This is my note for os interview. It recaps the os basics and would be extremely helpful if you are going to take an interview tomorrow but forget what you learnt in college (that's why I make this note!).
reference:
- uic Jbell's Coursenote
- Umich EECS 482 Winter 2021 - Manos Kapritsos, Peter Chen, Harsha Madhyastha
- wikipedia
- umass cmpsci377 Coursenote
A process is a program in execution. To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program.
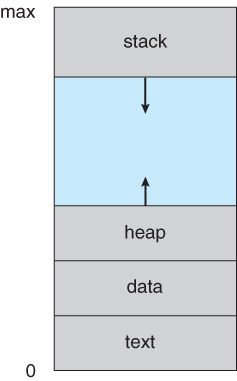
When a program is loaded into the memory and it becomes a process, it can be divided into four sections:
- Stack: the temporary data such as method/function parameters, return address and local variables.
- Heap: dynamically allocated memory to a process during its run time.
- Text: the compiled program code, read in from non-volatile storage when the program is launched.
- Data: global and static variables, allocated and initialized prior to executing main.
A process contains:
- Set of threads
- A process address space: the memory used by the program as it runs, which contains:
- code and input data
- memory allocated
- open files and network connections
- stack for each thread, encapsulating the state of procedure calls
- program counter (PC) for each thread, indicating the next instruction
- A set of general-purpose registers for each thread
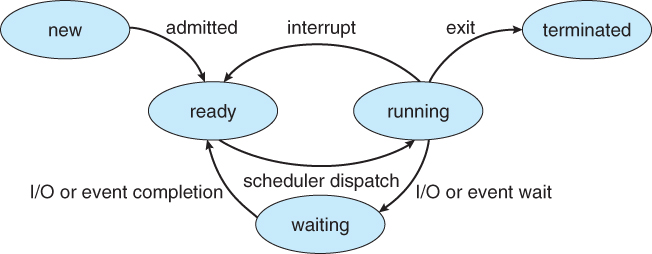
Processes should be in one of 5 states:
- New - The process is in the stage of being created.
- Ready - The process has all the resources available that it needs to run, but the CPU is not currently working on this process's instructions.
- Running - The CPU is working on this process's instructions.
- Waiting - The process cannot run at the moment, because it is waiting for some resource to become available or for some event to occur. For example the process may be waiting for keyboard input, disk access request, inter-process messages, a timer to go off, or a child process to finish.
- Terminated - The process has completed.
For each process there is a Process Control Block (PCB), which stores the following information:
- Process State
- Process ID, and parent process ID.
- Set of registers - register set where process needs to be stored for execution for running state. One for each thread.
- Program Counter (PC) - a pointer to the address of the next instruction to be executed for this process. One for each thread.
- CPU Scheduling information - Such as priority information and pointers to scheduling queues.
- Memory Management information - page/segment table and memory limits
- Accounting information - user and kernel CPU time consumed, account numbers, limits, etc.
- I/O Status information - list of I/O devices allocated to the process.
The two main objectives of the process scheduling system are to keep the CPU busy at all times and to deliver "acceptable" response times for all programs.
- All processes are stored in the job queue.
- Processes in the Ready state are placed in the ready queue.
- Processes waiting for a device to become available or to deliver data are placed in device queues. There is generally a separate device queue for each device.
- Other queues may also be created and used as needed.
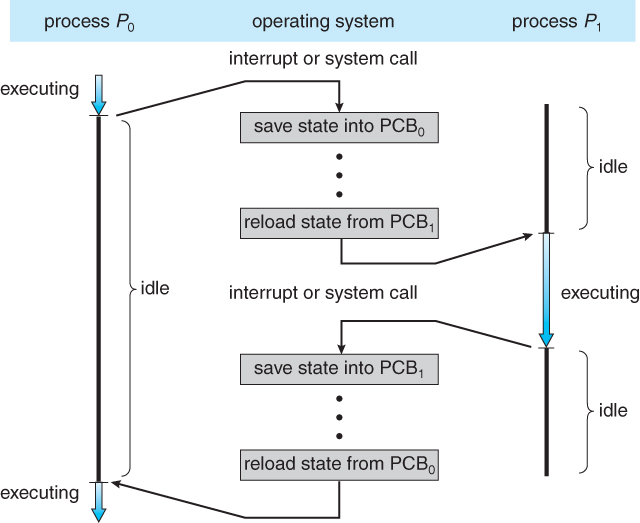
a context switch is the process of storing the state of a process or thread, so that it can be restored and resume execution at a later point, and then restoring a different, previously saved, state.
WHEN?
Most commonly, one process must be switched out of the CPU so another process can run. This context switch can be triggered by the process making itself unrunnable, such as by waiting for an I/O or synchronization operation to complete.
On a pre-emptive multitasking system, the scheduler may also switch out processes that are still runnable. To prevent other processes from being starved of CPU time, pre-emptive schedulers often configure a timer interrupt to fire when a process exceeds its time slice. This interrupt ensures that the scheduler will gain control to perform a context switch.
Context switching happens VERY frequently
HOW?
In the Linux kernel, context switching involves loading the corresponding process control block (PCB) stored in the PCB table in the kernel stack to retrieve information about the state of the new process. CPU state information including the registers, stack pointer, and program counter as well as memory management information like segmentation tables and page tables (unless the old process shares the memory with the new) are loaded from the PCB for the new process.
- Processes may create other processes through appropriate system calls, such as
forkorspawn. The process which does the creating is termed the parent of the other process, which is termed its child. - In the parent process,
fork()returns the pid of the child. In the child process,fork()returns 0, which is not the pid of anything, it's just a marker. - Each process is given an integer identifier, termed its process identifier, or PID. The parent PID (PPID) is also stored for each process.
- On UNIX systems, the process scheduler is termed sched, and is given PID 0. The first thing it does at system startup time is to launch init, which gives that process PID 1. Init then launches all system daemons and user logins, and becomes the ultimate parent of all other processes.
There are two options for the parent process after creating the child:
- Wait for the child process to terminate before proceeding. The parent makes a
wait()system call, for either a specific child or for any child, which causes the parent process to block until thewait()returns. UNIX shells normally wait for their children to complete before issuing a new prompt. - Run concurrently with the child, continuing to process without waiting. This is the operation seen when a UNIX shell runs a process as a background task. It is also possible for the parent to run for a while, and then wait for the child later, which might occur in a sort of a parallel processing operation. (E.g. the parent may fork off a number of children without waiting for any of them, then do a little work of its own, and then wait for the children.)
Two possibilities for the address space of the child relative to the parent:
- The child may be an exact duplicate of the parent, sharing the same program and data segments in memory. Each will have their own PCB, including program counter, registers, and PID. This is the behavior of the
forksystem call in UNIX. - The child process may have a new program loaded into its address space, with all new code and data segments. This is the behavior of the
spawnsystem calls in Windows. UNIX systems implement this as a second step, using theexecsystem call.
Figure below shows the fork and exec process on a UNIX system. Note that the fork system call returns the PID of the processes child to each process - It returns a zero to the child process and a non-zero child PID to the parent, so the return value indicates which process is which. Process IDs can be looked up any time for the current process or its direct parent using the getpid() and getppid() system calls respectively.


Processes may request their own termination by making the exit() system call, typically returning an int. This int is passed along to the parent if parent is doing a wait(), and is typically zero on successful completion and some non-zero code in the event of problems.
Processes may also be terminated by the system for a variety of reasons, including:
- The inability of the system to deliver necessary system resources.
- In response to a KILL command, or other un handled process interrupt.
- A parent may kill its children if the task assigned to them is no longer needed.
- If the parent exits, the system may or may not allow the child to continue without a parent.
When a process terminates, all of its system resources are freed up, open files flushed and closed, etc. The process termination status and execution times are returned to the parent if the parent is waiting for the child to terminate, or eventually returned to init if the process becomes an orphan.
A zombie process is a process that has completed execution (via the exit system call) but still has an entry in the process table. The cause of zombie process: the parent is not waiting for child process, i.e., doesn't pick up the child's exit code.
An orphan process is a process that is still executing, but whose parent has died. When the parent dies, the orphaned child process is adopted by init (process ID 1).
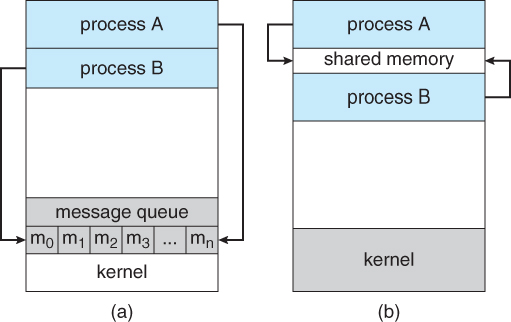
Communications models: (a) Message passing. (b) Shared memory.
- Multiple processes are given access to the same block of memory, which creates a shared buffer for the processes to communicate with each other.
- Shared memory is generally preferable when large amounts of information must be shared quickly on the same computer.
- Message passing systems must support at a minimum system calls for "send message" and "receive message".
- Either the sending or receiving of messages (or neither or both) may be either blocking or non-blocking.
- Messages are passed via queues
- Message Passing requires system calls for every message transfer, and is therefore slower, but it is simpler to set up and works well across multiple computers. Message passing is generally preferable when the amount and/or frequency of data transfers is small, or when multiple computers are involved.
- A socket is an endpoint for communication.
- Two processes communicating over a network often use a pair of connected sockets as a communication channel. Software that is designed for client-server operation may also use sockets for communication between two processes running on the same computer - For example the UI for a database program may communicate with the back-end database manager using sockets. (If the program were developed this way from the beginning, it makes it very easy to port it from a single-computer system to a networked application.)
- A socket is identified by an IP address concatenated with a port number
Communication channels via sockets may be of one of two major forms:
- Connection-oriented (TCP, Transmission Control Protocol) connections emulate a telephone connection. All packets sent down the connection are guaranteed to arrive in good condition at the other end, and to be delivered to the receiving process in the order in which they were sent. The TCP layer of the network protocol takes steps to verify all packets sent, re-send packets if necessary, and arrange the received packets in the proper order before delivering them to the receiving process. There is a certain amount of overhead involved in this procedure, and if one packet is missing or delayed, then any packets which follow will have to wait until the errant packet is delivered before they can continue their journey.
- Connectionless (UDP, User Datagram Protocol) emulate individual telegrams. There is no guarantee that any particular packet will get through undamaged, and no guarantee that the packets will get delivered in any particular order. There may even be duplicate packets delivered, depending on how the intermediary connections are configured. UDP transmissions are much faster than TCP, but applications must implement their own error checking and recovery procedures.
Sockets are considered a low-level communications channel, and processes may often choose to use something at a higher level, such as those covered in the next two sections.
The general concept of RPC is to make procedure calls similarly to calling on ordinary local procedures, except the procedure being called lies on a remote machine.
Implementation involves stubs on either end of the connection.
- The local process calls on the stub, much as it would call upon a local procedure.
- The RPC system packages up (marshals) the parameters to the procedure call, and transmits them to the remote system.
- On the remote side, the RPC daemon accepts the parameters and calls upon the appropriate remote procedure to perform the requested work.
- Any results to be returned are then packaged up and sent back by the RPC system to the local system, which then unpackages them and returns the results to the local calling procedure.
Pipes are one of the earliest and simplest channels of communications between (UNIX) processes.
- A thread is a basic unit of CPU utilization, consisting of a program counter, a stack, a set of registers, and a thread ID.
- Traditional (heavyweight) processes have a single thread of control - There is one program counter, and one sequence of instructions that can be carried out at any given time.
- As shown below, multi-threaded applications have multiple threads within a single process, each having their own program counter, stack and set of registers, but sharing common code, data, and certain structures such as open files.
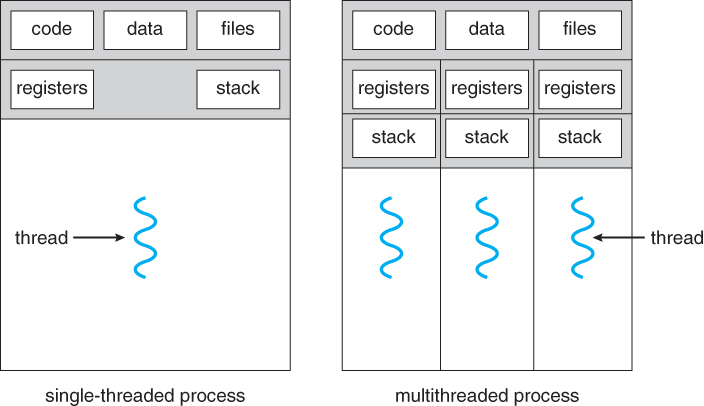
Example: web server - Multiple threads allow for multiple requests to be satisfied simultaneously, without having to service requests sequentially or to fork off separate processes for every incoming request. (The latter is how this sort of thing was done before the concept of threads was developed. A daemon would listen at a port, fork off a child for every incoming request to be processed, and then go back to listening to the port.)
Benefits of multi-threading:
- Responsiveness - One thread may provide rapid response while other threads are blocked or slowed down doing intensive calculations.
- Resource sharing - By default threads share common code, data, and other resources, which allows multiple tasks to be performed simultaneously in a single address space.
- Economy - Creating and managing threads (and context switches between them) is much faster than performing the same tasks for processes.
- Scalability, i.e. Utilization of multiprocessor architectures - A single threaded process can only run on one CPU, no matter how many may be available, whereas the execution of a multi-threaded application may be split amongst available processors. (Note that single threaded processes can still benefit from multi-processor architectures when there are multiple processes contending for the CPU, i.e. when the load average is above some certain threshold.)
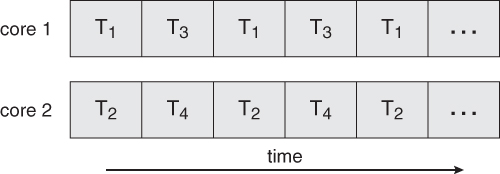
A multi-threaded application running on a single-core chip would have to interleave the threads, as shown below:

On a multi-core chip, the threads could be spread across the available cores, allowing true parallel processing, as shown below:
Thread "context" is stored in thread control block (TCB) when the thread isn't running, which contains:
- Thread ID
- program counter
- stack pointer
- general purpose registers' values
- Pointer to the PCB of the process that the thread lives on
Note that code are shared across threads in a process, and every thread needs a program counter to know the next instruction.
A thread should be in one of three states:
- Running state: Running on CPU
- Ready state: TCB is in ready queue
- Blocked state: TCB is in waiting queue
Steps in switching threads:
- Current thread return control to OS
- OS choose new thread to run
- OS saves state of current thread from CPU to its TCB
- OS loads context of next thread from its TCB
- OS runs next thread
How does thread return control back to OS?
- internal events
- Thread calls
wait(),lock(), etc. - Thread requests OS to do some work (e.g., I/O)
- Thread voluntarily gives up CPU with
yield()
- Thread calls
- extrenal events
- Interrupts
- Creating new threads every time one is needed and then deleting it when it is done can be inefficient, and can also lead to a very large unlimited number of threads being created.
- An alternative solution is to create a number of threads when the process first starts, and put those threads into a thread pool.
- Threads are allocated from the pool as needed, and returned to the pool when no longer needed.
- When no threads are available in the pool, the process may have to wait until one becomes available.
- The maximum number of threads available in a thread pool may be determined by adjustable parameters, possibly dynamically in response to changing system loads.
- Win32 provides thread pools through the "PoolFunction" function. Java also provides support for thread pools through the java.util.concurrent package
- UNIX provides two separate system calls,
kill(pid, signal)andpthread_kill(tid, signal), for delivering signals to processes or specific threads respectively. - Linux does not distinguish between processes and threads - It uses the more generic term "tasks". The traditional
fork()system call completely duplicates a process (task), as described earlier.
- Mutual Exclusion: Only one process at a time can be executing in their critical section.
- Critical Section: In concurrent programming, concurrent accesses to shared resources can lead to unexpected or erroneous behavior, so parts of the program where the shared resource is accessed need to be protected in ways that avoid the concurrent access. One way to do so is known as a critical section. This protected section cannot be entered by more than one process or thread at a time; others are suspended until the first leaves the critical section.
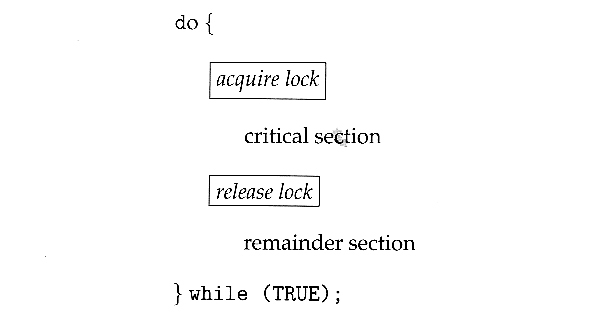
- Most systems offer a software API equivalent called mutexes. (For mutual exclusion)
- The terminology when using mutexes is to acquire a lock prior to entering a critical section, and to release it when exiting, as shown below:
- The acquire step will block the process if the lock is in use by another process, and both the acquire and release operations are atomic.
- Acquire and release can be implemented as shown here, based on a boolean variable "available":
acquire() {
while (!available); /* busy wait */
available = false;
}
release() {
available = true;
}- One problem with the implementation shown here, is the busy loop used to block processes in the acquire phase. These types of locks are referred to as spinlocks, because the CPU just sits and spins while blocking the process.
- Spinlocks are wasteful of cpu cycles, and are a really bad idea on single-cpu single-threaded machines, because the spinlock blocks the entire computer, and doesn't allow any other process to release the lock. (Until the scheduler kicks the spinning process off of the cpu)
- On the other hand, spinlocks do not incur the overhead of a context switch, so they are effectively used on multi-threaded machines when it is expected that the lock will be released after a short time.
- An alternative implementation is to block the process rather than spin waiting. I skip the pseudocode here, but you can refer to the blocking implementation in Semaphore section.
- Semaphore is a more robust synchronization mechanism that is used to control access to shared resources.
- It maintains a integer count of available resources and provides two atomic operations:
wait()andsignal(). The counter allows it to control access to a finite pool of resources.
The following is an implementation of semaphore:
wait(S) {
while (S<=0);
S--;
}
signal(S) {
S++;
}- Counting semaphore can take on any integer value, and are usually used to count the number remaining of some limited resource.
- Binary semaphore is used if there is only one count of a resource. It can only have the values of 0 or 1. They are often used as mutex locks. Here is an implementation of mutual-exclusion using binary semaphores:
while (1)
{
wait(s);
/*
critical section
*/
signal(s);
/*
remainder section
*/
}- The problem of the implementation described above is the busy loop in the
waitcall, which consumes CPU cycles without doing any useful work. This type of lock is known as a spinlock. As we mentioned in mutex section, spinlock does have the advantage of not invoking context switches. - An alternative approach is to block a process when it is forced to wait for an available semaphore, and swap it out of the CPU. In this implementation each semaphore needs to maintain a list of processes that are blocked waiting for it, so that one of the processes can be woken up and swapped back in when the semaphore becomes available. (Whether it gets swapped back into the CPU immediately or whether it needs to hang out in the ready queue for a while is a scheduling problem.) The new definition of a semaphore and the corresponding
waitandsignaloperations are shown as follows:

Note that in this implementation, the value of the semaphore can become negative, in which case its magnitude is the number of processes waiting for that semaphore.
TODO
Deadlock is a situation where a set of processes are blocked as each process is holding resources and waits to acquire resources held by another process. This leads to infinite waiting.
4 necessary conditions of deadlock:
- Mutual Exclusion: A resource can be held by only one process at a time
- Hold and Wait: A process can hold a number of resources at a time and at the same time, it can request for other resources that are being held by some other process.
- No preemption: A resource can't be preempted from the process by another process, forcefully. For example, if a process P1 is using some resource R, then some other process P2 can't forcefully take that resource.
- Circular Wait: Circular wait is a condition when the first process is waiting for the resource held by the second process, the second process is waiting for the resource held by the third process, and so on. At last, the last process is waiting for the resource held by the first process.
Starvation is an outcome of a process that is unable to gain regular access to the shared resources it requires to complete a task and thus, unable to make any progress.
- Starvation is usually caused by an overly simplistic scheduling algorithm. For example, if a poorly designed multi-tasking system always switches between the first two tasks while a third never gets to run, then the third task is being starved of CPU time.
- How to avoid? use a resource scheduling algorithm with the aging technique, which gradually increasing the priority of processes that wait in the system for a long time.
- Also called as producer consumer problem.
- There is a buffer of n slots and each slot is capable of storing one unit of data. There are two processes running, namely, producer and consumer, which are operating on the buffer.
- A producer tries to insert data into an empty slot of the buffer. A consumer tries to remove data from a filled slot in the buffer. As you might have guessed by now, those two processes won't produce the expected output if they are being executed concurrently.
- There needs to be a way to make the producer and consumer work in an independent manner.
One solution of this problem is to use semaphores. The semaphores which will be used here are:
mutex, a binary semaphore which is used to acquire and release the lock.empty, a counting semaphore whose initial value is the number of slots in the buffer, since, initially all slots are empty.full, a counting semaphore whose initial value is 0.
pseudocode of the producer function:
do
{
// wait until empty > 0 and then decrement 'empty'
wait(empty);
// acquire lock
wait(mutex);
/* perform the insert operation in a slot */
// release lock
signal(mutex);
// increment 'full'
signal(full);
}
while(TRUE)pseudocode for the consumer function:
do
{
// wait until full > 0 and then decrement 'full'
wait(full);
// acquire the lock
wait(mutex);
/* perform the remove operation in a slot */
// release the lock
signal(mutex);
// increment 'empty'
signal(empty);
}
while(TRUE);- It deal with situations in which many concurrent threads of execution try to access the same shared resource at one time.
- Some threads may read and some may write, with the constraint that no thread may access the shared resource for either reading or writing while another thread is in the act of writing to it. (In particular, we want to prevent more than one thread modifying the shared resource simultaneously and allow for two or more readers to access the shared resource at the same time). A readers-writer lock is a data structure that solves one or more of the readers–writers problems.
- There are three variations of the problems.
The first readers-writers problem gives priority to readers. In this problem, if a reader wants access to the data, and there is not already a writer accessing it, then access is granted to the reader.
The solution:
semaphore resource=1;
semaphore rmutex=1;
readcount=0;
/*
resource.P() is equivalent to wait(resource)
resource.V() is equivalent to signal(resource)
rmutex.P() is equivalent to wait(rmutex)
rmutex.V() is equivalent to signal(rmutex)
*/
writer() {
resource.P(); //Lock the shared file for a writer
<CRITICAL Section>
// Writing is done
<EXIT CRITICAL Section>
resource.V(); //Release the shared file for use by other readers. Writers are allowed if there are no readers requesting it.
}
reader() {
rmutex.P(); //Ensure that no other reader can execute the <Entry> section while you are in it
<CRITICAL Section>
readcount++; //Indicate that you are a reader trying to enter the Critical Section
if (readcount == 1) //Checks if you are the first reader trying to enter CS
resource.P(); //If you are the first reader, lock the resource from writers. Resource stays reserved for subsequent readers
<EXIT CRITICAL Section>
rmutex.V(); //Release
// Do the Reading
rmutex.P(); //Ensure that no other reader can execute the <Exit> section while you are in it
<CRITICAL Section>
readcount--; //Indicate that you no longer need the shared resource. One fewer reader
if (readcount == 0) //Checks if you are the last (only) reader who is reading the shared file
resource.V(); //If you are last reader, then you can unlock the resource. This makes it available to writers.
<EXIT CRITICAL Section>
rmutex.V(); //Release
}Note that this can lead to starvation of the writers and does not satisfy fairness, which is the motivation for the second readers–writers problem.
- The second readers-writers problem gives priority to the writers. In this problem, when a writer wants access to the data it jumps to the head of the queue - All waiting readers are blocked, and the writer gets access to the data as soon as it becomes available. In this solution the readers may be starved by a steady stream of writers.
If you want to view the solution or Third readers–writers problem, go to this wikipedia
- The dining philosophers problem is a classic synchronization problem involving the allocation of limited resources amongst a group of processes in a deadlock-free and starvation-free manner
- 5 philosophers sit at a round table. There is exactly one chopstick between each pair of dining philosophers.
- These philosophers spend their lives alternating between two activities: eating and thinking.
- Each philosopher needs 2 chopsticks to eat.
- When a philosopher thinks, it puts down both chopsticks in their original locations.
An intuitive solution is to use five semaphores, and to have each hungry philosopher first wait on their left chopstick, and then wait on their right chopstick. However, this can result deadlock.
Some potential solutions:
- Only allow n-1 (if n=5, then 4) philosophers to dine at the same time. (Limited simultaneous processes) (deadlock-free)
- Use an asymmetric solution, in which odd philosophers pick up their left chopstick first and even philosophers pick up their right chopstick first. (It prevents the "circular wait" requirement of deadlock.) (deadlock-free but unfair)
- Allow philosophers to pick up chopsticks only when both are available, in a critical section. (All or nothing allocation of critical resources) (deadlock-free, fair, but can cause starvation)
- Maintain a global queue, and whenever a philosopher is hungry, he goes onto the end of the queue. The only philosopher who may start to eat is the one on the head of the queue. (this solves the starvation!)
skip temporarily.
If you want, go to jbell's note.
- Address independence: same numeric address can be used in different address spaces (i.e., different processes), and remain logically distinct.
- Protection: one process can't access data in another process's address space
In order to achieve the 2 requirements above, people developed the idea of Virtual Memory
virtual address physical address
user process --------------> translator (MMU) --------------> physical memory
There're 2 ways to implement the translator: (1) Segmentation (2) Paging
- Divide address space into segments. Segment is a region of memory contiguous in both physical memory and in virtual address space.
- A reference to a memory location includes a value that identifies a segment and an offset (memory location) within that segment.
- Segment can grow.
- Segments may be created for program modules, or for classes of memory usage such as code, stack, data and heap segments.
Problems of Segmentation:
- external fragmentation
- the address space can't be larger than physical memory
Therefore, now we use paging!
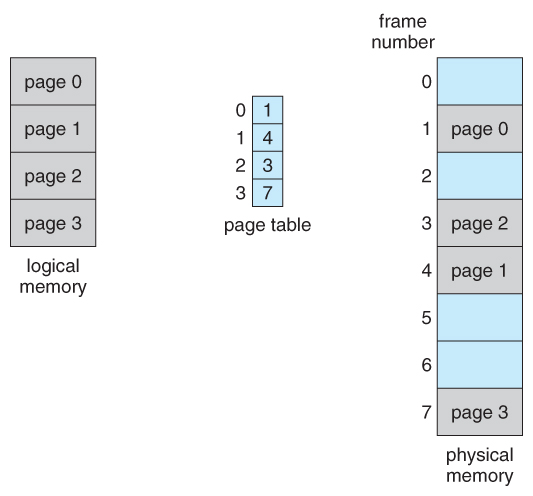
- A memory management scheme that allows processes physical memory to be discontinuous, and which eliminates problems with fragmentation by allocating memory in equal sized blocks known as pages.
- Any free physical page can store any virtual page. They're all the same size.
- Paging is the predominant memory management technique used today.
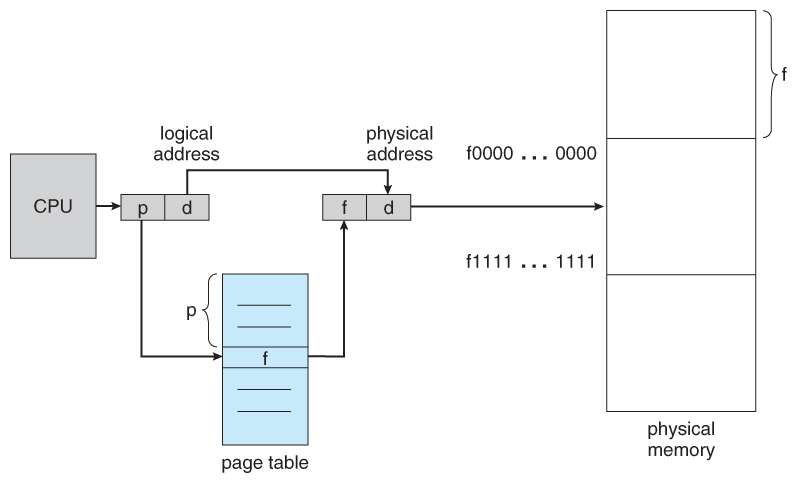
- A virtual address is split into
- virtual page number (high bits of address, e.g., bits 31-12). The number of bits determines how many pages a single process can address.
- offset (low bits of address, e.g., bits 11-0 for 4KB page size). The number of bits determines the maximum size of each page.
- A physical address is split into
- physical page number (high bits of address). The number of bits determines how many physical pages the system can address.
- offset (low bits of address).
- The page table maps the virtual page number to a physical page number. Every process has its own page table, so processes can't access other processes' memory.
Terms have different names:
- virtual page = page = memory page = logical page
- physical page = frame = memory frame = page frame
- virtual address = logical address
In the graph below, d is the offset, p is the virtual page number and f is the physical page number.
- Most OSs use demand paging. This means that physical pages are only read from the disk into physical memory when they are needed.
- Each page can be in physical memory or evicted to disk.
- In the page table, there is a resident status bit for each page-table entry (PTE), which says whether or not a valid page resides in physical memory.
- If the MMU tries to get a physical page number for a valid page but not resident in physical memory, it issues a pagefault to the operating system. The OS then loads that page from disk, and then returns to the MMU to finish the translation.
- If the MMU issues a pagefault for an invalid virtual address, then the OS will issue a segfault to the process, which usually terminates the process.
{:class="table table-bordered"}
| Virtual page number | Physical page number | resident |
|---|---|---|
| 0 | 105 | 1 |
| 1 | 15 | 0 |
| 2 | 283 | 1 |
| 3 | invalid | |
| ... | invalid |
We may need some prior knowledge of cache here. There're two types of writing schemes for cache:
- One is write-through. In this case, when a value in the cache is written, it is immediately written to the backing store as well (in this case, the disk). The cache and backing store are always synchronized in this case, but this can be very slow.
- The other main approach is write-back. In this case, the backing store and the cache are sometimes out of sync, but this approach is much faster.
Paging uses write-back scheme for speed reasons.
- When a page is loaded from the disk to physical memory, it is initially clean, i.e. the copy in physical memory matches the copy on disk. If then the copy in memory is ever changed, then its page-table entry is marked dirty, and it will need to be written back to the disk later.
- Evicting a clean page is fast, since it doesn’t need to be written back to the disk.
- When physical memory fills up, and a non-resident page is requested, then the OS needs to select a page to evict, to make room for the new page.
- The evicted page is called the victim, and is saved to the so-called swap space.
- The swap space is a separate region of the disk from the file system, and the size of the swap space limits the total virtual address space of all programs put together.
- Pagefaults are slow to resolve, since disk accesses are performed. Therefore one possible optimization is for the OS to write dirty pages to disk constantly as an background task. Then, when it is time to evict those pages, the OS won’t have to write them to disk.
Suppose your process starts up, and allocates some memory with malloc(). The allocator will then give part of a memory page to your process. The OS then updates the corresponding PTE, marking the virtual page as valid. If you then try to modify part of that page, only then will the OS actually allocate a physical page, and so the PTE will now be marked as resident. In addition, since the memory has been modified, the PTE will be marked dirty.
If the OS ever needs to evict this page, then, since it is dirty, the OS has to copy that page to disk (i.e. it swaps it, or performs paging). The PTE for the page is still marked valid but is now marked non-resident.
And, if we then want to read or write it, the OS may have to evict some other page in order to bring our page back into physical memory
There are a variety different strategies for choosing which page to evict.
Spooling (Simultaneous Peripheral Operations Online) is an I/O management or buffer management technique that allows the data of the input/output processes to be temporarily stored in the secondary memory (Hard Drive, SSD, etc.) which will be executed by the CPU or a device or a program. These data will be stored in the secondary memory until the system or a program requests the data for its execution.
Bélády's anomaly is the phenomenon in which increasing the number of page frames results in an increase in the number of page faults for certain memory access patterns. This phenomenon is commonly experienced when using the first-in first-out (FIFO) page replacement algorithm.
In FIFO, the page fault may or may not increase as the page frames increase, but in optimal and stack-based algorithms like LRU, as the page frames increase, the page fault decreases.