egs2/aishell3/tts1 error occured when extracting x-vector #5099
Comments
|
I am trying the same recipe nowadays. I wanna ask a related question here. Did you ever notice that make_mfcc processes quite slow while extracting x-vector with Kaldi? @alandarker |
|
Finally, I gave up extracting x-vector with Kaldi (can't bear its low efficiency) and switched to speechbrain method. Fortunately, I didn't meet the same problem you stated above. I guess the reason lies in the mismatch of Pytorch version. I used Pytorch 1.11.0 and everything works fine. |
Sorry, I just saw it, the period of generating mfcc was such slow, when I was trying to extract x-vector with Kaldi, but I was unable to successfully implement the subsequent process. Glad to hear that it works fine with your jobs, however, don't forget to set speak_embeding_num = 192 in conf/train.yaml |
Describe the bug
hello, Im trying to run egs2/aishell3/tts1 to figure out how this toolkit is working,
stage 1 is already done,
when i run espnet/egs2/aishell3/tts1$ nohup ./run.sh --stage 2 --stop-stage 3 --use_xvector true
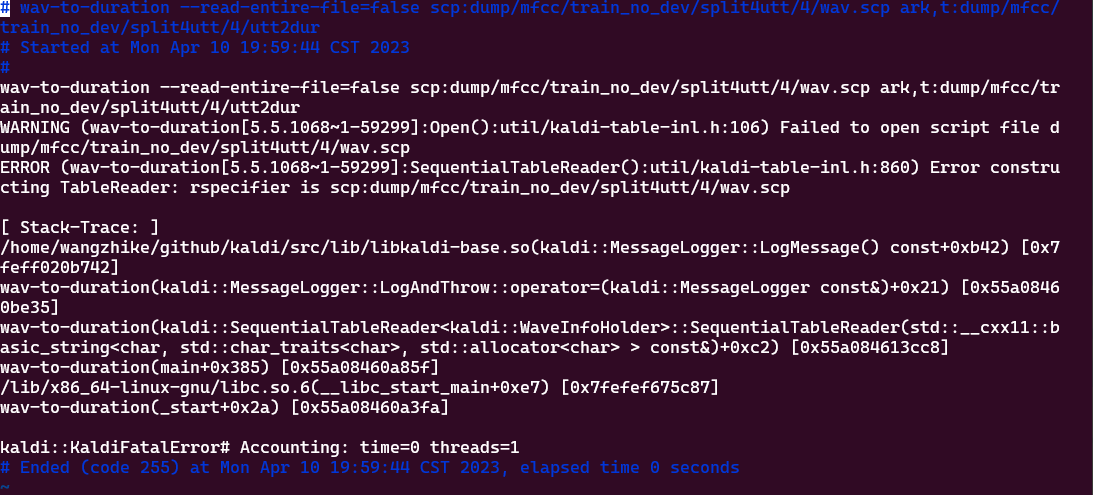
if I set xvector_tool=kaldi, an error occured,
it pointed that Failed to open script file dump/mfcc/train_no_dev/split4utt/4/wav.scp, and yes as i examined. but stage 1 is already done before this work, I dont know how to resolve it.
so i tried to set xvector_tool=speechbrain but another error occured as:
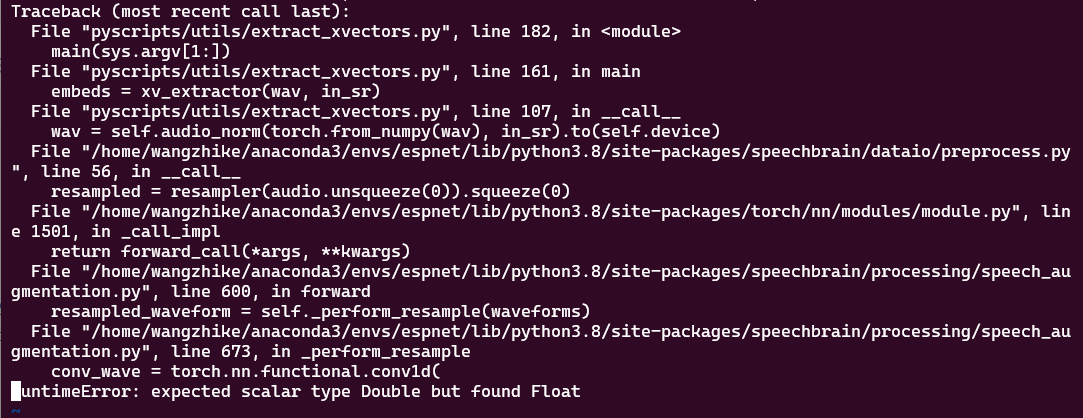
it seems that error occured by python file(pyscripts/utils/extract_xvectors.py), Im trying to solve it.
update: when i turned
wav = self.audio_norm(torch.from_numpy(wav), in_sr).to(self.device)
to
wav = self.audio_norm(torch.from_numpy(wav).to(torch.float32), in_sr).to(self.device),
error info dispeared
Basic environments:
[x] python=3.8.16 | packaged by conda-forge | (default, Feb 1 2023, 16:01:55) [GCC 11.3.0]
Python modules:
[x] torch=2.0.0+cu117
[x] torch cuda=11.7
[x] torch cudnn=8600
[x] torch nccl
[x] chainer=6.0.0
[x] chainer cuda
[x] chainer cudnn
[x] cupy=12.0.0
[x] cupy nccl
[x] torchaudio=2.0.1+cu117
[ ] torch_optimizer
[ ] warprnnt_pytorch
[x] chainer_ctc
[ ] pyopenjtalk
[ ] tdmelodic_pyopenjtalk
[ ] kenlm
[ ] mmseg
[x] espnet=202301
[x] numpy=1.23.5
[ ] fairseq
[ ] phonemizer
[ ] gtn
[ ] s3prl
[ ] transformers
[x] speechbrain=0.5.14
[ ] k2
[ ] longformer
[ ] nlg-eval
[ ] datasets
[ ] pykeops
[ ] whisper
[ ] RawNet3
[ ] reazonspeech
[ ] muskits
Executables:
[ ] sclite
[ ] sph2pipe
[ ] PESQ
[ ] BeamformIt
[ ] spm_train
[ ] spm_encode
[ ] spm_decode
[x] sox=14.4.2
[x] ffmpeg=5.1.2
[x] flac=1.4.2
[x] cmake=3.25.0
[x] Kaldi (compiled)
To Reproduce
espnet/egs2/aishell3/tts1$ nohup ./run.sh --use_xvector true
Error logs
1.
wav-to-duration --read-entire-file=false scp:dump/mfcc/train_no_dev/split4utt/4/wav.scp ark,t:dump/mfcc/train_no_dev/split4utt/4/utt2dur
Started at Mon Apr 10 19:59:44 CST 2023
wav-to-duration --read-entire-file=false scp:dump/mfcc/train_no_dev/split4utt/4/wav.scp ark,t:dump/mfcc/train_no_dev/split4utt/4/utt2dur
WARNING (wav-to-duration[5.5.1068
1-59299]:Open():util/kaldi-table-inl.h:106) Failed to open script file dump/mfcc/train_no_dev/split4utt/4/wav.scp1-59299]:SequentialTableReader():util/kaldi-table-inl.h:860) Error constructing TableReader: rspecifier is scp:dump/mfcc/train_no_dev/split4utt/4/wav.scpERROR (wav-to-duration[5.5.1068
[ Stack-Trace: ]
/home/wangzhike/github/kaldi/src/lib/libkaldi-base.so(kaldi::MessageLogger::LogMessage() const+0xb42) [0x7feff020b742]
wav-to-duration(kaldi::MessageLogger::LogAndThrow::operator=(kaldi::MessageLogger const&)+0x21) [0x55a08460be35]
wav-to-duration(kaldi::SequentialTableReaderkaldi::WaveInfoHolder::SequentialTableReader(std::__cxx11::basic_string<char, std::char_traits, std::allocator > const&)+0xc2) [0x55a084613cc8]
wav-to-duration(main+0x385) [0x55a08460a85f]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xe7) [0x7fefef675c87]
wav-to-duration(_start+0x2a) [0x55a08460a3fa]
kaldi::KaldiFatalError# Accounting: time=0 threads=1
Ended (code 255) at Mon Apr 10 19:59:44 CST 2023, elapsed time 0 seconds
2023-04-10T23:19:01 (tts.sh:211:main) ./tts.sh --lang zh --feats_type raw --fs 24000 --n_fft 2048 --n_shift 300 --win_length 1200 --token_type phn --cleaner none --g2p pypinyin_g2p_phone --train_config conf/train.yaml --inference_config conf/decode.yaml --train_set train_no_dev --valid_set dev --test_sets dev test --srctexts data/train_no_dev/text --use_xvector true --audio_format flac --stage 2 --stop-stage 3 --use_xvector true
2023-04-10T23:19:02 (tts.sh:323:main) Stage 2: Format wav.scp: data/ -> dump/raw/
utils/copy_data_dir.sh: copied data from data/train_no_dev to dump/raw/org/train_no_dev
utils/validate_data_dir.sh: Successfully validated data-directory dump/raw/org/train_no_dev
2023-04-10T23:19:03 (format_wav_scp.sh:45:main) scripts/audio/format_wav_scp.sh --nj 16 --cmd run.pl --audio-format flac --fs 24000 --segments data/train_no_dev/segments data/train_no_dev/wav.scp dump/raw/org/train_no_dev
2023-04-10T23:19:04 (format_wav_scp.sh:96:main) [info]: using data/train_no_dev/segments
2023-04-10T23:41:58 (tts.sh:211:main) ./tts.sh --lang zh --feats_type raw --fs 24000 --n_fft 2048 --n_shift 300 --win_length 1200 --token_type phn --cleaner none --g2p pypinyin_g2p_phone --train_config conf/train.yaml --inference_config conf/decode.yaml --train_set train_no_dev --valid_set dev --test_sets dev test --srctexts data/train_no_dev/text --use_xvector true --audio_format flac --stage 2 --stop-stage 3 --use_xvector true
2023-04-10T23:41:58 (tts.sh:323:main) Stage 2: Format wav.scp: data/ -> dump/raw/
utils/copy_data_dir.sh: copied data from data/train_no_dev to dump/raw/org/train_no_dev
utils/validate_data_dir.sh: Successfully validated data-directory dump/raw/org/train_no_dev
2023-04-10T23:41:59 (format_wav_scp.sh:45:main) scripts/audio/format_wav_scp.sh --nj 16 --cmd run.pl --audio-format flac --fs 24000 --segments data/train_no_dev/segments data/train_no_dev/wav.scp dump/raw/org/train_no_dev
2023-04-10T23:42:00 (format_wav_scp.sh:96:main) [info]: using data/train_no_dev/segments
2023-04-10T23:51:53 (format_wav_scp.sh:152:main) Successfully finished. [elapsed=594s]
utils/copy_data_dir.sh: copied data from data/dev to dump/raw/org/dev
utils/validate_data_dir.sh: Successfully validated data-directory dump/raw/org/dev
2023-04-10T23:51:53 (format_wav_scp.sh:45:main) scripts/audio/format_wav_scp.sh --nj 16 --cmd run.pl --audio-format flac --fs 24000 --segments data/dev/segments data/dev/wav.scp dump/raw/org/dev
2023-04-10T23:51:54 (format_wav_scp.sh:96:main) [info]: using data/dev/segments
2023-04-10T23:51:59 (format_wav_scp.sh:152:main) Successfully finished. [elapsed=6s]
utils/copy_data_dir.sh: copied data from data/dev to dump/raw/org/dev
utils/validate_data_dir.sh: Successfully validated data-directory dump/raw/org/dev
2023-04-10T23:51:59 (format_wav_scp.sh:45:main) scripts/audio/format_wav_scp.sh --nj 16 --cmd run.pl --audio-format flac --fs 24000 --segments data/dev/segments data/dev/wav.scp dump/raw/org/dev
2023-04-10T23:52:00 (format_wav_scp.sh:96:main) [info]: using data/dev/segments
2023-04-10T23:52:04 (format_wav_scp.sh:152:main) Successfully finished. [elapsed=5s]
utils/copy_data_dir.sh: copied data from data/test to dump/raw/test
utils/validate_data_dir.sh: Successfully validated data-directory dump/raw/test
2023-04-10T23:52:05 (format_wav_scp.sh:45:main) scripts/audio/format_wav_scp.sh --nj 16 --cmd run.pl --audio-format flac --fs 24000 --segments data/test/segments data/test/wav.scp dump/raw/test
2023-04-10T23:52:05 (format_wav_scp.sh:96:main) [info]: using data/test/segments
2023-04-10T23:55:54 (format_wav_scp.sh:152:main) Successfully finished. [elapsed=229s]
2023-04-10T23:55:54 (tts.sh:403:main) Stage 2+: Extract X-vector: data/ -> dump/xvector using python toolkits
2023-04-10 23:55:57,507 (fetching:91) INFO: Fetch hyperparams.yaml: Using existing file/symlink in pretrained_models/EncoderClassifier-8f6f7fdaa9628acf73e21ad1f99d5f83/hyperparams.yaml.
2023-04-10 23:55:57,508 (fetching:118) INFO: Fetch custom.py: Delegating to Huggingface hub, source speechbrain/spkrec-ecapa-voxceleb.
2023-04-10 23:55:58,913 (fetching:91) INFO: Fetch embedding_model.ckpt: Using existing file/symlink in pretrained_models/EncoderClassifier-8f6f7fdaa9628acf73e21ad1f99d5f83/embedding_model.ckpt.
2023-04-10 23:55:58,913 (fetching:91) INFO: Fetch mean_var_norm_emb.ckpt: Using existing file/symlink in pretrained_models/EncoderClassifier-8f6f7fdaa9628acf73e21ad1f99d5f83/mean_var_norm_emb.ckpt.
2023-04-10 23:55:58,913 (fetching:91) INFO: Fetch classifier.ckpt: Using existing file/symlink in pretrained_models/EncoderClassifier-8f6f7fdaa9628acf73e21ad1f99d5f83/classifier.ckpt.
2023-04-10 23:55:58,914 (fetching:91) INFO: Fetch label_encoder.txt: Using existing file/symlink in pretrained_models/EncoderClassifier-8f6f7fdaa9628acf73e21ad1f99d5f83/label_encoder.ckpt.
2023-04-10 23:55:58,914 (parameter_transfer:245) INFO: Loading pretrained files for: embedding_model, mean_var_norm_emb, classifier, label_encoder
0%| | 0/174 [00:00<?, ?it/s]
0%| | 0/174 [00:00<?, ?it/s]
Traceback (most recent call last):
File "pyscripts/utils/extract_xvectors.py", line 182, in
main(sys.argv[1:])
File "pyscripts/utils/extract_xvectors.py", line 161, in main
embeds = xv_extractor(wav, in_sr)
File "pyscripts/utils/extract_xvectors.py", line 107, in call
wav = self.audio_norm(torch.from_numpy(wav), in_sr).to(self.device)
File "/home/wangzhike/anaconda3/envs/espnet/lib/python3.8/site-packages/speechbrain/dataio/preprocess.py", line 56, in call
resampled = resampler(audio.unsqueeze(0)).squeeze(0)
File "/home/wangzhike/anaconda3/envs/espnet/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/wangzhike/anaconda3/envs/espnet/lib/python3.8/site-packages/speechbrain/processing/speech_augmentation.py", line 600, in forward
resampled_waveform = self._perform_resample(waveforms)
File "/home/wangzhike/anaconda3/envs/espnet/lib/python3.8/site-packages/speechbrain/processing/speech_augmentation.py", line 673, in _perform_resample
conv_wave = torch.nn.functional.conv1d(
RuntimeError: expected scalar type Double but found Float
The text was updated successfully, but these errors were encountered: