
- Неограниченная гибкость
- Неограниченная функциональность
- Приемлемая цена
- Полный провал по производительности

С другой стороны для изменения логики работы достаточно переписать программу. Обновления CPU не требуется.
Например, абсолютно все рутеры Mikrotik используют CPU для маршрутизации пакетов.
Иными словами CPU годится там, где не гонимся за ультраскоростями, а важен широкий набор функций и невысокая цена.
Note
Впрочем, не без исключений: бывают, что и большие штуки коммутируют в CPU.
Можно ли считать это участием в коммутации? Скорее да, чем нет.
Более того, современные CPU обладают дополнительными блоками инструкций. У Intel это SSE - Streaming SIMD Extensions, позволяющие значительно ускорить обработку трафика.
Тут обычные CPU уже заходят в зону NP (Network Processor) - процессоров, которые можно программировать на языках высокого уровня вроде C, и обладающих большим набором спец. инструкций для работы с сетевым трафиком.
Одним из узких мест современных процессоров ещё является шина доступа - PCIe. В один процессор сейчас более-менее можно загнать 100 с небольшим Гбит/с.
Но как бы производители программных решений ни продвигали идею, что "все можно сделать в софте", однако скорости выше 500 Гбит/с пока что можно достигать только с помощью специализированных асиков.
И давайте ещё прикинем. Выдержка с сайта про VPP:
Tip
Recent testing of FD.io release 17.04 shows impressive gains in performance on Intel’s newest platform when switching and routing layer 2⁄3 traffic. With the prior generation Intel® Xeon® Processor E7-8890v3, FD.io testing showed aggregate forwarding rate of 480 Gbps (200 Mpps) for 4-Socket machine (using 4 of E7-8890v3 CPU configuration); however, the same FD.io tests run on two 2-Socket blades (e.g. a modern 2RU server) with the new Intel® Xeon® Platinum 8168 CPUs (using four of 8168 CPUs in two by two-socket configuration), within the same power budget, show increase of forwarding rate to 948 Gbps (400 Mpps) benefiting from the PCIe bandwidth increase of the new CPUs, and the overall decrease in cycles-per-packet due to CPU micro-architecture improvements.
4 проца по 18 ядер = 72 ядра = 480 Gbps (200 Mpps)
$28696 только за процы
2 проца по 24 ядра = 48 ядер = 948 Gbps (400 Mpps)
$11780 только за процы
Без обвязки. А ещё кушать электричества он будет как голодный шакал. Не самый дешёвый получится рутер. Зато гибкий.

- Околонулевая гибкость
- Ограниченная функциональность
- Низкая цена
- Ультравысокая производительность

Сначала очень долго пишется код, реализующий логику, на специальном языке программирования, вроде Verilog, далее он преобразуется в интегральную схему, отлаживается, проверяется и отправляется в тираж. После этого поменять что-то в логике чипа можно, только произведя новый чип.
Каждый пакет обрабатывается, просто прогоняясь по конвейеру из транзисторов, совершающих заранее определённые действия. Это называется Pipeline.
Область применения: почти любые коммутаторы и многие маршрутизаторы.
Note
Впрочем, не без исключений: Juniper в своей линейке маршрутизаторов MX многие годы использует ASIC Trio.
Который, кстати, согласно книге об MX является на самом деле набором ASIC'ов:PFEs are made of several ASICs, which may be grouped into four categories:
- Routing ASICs: LU or XL Chips. LU stands for Lookup Unit and XL is a more powerful (X) version.
- Forwarding ASICs: MQ or XM Chips. MQ stands for Memory and Queuing, and XM is a more powerful (X) version.
- Enhanced Class of Service (CoS) ASICs: QX or XQ Chips. Again, XQ is a more powerful version.
- Interface Adaptation ASICs: IX (only on certain low-speed GE MICs) and XF (only on MPC3E)
Последние лет 10 в области сетевых микросхем произошёл сдвиг в направлении программируемых ASIC'ов, о которых чуть позже.
Русский термин - ПЛИС - Программируемая Логическая Интегральная Схема.
- Вполне удовлетворительная гибкость
- Вполне удовлетворительная функциональность
- Цена успешного полёта Апполона до Луны и обратно
- Отличная производительность
Что это даёт?
А то, что FPGA полностью программируемый - логику работы блоков, из которых он состоит, можно поменять. Для этого потребуется обновить прошивку чипа, что менее удобно, чем загрузить программу в CPU, но гораздо удобнее, чем перепаять ASIC.
Так, если поддержка какой-то функции (условный Geneve) не была заложена изначально, её всегда можно добавить потом новой прошивкой.
Однако за такую программируемость приходится дорого платить.
Область применения: POC или низкоскоростные решения для энтерпрайз-сегмента.
Note
Впрочем, не без исключений: собеседовался я как-то раз в контору, в которой модульную коробку для операторов собирали полностью на FPGA, включая фабрику.
У этого даже есть основания: задолго до появления Programmable ASIC'ов на FPGA можно было делать любую обработку пакетов. И даже через несколько лет после производства плисину легко перепрошить и получить поддержку новой функции.
Автору неизвестны вендоры, которые бы на ПЛИС сделали PFE на скорости более 100 Гбит/с, по всей видимости, потому что частная компания не обладает для этого достаточным капиталом.
Но для рынка энтерпрайз такие решения могут подойти вполне.Однако, я слышал, что в процессе разработки ASIC возможен такой подход, когда сначала разрабатывается FPGA, программируется нужным образом, тестируется, а потом с неё делают слепок для производства ASIC. Но пруфов нет.

- Отличная гибкость
- Отличная функциональность
- Цена весьма высокая
- Производительность весьма высокая

NP или NPU - Network Processor Unit.
Он, как и CPU, обычно состоит из нескольких ядер, каждое из которых отвечает за свой сегмент. Для изменения логики так же достаточно переписать код приложения.
NP позволяет делать более сложные штуки - например выполнять циклы (чего лишены ASIC и FPGA), делать NAT, почти любые инкапсуляции, пушить и попать условно произвольное число меток итд.
Долгое время NP позиционировался, как серебряная пуля для всех сетевых приложений.
Но производительность уступает ASIC'ам и FPGA.
Большим преимуществом является то, что писать программы для NP можно на С. Это значительно ускоряет процесс, кроме того, где-то можно переиспользовать код.
Область применения: маршрутизаторы агрегации и ядра.
Note
Впрочем, не без исключений: например Smart-NIC Netronome в начале своего пути использовал Intel IXP.

- Приемлемая гибкость
- Ограниченная функциональность
- Низкая цена
- Ультравысокая производительность.

"Почему бы нам не взять ASIC и сделать его немножечко программируемым?" - таким вопросом, видимо, задались разработчики и выдали замечательную вещь, которую циска в своём треугольнике поместила в самую середину, хотя это и не совсем так, потому что производительность программируемого ASIC'а такая же, как и у обычного. Им удалось вырваться из 2D.
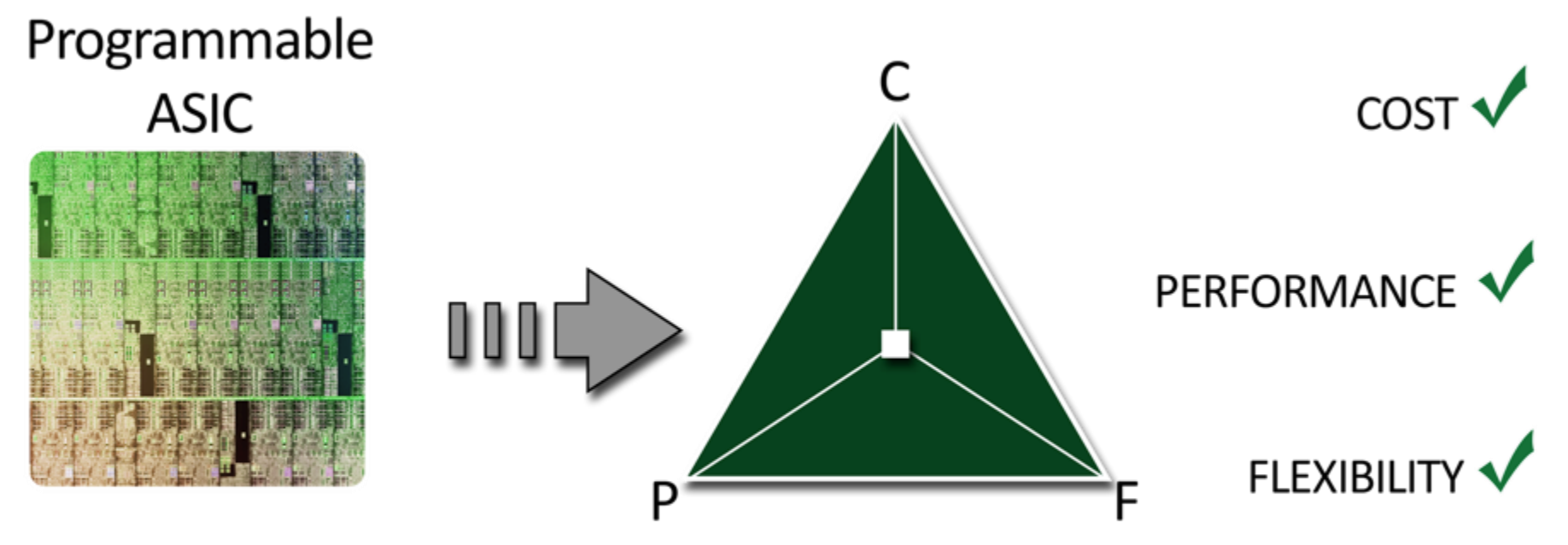
Большинство датацентровых коммутаторов и некоторые маршрутизаторы уровня границы ДЦ работают на программируемых асиках.