Extremely unstable training on multiple gpus #23
Comments
|
It is kind of a shot in the dark as I don't have access to several GPUs. However, maybe this would help so I am posting it below. You can see at the lines below that the learning rate is scaled with respect to batch size and "world size": Lines 309 to 310 in 82f5291 I wonder if the world size is the number of GPUs. Personally, I would check the value returned by world size with the debugger, and then try to lower the learning rate |
|
@woctezuma Thanks for the quick response, I also saw that the learning rate is scaled linearly w.r.t the total batch size (batch-size * num-gpus) I have tried lowering the lr by 4 times when training with 4 gpus, and got basically the same results (it did take about twice the epochs before the training becomes unstable with the lower lr) Some other combinations of lr, batch size, and gpu count also did not work (e.g: default/lower lr with 2 gpus, default/lower lr with 8 gpus with same/lower batch-size) |
|
@felix-do-wizardry Could you please share your logs file ? |
|
@aelnouby Sorry, our server is currently down for a few days, I'll try to grab the log and get back to you as soon as I can, |
|
@aelnouby hi, sorry for the delayed reply Here's the log for a run with 4-gpu lr=5e-4 bs=128 |
|
I have run the same command you used above:
The training seems to be behaving as expected, the logs are here: https://gist.github.com/aelnouby/540738cf88dda6a2fa5197915d1f2931 I am not sure where is the discrepancy. Could you try to re-run with a fresh clone of the repo and a fresh conda environment ? |
|
Most of my (unstable) runs were done with a completely fresh clone of the repo, |
Hi, I'm trying to reproduce the classification training results.
I tried on 2 different machines, machine A with one RTX 3090 and machine B with four A100 gpus.
The training on machine A with a single GPU is fine; see green line (with default parameters).
But on machine B with 4 gpus, it's not training properly and very erratic; see gray, yellow, teal lines (with default and custom parameters).
Purple line is DeiT training on the same machine B (default parameters).
All experiments done with --batch-size=128 (128 samples per gpu).
This is validation loss, other metrics tell the same story, some even worse.
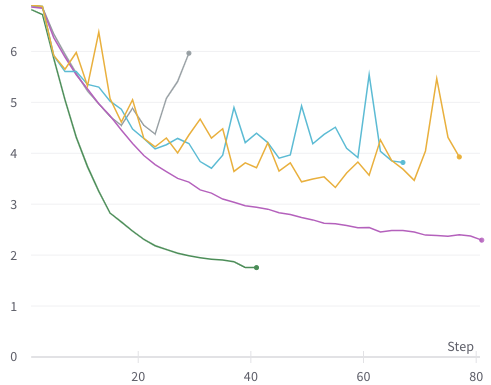
Example of the commands I used:
Anyone's seen this or know how to fix it? Many thanks.
The text was updated successfully, but these errors were encountered: