请问Context Features中的Word + Character + Ngram是什么意思? #22
Comments
|
是word的unigram和bigram以及character的unigram,因为中文的词一般就是两三个字所以用character的ngram和词没什么区别了。 |
|
@shenshen-hungry 好的谢谢,那么再问一下。context feature中word和word+character的区别,是在分词后,前者去掉了分词结果为单个字的情况嘛? |
|
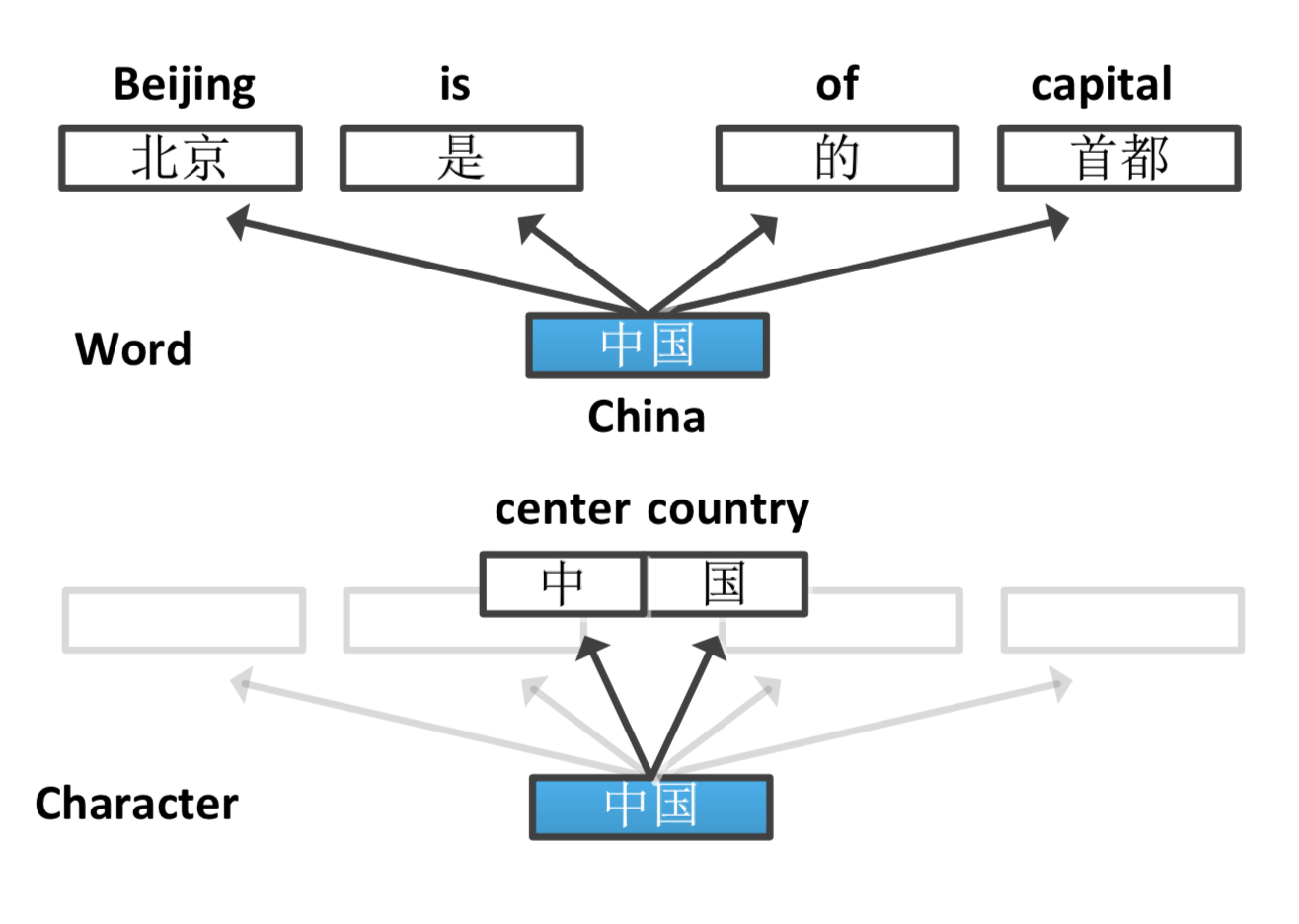
word就是分词意义上的词,word+character是说不但有词还有字。也就是在Skip-gram模型中,中心词不但预测上下文中的词,同时也预测里面的字。 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
这个ngram,是指考虑了word的ngram,还是character的ngram呢?可是常出现的character的ngram,不就是word了吗?不是很理解这个context features是怎么考虑的。求解答,谢谢!
The text was updated successfully, but these errors were encountered: