Loss stuck, not decreasing #27
Comments
|
Thanks for reporting.
|

|
Thank you very much for these hints. Actually, I think that the stage-wise optimization is the way to go. If I first optimize using SUM loss and then I resume, after 10 epochs, using MAX loss, the problem disappears and the validation metrics keep increasing smoothly. However, I will pay attention also to the batch size, as you suggested. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Hi, I'm noticing a very strange loss behavior during the training phase.

Initially, the loss decreases as it should be. At a certain point, it reaches a plateau from which most of the times cannot escape.
In particular, if I use pre-extracted features without fine-tuning the image encoder, the plateau is overtaken quite immediately, as show in the following plot:
However, if I try to fine-tune, the loss get stuck forever:

I noticed that the loss stuck on a very specific value, that is 2 * (batch_size * loss_margin).
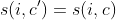
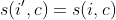
It seems that the loss is collapsing to values where the difference between positive and negative pair similarities is always 0:
and
I'm using margin = 0.2. For the pre-extracted features I used a batch size = 128, while for the fine-tuning the batch size = 32. The configuration is the very same as yours.
In general I noticed this behavior happening when the network is too complex.
Maybe the reason is that good hard negatives cannot be found if I use batch sizes less than 128. However, I have hardware constraints.
Did you notice a similar behavior in your experiments? If so, how did you solve?
Thank you very much
The text was updated successfully, but these errors were encountered: