ProcessGroupNCCL does not support scatter #144
Comments
|
can u paste the complete trace? |
|
The trace is as follows: |
this is because NCCL indeed does not support scatter I believe? If you can update your pytorch to the latest, the code should be directly usingt the all2all primitive. For scatter, you have to use MPI guess. But we will update the documentation for better debugging. |
|
It looks like this is resolved. |
|
|
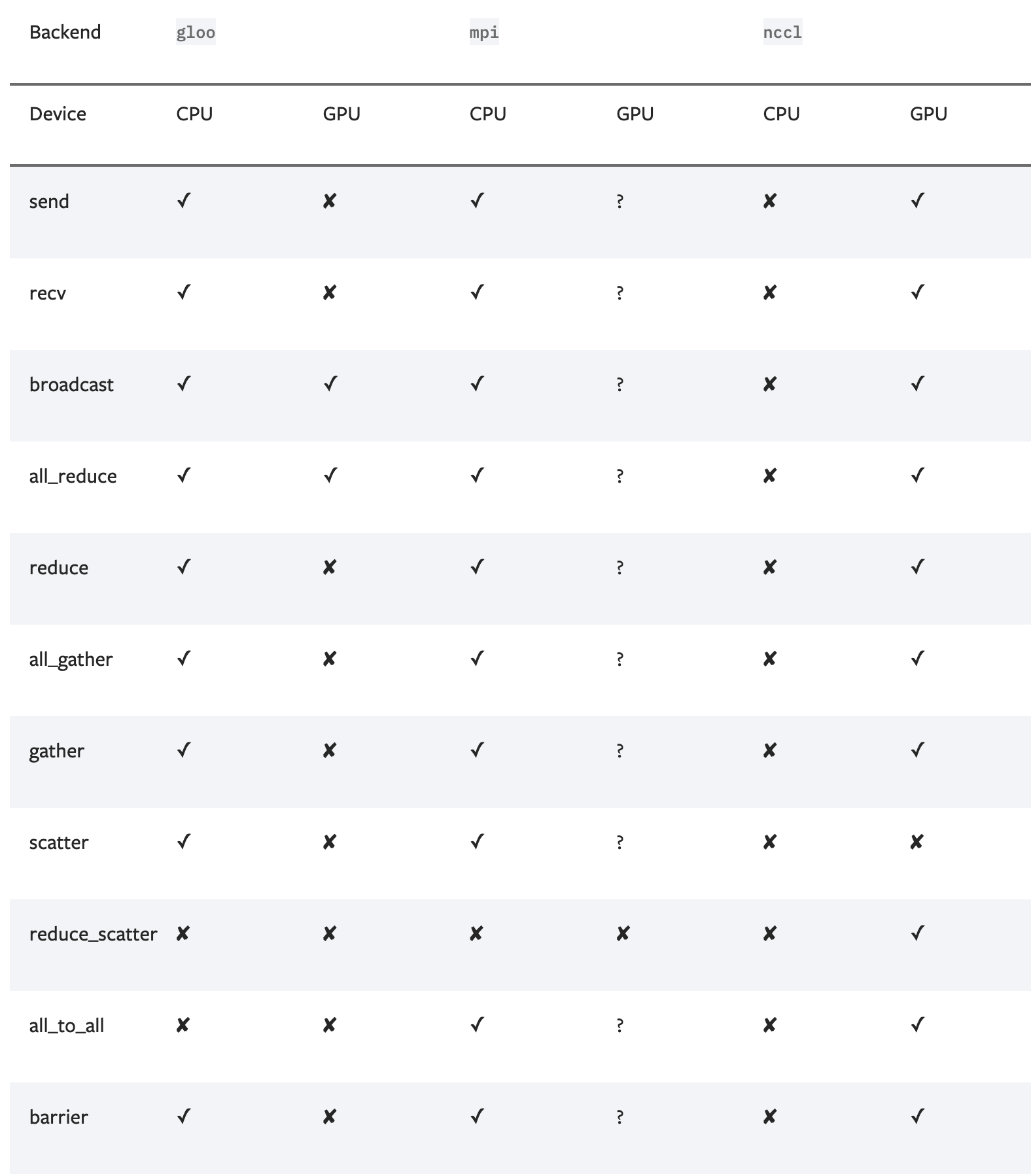
When trying running DLRM distributedly using mpirun with NCCL as the backend there is a runtime error "ProcessGroupNCCL does not support scatter". Is there anyway to solve that?
Thanks!
The text was updated successfully, but these errors were encountered: