commit from our repository! Or which commit you are using, that provides a
I'm not sure, what you mean. Why should a "onError" (assuming you mean |
Thanks, that's what i was looking for.
yes, my fault
Assuming a server, which a client is connected to, loses its connection and is offline for a longer period (eg. 5 min). The client should recognize such a server-side disconnect immediately and then try to reconnect to the server until it is back again. |
So, your coap-client was observing some resource on a coap-server. If you want to do retries in that case, just trigger that retry in the "onError()". I'm not sure, what pattern would match you situation best, but I hope you know it and therefore you could implement your proper retry strategy. Californium only implements the very basic (and safe) functionality for that. |
I wanted to that, but it takes to much time for the onError() to be invoked (up to 10 minutes). Is there a way to speed up this invokation by configuring the coap-client? Thanks in advance |
|
Sorry, it's time, that you provide some wireshark and californium logs, where we can see what happens :-). |
|
Thanks for your patience !! Here is my CoAP Server Thats the console output: Thats the wireshark log: As you can see from the console and the wirkeshark logs, the client starts the first reconnect attempt after about 17 min. |
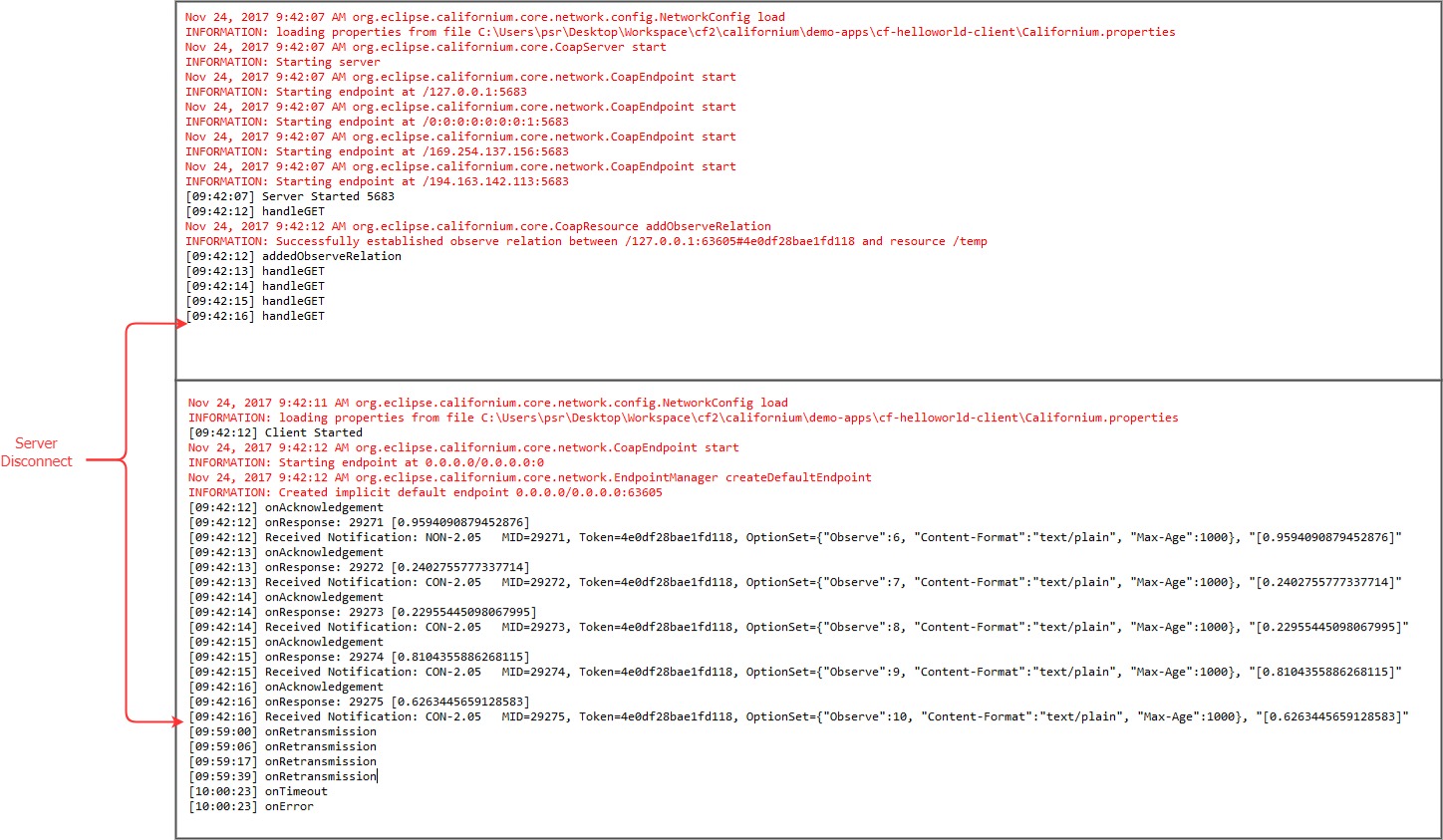

|
@philib Please read this comment: |
|
So some more details about the timings. RFC7641, 3.3.1, page 11:
Because of the recommendation at the end, the client waits for that MAX-AGE until it re-registers (in your log For the most communication technique, the only possibility to check "aliveness" is to exchange messages. Some technique does this with the protocol, others outside of that protocol. If you need shorter detection times, then you may design your communication using notifies more frequently. If you send such a notify every 30s (and adjust the MAX_AGE accordingly), you may detect faster, that the server is down. Sure, at the cost of more traffic. So you must find the best trade-off between detection time and traffic for your application. |
|
Do you still have issues related with the timeout handling? |
Thanks a lot, reducing the MAX_AGE serverside solved the problem 👍 |
Hey,
is there a possibility to subscribe on timeout events on the server side?
I want to register if a ACK package is send as a response to an observation from the client or not.
Thanks in advance,
Philip
The text was updated successfully, but these errors were encountered: