| 属性 | Myisam | Innodb |
|---|---|---|
| 事务 | 不支持 | 支持(sql默认自动提交) |
| 外键 | 不支持 | 支持 |
| 索引 | 非聚簇索引 | 聚簇索引 |
| 锁 | 表锁 | 行锁(默认)、表锁 |
| 主键 | 可以没有 | 必须要有 |
InnoDB为什么一定要有自增ID作为主键?
1、 如果定义了主键
InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引(Not Null Unique)作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引。
2、如果使用自增主键
那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页,这样存取效率会比较高。
3、如果使用非自增主键
由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,极大程度上会影响存取效率。
主键AUTO_INCREMENT
1、AUTO_INCREMENT只适用于整数类型数据列。
2、AUTO_INCREMENT的长度就是列的最大长度,一旦到达上限,则报错,无法插入。
3、进行全表删除时,AUTO_INCREMENT会从1重新开始编号。
a.编写过程:
select dinstinct ..from ..join ..on ..where ..group by ...having ..order by ..limit ..
b.解析过程:
from .. on.. join ..where ..group by ....having ...select dinstinct ..order by limit ...
- 定长和变长,char 表示定长,长度固定,varchar表示变长,即长度可变。char如果插入的长度小于定义长度时,则用空格填充;varchar小于定义长度时,还是按实际长度存储,插入多长就存多长。因为char长度固定,所以存取速度还是要比varchar要快得多,方便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定,所以会占据多余的空间。
- 存储的容量不同,对 char 来说,最多能存放的字符个数 255,和编码无关。而 varchar 呢,最多能存放 65532 个字符。varchar的最大有效长度由最大行大小和使用的字符集确定。整体最大长度是 65,532字节(如果使用utf8编码的话,一个字符占3个字节大小,gbk是2个字节,默认的latin是1个字节)。
- 普通索引(index):最基本的索引,没有任何限制
- 唯一索引(unique):与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
- 主键索引(primary):它 是一种特殊的唯一索引,不允许有空值(唯一、非空)。
- 全文索引(fulltext):仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
- 组合索引(index):为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
索引长度的计算:
-
varchar(20)--> 20*3(utf8) + 1(允许空值) + 2(可变长度)
-
int是4个字节
utf8:1个字符3个字节
gbk:1个字符2个字节
latin:1个字符1个字节
key_len 指的是索引的长度 ,用于判断复合索引是否被完全使用,当使用复合索引的时候,索引长度为每个单独索引长度的累加和。
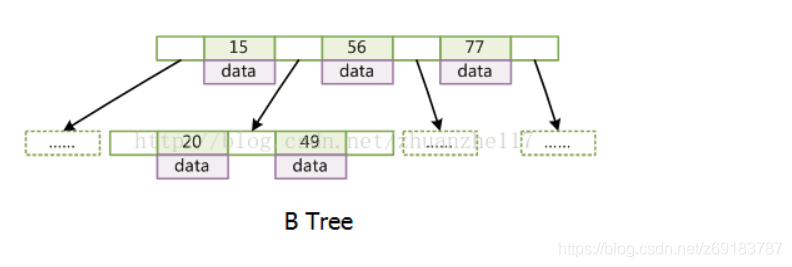
B树:每个节点都存储key和data。
B+树:只有叶子节点存储data。
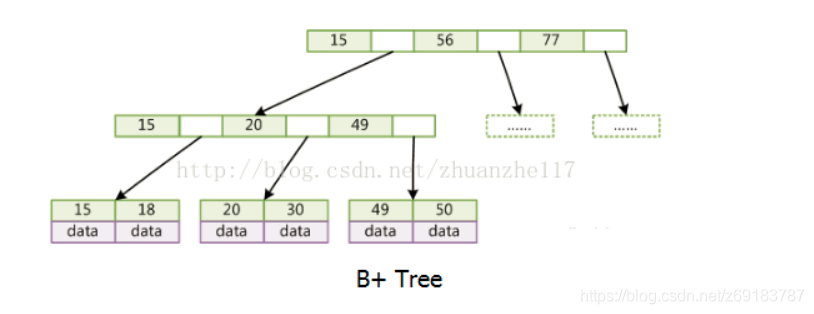
B+树为所有叶子节点增加一个链指针,这使得所有的数据用链表链在了一起,遍历整棵树只需要遍历叶子节点即可。
- 如果是where name='xxx'这种等值查询,hash只需要O(1)的时间复杂度,这是hash的优势
- 如果是范围查询检索,这时候hash索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
- 哈希索引也没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
- hash不支持联合多列索引的最佳左前缀规则;
- 在大量重复键值的情况下,hash索引效率低(hash碰撞)。
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
聚簇索引的查询过程:
聚簇索引具有唯一性,由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有一个聚簇索引。
Innodb中,在聚簇索引之上创建的索引称之为辅助索引,非聚簇索引都是辅助索引,像普通索引、复合索引、唯一索引。辅助索引叶子节点存储的不再是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找。
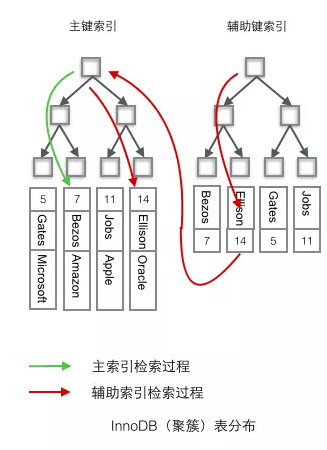
- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
- 若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)
显然,每次使用辅助索引检索都需要经过两次B+查找,那么聚簇索引的优势在哪?
1、由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中(缓存器),再次访问时,会在内存中完成访问,不必访问磁盘。
2、辅助索引的叶子节点,存储主键值,而不是数据的存放地址。好处是当行数据放生变化时,索引树的节点也需要分裂变化;或者是我们需要查找的数据,在上一次IO读写的缓存中没有,需要发生一次新的IO操作时,可以避免对辅助索引的维护工作,只需要维护聚簇索引树就好了。另一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。
3、因为MyISAM的主索引并非聚簇索引,那么他的数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行I/O读取,于是开始不停的寻址。聚簇索引则只需一次I/O。
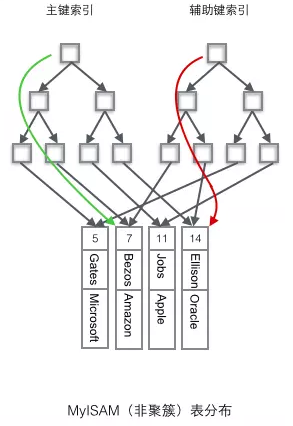
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
非聚簇索引的查询过程:
非聚簇索引的两棵B+索引树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
添加索引:
1.添加PRIMARY KEY(主键索引)
mysql>ALTER TABLE 表名 ADD PRIMARY KEY (字段名)
2.添加UNIQUE(唯一索引)
mysql>ALTER TABLE 表名 ADD UNIQUE (字段名)
3.添加INDEX(普通索引)
mysql>ALTER TABLE 表名 ADD INDEX 索引名 (字段名)
4.添加FULLTEXT(全文索引)
mysql>ALTER TABLE 表名 ADD FULLTEXT (字段名)
5.添加多列索引
mysql>ALTER TABLE 表名 ADD INDEX 索引名 (字段名)
查看索引
mysql> show index from 表名;
- 原子性(Atomicity)
事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚。
比如A给B转钱,A原本余额是1000,转200给B,B原本余额是0,收到A的转账之后余额应该变成200,结果A由于某种原因转账失败,事务回滚,那么A的余额还是1000,B的余额还是0。
- 一致性(Consistency)
数据库在事务执行前后都保持一致性状态。
比如有A, B, C, D四个人,银行余额4个人共计1000元,那么这个4个人无论互相怎么转账,钱的总额是1000不变。
- 隔离性(Isolation)
一个事务所做的修改在最终提交以前,对其它事务是不可见的。可以理解为锁。
- 持久性(Durability)
一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
比如A给B赚钱,A原本余额是1000,转200给B,B原本余额是0,收到A的转账之后余额变成200,事务完成后,服务器因为某种原因断电,再开机后发现,由于事务已经完成,A的余额就是800,B的余额就是200.
1、脏读(读取未提交数据)
A事务读取B事务尚未提交的数据,此时如果B事务发生错误并执行回滚操作,那么A事务读取到的数据就是脏数据。
| 时间顺序 | 转账事务 | 取款事务 |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 开始事务 | |
| 3 | 查询账户余额为200元 | |
| 4 | 取款100元,余额被更改为100元 | |
| 5 | 查询账户余额为100元(产生脏读) | |
| 6 | 取款操作发生未知错误导致钱没取出来,事务回滚,余额变更为200元 | |
| 7 | 转入200元,余额被更改为300元(脏读的100+200) | |
| 8 | 提交事务 | |
| 备注 | 按照正确逻辑,此时账户余额应该为400元 |
2、不可重复读(前后多次读取,数据内容不一致)
| 时间顺序 | 事务A | 事务B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 开始事务 | |
| 3 | 第一次查询,余额为200 | |
| 4 | 其他操作 | |
| 5 | 更改余额为100 | |
| 6 | 提交事务 | |
| 7 | 第二次查询,余额为100 | |
| 备注 | 按照正确逻辑,事务A前后两次读取到的数据应该一致 |
3、幻读(前后多次读取,数据总量不一致)
| 时间顺序 | 事务A | 事务B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 开始事务 | |
| 3 | 读取所有选了语文课的同学为10人 | |
| 4 | 其他操作 | |
| 5 | 新增一个选了语文的同学 | |
| 6 | 提交事务 | |
| 7 | 第二次查询,选了语文课的同学为11人 | |
| 备注 | 按照正确逻辑,事务A前后两次读取到的数据总量应该一致,即选了语文课的同学数量为10 |
1、未提交读(READ UNCOMMITTED)
事务中的修改,即使没有提交,对其它事务也是可见的。这样会提高性能,但是会导致脏读问题。
2、提交读(READ COMMITTED)
一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。该级别可以解决脏读为问题,但不能避免不可重复读。
3、可重复读(REPEATABLE READ)
保证在同一个事务中多次读取同样数据的结果是一样的。可以解决不可重复读的问题,但还是不能避免幻读的问题。
4、可串行化(SERIALIZABLE)
强制事务串行执行。可以解决所有问题。最高级别的隔离,
MySQL默认的隔离级别是可重复读(REPEATABLE READ)。
修改隔离级别
mysqld.cnf:
transaction-isolation = READ-COMMITTED
一般可以分为两类,一个是悲观锁,一个是乐观锁。
悲观锁一般就是我们通常说的数据库锁机制,乐观锁一般是指用户自己实现的一种锁机制。
悲观锁按照使用性质分为:
- 共享锁(s锁),也叫读锁,事务A对对象T加s锁,其他事务也只能对T加S锁,多个事务可以同时读,但不能有写操作,直到A释放S锁。
- 排它锁(x锁),也称写锁,事务A对对象T加X锁以后,其他事务不能对T加任何锁(但可读),只有事务A可以读写对象T直到A释放X锁。
- 更新锁(u锁),允许其他事务读,但不允许再施加U锁或X锁;当被读取的对象将要被更新时,则升级为X锁,主要是用来防止死锁的。
悲观锁按照作用范围划分:
- 行锁
- 表锁
乐观锁: 每次自己操作数据的时候认为没有人回来修改它,所以不去加锁,但是在更新的时候会去判断在此期间数据有没有被修改。
乐观锁实现方式:
- 版本号
- 时间戳
for update是在数据库中上锁用的,可以为数据库中的行上一个排它锁。当一个事务的操作未完成时候,其他事务可以读取但是不能写入或更新。
事务A
start transaction ;
select * from table_name where id =1 for update ;
update table_name set count = count - 1 where id= 1;
事务B也想做类似的库存操作
start transaction ;
select * from table_name where id =1 for update ;
# 下面的这行sql会等待,直到上面的事务回滚或者commit才得到执行。
update table_name set count = count - 1 where id= 1;
for update如果作用在主键上(where后面判断条件是主键)是行锁,其他情况下是表锁。
什么时候用for update?
应在数据独占的时候使用,比如火车票订票,库存修改等。
从上面聚簇索引可知,辅助索引的数据查找如果不是索引覆盖情况下需要根据查到的主键ID再去查找主键索引表从而获得真正的数据。
先索引扫描,再通过ID去取索引中未能提供的数据,即为回表。
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where name='xxx',即辅助索引查询方式,则需要先搜索 name 索引树,得到 ID 的值,再到 ID 索引树搜索一次。这个过程称为回表。
select ..from table where exist (子查询) ;
select ..from table where 字段 in (子查询) ;
如果主查询的数据集大,则使用In,效率高。
如果子查询的数据集大,则使用exist,效率高。
exist语法: 将主查询的结果,放到子查需结果中进行条件校验(看子查询是否有数据,如果有数据 则校验成功),如果 复合校验,则保留数据;
记住:永远都是小表驱动大表!
create table book(
bid int(4) primary key,
name varchar(20) not null,
authorid int(4) not null,
publicid int(4) not null,
typeid int(4) not null
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into book values(1,'tjava',1,1,2);
insert into book values(2,'python',2,1,2);
insert into book values(3,'sql',3,2,1);
insert into book values(4,'js',4,2,3);查询authorid=1且 typeid为2或3的bid
没有索引:
explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where; Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
1. 优化:加索引
alter table book add index idx_bta (bid,typeid,authorid);
explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+------------------------------------------+
| 1 | SIMPLE | book | NULL | index | NULL | idx_bta | 12 | NULL | 4 | 25.00 | Using where; Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+------------------------------------------+
1 row in set, 1 warning (0.00 sec)
索引一旦进行升级优化,需要将之前废弃的索引删掉,防止干扰。
drop index idx_bta on book;
根据SQL实际解析的顺序,调整索引的顺序:
alter table book add index idx_tab (typeid,authorid,bid); --虽然可以回表查询bid,但是将bid放到索引中 可以提升使用using index ;
再次优化(之前是index级别):思路。因为in查询有时会变为范围查询,因此交换索引的顺序,将typeid in(2,3) 放到最后。
drop index idx_tab on book;
alter table book add index idx_atb (authorid,typeid,bid);
explain select bid from book where authorid=1 and typeid in(2,3) order by typeid desc;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | book | NULL | range | idx_atb | idx_atb | 8 | NULL | 2 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
本例中同时出现了Using where(需要回原表)、Using index(索引覆盖,不需要回原表)
原因:where authorid=1 and typeid in(2,3) 中 authorid在索引(authorid,typeid,bid)中,因此不需要回原表(直接在索引表中能查到),而typeid虽然也在索引(authorid,typeid,bid)中,但是含in的范围查询已经使该typeid索引失效,因此相当于没有typeid这个索引,所以需要回原表(using where)
还可以通过key_len证明in可以使索引失效。
例如以下没有了in,则不会出现using where
explain select bid from book where authorid=1 and typeid=3 order by typeid desc;
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | book | NULL | ref | idx_atb | idx_atb | 8 | const,const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
小结:
a.联合索引要注意使用最佳左前缀,保持索引的定义和使用的顺序一致性
b.索引需要逐步优化
c.将含in的范围查询放到where条件的最后,防止失效
create table teacher2(
tid int(4) primary key,
cid int(4) not null
);
insert into teacher2 values(1,2);
insert into teacher2 values(2,1);
insert into teacher2 values(3,3);
create table course2(
cid int(4),
cname varchar(20)
);
insert into course2 values(1,'java');
insert into course2 values(2,'python');
insert into course2 values(3,'kotlin');左连接:
explain select * from teacher2 t left outer join course2 c
on t.cid=c.cid where c.cname='java';索引往哪张表加?
- 小表驱动大表
- 索引建立经常使用的字段上 (本题 t.cid=c.cid可知,t.cid字段使用频繁,因此给该字段加索引)
- [一般情况对于左外连接,给左表加索引;右外连接,给右表加索引]
例如:
小表:10 大表:300
select ...where 小表.x10=大表.x300;
for(int i=0;i<小表.length10;i++)
{
for(int j=0;j<大表.length300;j++)
{
...
}
}select ...where 大表.x300=小表.x10 ;
for(int i=0;i<大表.length300;i++)
{
for(int j=0;j<小表.length10;j++)
{
...
}
}以上2个FOR循环,最终都会循环3000次;但是对于双层循环来说:一般建议将数据小的循环放外层;数据大的循环放内层。
--所以当编写 ..on t.cid=c.cid 时,将数据量小的表放左边(假设此时t表数据量小)
alter table teacher2 add index index_teacher2_cid(cid) ;
alter table course2 add index index_course2_cname(cname);
explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';
+----+-------------+-------+------------+------+---------------------+---------------------+---------+--------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------+---------------------+---------+--------------------+------+----------+-------------+
| 1 | SIMPLE | c | NULL | ref | index_course2_cname | index_course2_cname | 63 | const | 1 | 100.00 | Using where |
| 1 | SIMPLE | t | NULL | ref | index_teacher2_cid | index_teacher2_cid | 4 | sql_optimize.c.cid | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------------+---------------------+---------+--------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
小结:
a.小表驱动大表
b.索引建立在经常查询的字段上
(1)复合索引
- a.复合索引,不要跨列或无序使用(最佳左前缀)
- b.复合索引,尽量使用全索引匹配
(2)不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效
select ..where A.x = .. ; --假设A.x是索引
不要:select ..where A.x*3 = .. ;
explain select * from book where authorid = 1 and typeid = 2;--用到了2个索引
explain select * from book where authorid = 1 and typeid*2 = 2;--用到了1个索引
explain select * from book where authorid*2 = 1 and typeid*2 = 2;--用到了0个索引
explain select * from book where authorid*2 = 1 and typeid = 2;--用到了0个索引,原因:对于复合
索引,如果左边失效,右侧全部失效。(a,b,c),例如如果 b失效,则b c同时失效。(3)复合索引不能使用不等于(!= <>)或is null (is not null),否则自身以及右侧所有全部失效 复合索引中如果有>,则自身和右侧索引全部失效。
explain select * from book where authorid = 1 and typeid =2; --使用索引 type=ref
explain select * from book where authorid != 1 and typeid =2; --不使用索引 type=all
explain select * from book where authorid != 1 and typeid !=2;--不使用索引 type=all注意:SQL优化,是一种概率层面的优化。至于是否实际使用了我们的优化,需要通过explain进行推测体验概率情况(< > =):原因是服务层中有SQL优化器,可能会影响我们的优化
drop index idx_typeid on book;
drop index idx_authroid on book;
alter table book add index idx_book_at (authorid,typeid);
explain select * from book where authorid = 1 and typeid =2;--复合索引全部使用
explain select * from book where authorid > 1 and typeid =2;--复合索引中如果有>,则自身和右侧索引全部失效。
explain select * from book where authorid = 1 and typeid >2;--复合索引全部使用
----明显的概率问题---
explain select * from book where authorid < 1 and typeid =2;--复合索引只用到了1个索引
explain select * from book where authorid < 4 and typeid =2;--复合索引全部失效我们学习索引优化 ,是一个大部分情况适用的结论,但由于SQL优化器等原因该结论不是100%正确。一般而言, 范围查询(> < in),之后的索引失效。
(4)补救。尽量使用索引覆盖(using index)(a,b,c)
select a,b,c from xx..where a= .. and b =.. ;(5)like尽量以“常量”开头,不要以'%'开头,否则索引失效
select * from xx where name like '%x%'; --name索引失效
explain select * from teacher where tname like '%x%'; --tname索引失效
explain select * from teacher where tname like 'x%';
explain select tname from teacher where tname like '%x%'; --如果必须使用like '%x%'进行模糊查询,可以使用索引覆盖 挽救一部分。(6)尽量不要使用类型转换(显示、隐式),否则索引失效
explain select * from teacher where tname = 'abc' ;
explain select * from teacher where tname = 123 ;//程序底层将 123 -> '123',即进行了类型转换,因此索引失效(7)尽量不要使用or,否则索引失效
explain select * from teacher where tname ='' or tcid >1 ; --将or左侧的tname 失效。(8)一些其他的优化方法
- exist和in
select ..from table where exist (子查询) ;
select ..from table where 字段 in (子查询) ;
如果主查询的数据集大,则使用In,效率高。
如果子查询的数据集大,则使用exist,效率高。
exist语法: 将主查询的结果,放到子查需结果中进行条件校验(看子查询是否有数据,如果有数据 则校验成功) ,
如果 复合校验,则保留数据;
select tname from teacher where exists (select * from teacher) ;
--等价于select tname from teacher(9)order by 优化
- 避免select *
- 复合索引不要跨列使用 ,避免using filesort
- 保证全部的排序字段 排序的一致性(都是升序 或 降序)