Synthesized audio quality is poor by using pre-trained WaveNet vocoder model #2191
Comments
|
It seems something wrong.
|
|
For reference (our pretrained model sample): |
I used ljspeech.wavenet.mol.v2 model which was trained with mel range 80 ~ 7600Hz
I extracted mel spectrogram from egs/ljspeech/tts1/exp/char_train_no_dev_pytorch_train_pytorch_tacotron2/outputs_model.last1.avg.best_decode_denorm/feats.ark. As far as I know, this feature file contains synthesized mel spectrogram which is denormalized at stage 5 in run.sh by following command.
so probably it's not the normalized feature I think. |
|
Yes, that is de-normalized feature. |
|
I changed wavenet input to normalized feature and now it seems work! Problem solved so I'll close this issue. |

I trained tacotron 2 model with LJSpeech Dataset with default setting.
Synthesized mel spectrogram seems to fine but when I converted synthesized mel spectrogram to audio with pre-trained WaveNet Vocoder model (ljspeech.wavenet.mol.v2) described in README page, the synthesized audio has very poor quality compared to synthesized mel spectrogram.
I extracted synthesized mel spectrogram from feats.ark and save those with npy format.
This is the synthesized mel spectrogram from LJSpeech dev set.
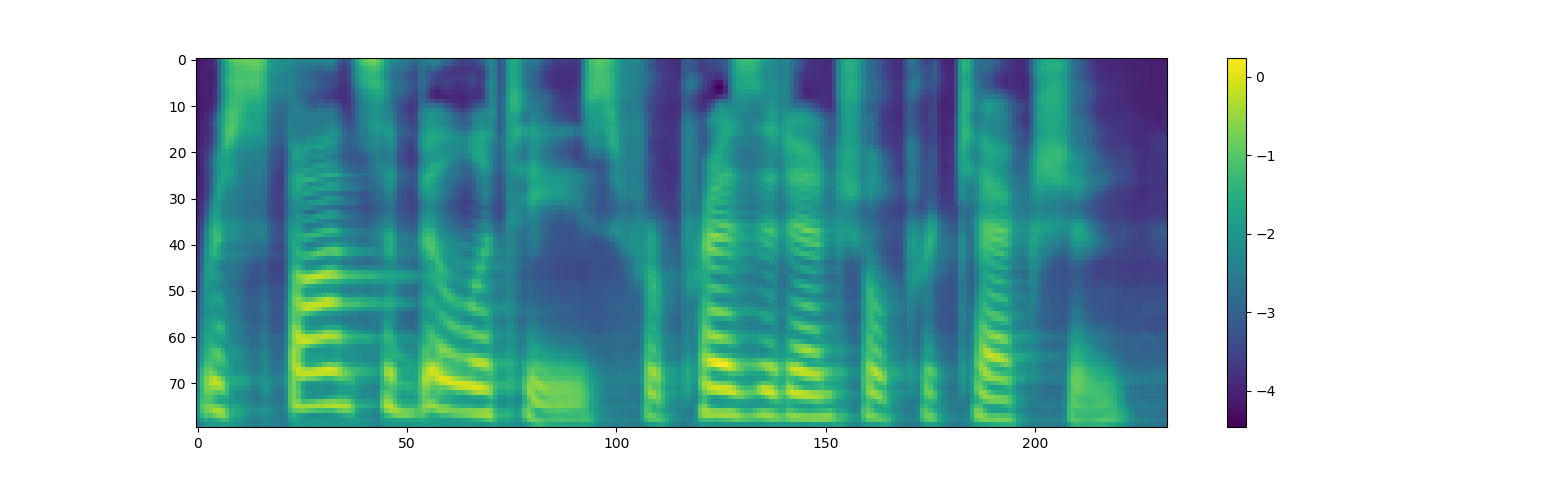
And this is the converted audio from synthesized mel spectrogram I attatched
LJ049-0151.zip
I've done peak normalize to the synthesized audio because its amplitude is too small
Is this model trained properly? If so, did I put synthesized mel spectrogram to vocoder in wrong way?
The text was updated successfully, but these errors were encountered: