- Objetivos
- Programación Dinámica
- Caminos Aleatorios
- Programas Estocásticos
- Simulaciones de Montecarlo
- Muestreo e Intervalos de Confianza
- Datos Experimentales
- Aprender a usar la Programacion Dinamica para hacer mas eficientes los problemas de optimizacion.
- Sabar como funciona la Programcion Dinamica y cuando usarla
- enternder la diferencia entre la programcion determinista y la estocastica
El nombre de Programcion Dinamica no tiene nada que ver con dinamismo, es simplemente un termino inventado por Richard Bell con la intencion de hacer parecer que su investigacion era la hostia para de esta manera conseguir financiacion del gobierno.
Es una de las tecnicas mas poderosa para optimizar problemas que cumplen con dos caracteristicas:
-
Subestructura optima: Caracteristica que consiste en que podemos solucionar un problema grande mediante la combinacio de soluciones pequeñas.
-
Problemas empalmados: Es una caracteristica segun la cual resolvemos un mismo problema una y otra y otra vez.
Por otro lado, la optimizacion nos permite hacer que nuestro programa se ejecute en mucho menos timepo, esto lo conseguimos mediante la memorizacion, lo cual consiste en guardar el resultado de computos anteriores para asi evitar tener que hacer los computos varias veces. Normalmente usamos un diccionario o cualquier estructura de datos que nos permite acceder a estos datos de una manera muy rapida, estas consultas las hacemos en O(1). Sin embargo, esta velocidad tiene un coste, y es que utilizaremos mas espacio en memoria.
La sucesion de Fibonacci es se trata de una secuencia infinita de números naturales; a partir del 0 y el 1, se van sumando a pares, de manera que cada número es igual a la suma de sus dos anteriores, de manera que:
La suceson de fibonacci es infeciente porque repetimos el mismo calculo un muchas veces.
import sys
def fibonacci_recursivo(n):
if n == 0 or n == 1:
return 1
return fibonacci_recursivo(n - 1) + fibonacci_recursivo(n - 2)
def fibonacci_dinamico(n, memo = {}):
if n == 0 or n == 1:
return 1
# Primero intentamos buscar el resultado en memoria.
try:
return memo[n]
# En caso de no existir realizamos el cálculo.
except KeyError:
resultado = fibonacci_dinamico(n - 1, memo) + fibonacci_dinamico(n - 2, memo)
memo[n] = resultado
return resultado
if __name__ == '__main__':
sys.setrecursionlimit(10002)
n = int(input('Escoge un numero: '))
resultado = fibonacci_dinamico(n)
print(resultado)Hasta el momento solo hemos hecho problemas deterministas, en los cuales para el mismo input siempre habia el mismo output. Sin embargo, tiene sus limitaciones para resolver algunos tipos de problemas, como por ejemplo la incorporacion de elementos aleatorios.
Una tipo de simulacion que vamos a estudiar son los caminos aletarios, en la cuales tenemos que elegir dentro de un conjunto de respuestas validas una respuesta aleatoria. En esta simulacion, a diferencia de los problemas deterministas, para cada input probablemente tengamos un output distinto. Un ejemplo en el que se utiliza este tipo de sumulaciones es para simular el comportamiento aleatorio de la bolsa.
Esta es una version mas sencilla de la simulacion de camninos de borrachos.
import random
from bokeh.plotting import figure, output_file, show
eje_x = [0]
eje_y = [0]
class Persona:
def __init__(self, x, y):
self.x = x
self.y = y
def mover(self, x, y, nueva_x, nueva_y):
self.x = nueva_x
self.y = nueva_y
return self.x, self.y
def tipo_movimiento(self):
movimientos = []
movimientos.append(random.choice([0, -1, 1]))
movimientos.append(random.choice([0, -1, 1]))
return movimientos
def caminata(Persona, simulaicones):
#creamos un objeto con la clase persona
caminante = Persona(0,0)
posicion = [(0,0)]
paso = 1
while paso <= simulaicones:
#estas coordenadas marcan el punto de partida del caminante
x = caminante.x
y = caminante.y
movimientos = caminante.tipo_movimiento()
#estas nuevas coordenadas marcan el lugar a donde ha llegado
#el caminante
nueva_x = x + movimientos[0]
nueva_y = y + movimientos[1]
if movimientos[0] == 0 and movimientos[1] == 0:
#no ejecutamos nada
pass
else:
caminante.mover(x,y,nueva_x, nueva_y)
posicion.append((nueva_x, nueva_y))
paso += 1
eje_x.append(nueva_x)
eje_y.append(nueva_y)
return posicion
if __name__ == '__main__':
simulaicones = int(input('cuantas veces quieres generar la simulacion?? '))
caminata(Persona, simulaicones)
fig = figure()
fig.line(eje_x,eje_y,line_width= 2)
show(fig)Hasta ahora todos los programas en los que hemos trabajado son deterministicos, es decir, con el mismo input obtengo el mismo output. Sin embargo, hay problemas que no puedo resolver programas deterministicos. En estos casos, podemos usar la programacion estocastica, la cual nos va a permitir introducir aletoriedad en nuestros programas lo que nos permitira resolver problemas mas complejos, como la simulacion en los mercados financieros.
La programacion estocastica toma partido de las distribuciones de probabilidad, que son el conjunto de todos los resultados posibles que puede tener una variable aleatoria, o en otras palabras, describe el comportamiento de dicha variable dentro de un intervalo de posibles resultados.
La probabilidad es una medida de la certidumbre que tenemos de si un evento futuro sucedera o no. La probabilidad generalmente se expresa como un numero entre 0 , jamas ocurrira, y 1, ocurrira con certeza.
A la hora de calcular probabilidades hay que tener un par de reglas presentes:
-Ley del complemento: Ley segun la cual la probabilidad de que ocurra un suceso mas la probabilidad de que no ocurra tiene que ser igual a uno.
-Ley multiplicativa: Es la probabilidad de que un evento suceda y otro evento suceda.
-Ley aditiva: Es la probabilidad de que A suceda o B suceda.
Calculamos este tipo de probabilidad sumando la probabilidad de los dos acontecimientos si son mutuamente exclusivos, es decir, que solo puede suceder uno a la vez.
Por otro lado, si las probabilidades no son exclusivas, es decir, que los dos acontecimientos pueden pasar simultaneamente lo calculamos de esta manera:
En el siguiente ejemplo añado la mi simulacion del lanzamiento de dos dados:
import random
class Dado:
def __init__(self, lado_1, lado_2, lado_3, lado_4, lado_5, lado_6):
self.lado_1 = lado_1
self.lado_2 = lado_2
self.lado_3 = lado_3
self.lado_4 = lado_4
self.lado_5 = lado_5
self.lado_6 = lado_6
def lado(self, simulaciones):
paso = 1
resultados = [ ]
while paso <= simulaciones:
resultados.append(random.choice([self.lado_1,self.lado_2,self.lado_3,self.lado_4,self.lado_5,self.lado_6, self.lado_1 + self.lado_1,self.lado_1 + self.lado_2,self.lado_1 + self.lado_3,self.lado_1 + self.lado_4,self.lado_1 + self.lado_5,self.lado_1 + self.lado_6,self.lado_2 + self.lado_1,self.lado_2 + self.lado_2,self.lado_2 + self.lado_3,self.lado_2 + self.lado_4,self.lado_2 + self.lado_5,self.lado_2 + self.lado_6,self.lado_3 + self.lado_1,self.lado_3 + self.lado_2,self.lado_3 + self.lado_3,self.lado_3 + self.lado_4,self.lado_3 + self.lado_5,self.lado_3 + self.lado_6,self.lado_4 + self.lado_1,self.lado_4 + self.lado_2,self.lado_4 + self.lado_3,self.lado_4 + self.lado_4,self.lado_4 + self.lado_5,self.lado_4 + self.lado_6,self.lado_5 + self.lado_1,self.lado_5 + self.lado_2,self.lado_5 + self.lado_3,self.lado_5 + self.lado_4,self.lado_5 + self.lado_5,self.lado_5 + self.lado_6,self.lado_6 + self.lado_1,self.lado_6 + self.lado_2,self.lado_6 + self.lado_3,self.lado_6 + self.lado_4,self.lado_6 + self.lado_5,self.lado_6 + self.lado_6]))
cara_1 = resultados.count(1)
cara_2 = resultados.count(2)
cara_3 = resultados.count(3)
cara_4 = resultados.count(4)
cara_5 = resultados.count(5)
cara_6 = resultados.count(6)
cara_12 = resultados.count(12)
paso += 1
print(f'El lado {self.lado_1} ha aparecido {cara_1}')
print(f'El lado {self.lado_2} ha aparecido {cara_2}')
print(f'El lado {self.lado_3} ha aparecido {cara_3}')
print(f'El lado {self.lado_4} ha aparecido {cara_4}')
print(f'El lado {self.lado_5} ha aparecido {cara_5}')
print(f'El lado {self.lado_6} ha aparecido {cara_6}')
print(f'El lado 12 ha aparecido {cara_12}')
probabilidad_1 = cara_1 / simulaciones
print(f'la probabilidad de que {self.lado_1} salga es de {probabilidad_1}')
#print(resultados)
probabilidad_12 = cara_12 / simulaciones
print(f'la probabilidad de que 12 salga es de {probabilidad_12}')
return resultados, cara_1,cara_2,cara_3,cara_4,cara_5,cara_6
if __name__ == '__main__':
simulaciones = int(input('cuantas veces quieres simular el lanzamineto?? '))
dado = Dado(1,2,3,4,5,6)
dado.lado(simulaciones)
con simulaciones podemos calcular la probabilidad de eventos complejos sabiendo las probabilidades de ejemplos sencillos, sin embargo, que pasa cuando no sabemos las probabilidades de los eventos sencillos??
En este caso es usar la inferencia estadistica para mediante la muestra de una poblacion cual sera el comportamiento de toda la poblacion. El principio principal de la inferencia estadistica es que la muestra de una poblacion tiende a exhibir el comportamiento de la poblacion original. No obstante, hay que tener en cuenta de que cuando hacemos estas estimaciones nos enfrentamos a un margen de error. Es importante recalcar que la muestra se toma de manera aleatorio porque si de lo contrario estariamos sesgando a la muestra.
Pero, como es que esto es posible??, esto es posible gracias a la ley de los grandes numeros. Segun esta ley cuando ejecutamos muchas veces un mismo evento independiente (cuando tendemos al infinito) la frecuencia de que suceda un cierto evento tiende a ser constante.
Falacia del apostador: Segun esta falacia, cuando un evento extremos sucede (ex: sacar veinte veces seguidas un seis en un dado) ocurriran otros eventos menos extremos para nivelar la media (ex: sacar veinte veces un uno). Esto es completamente falso.
Sin embargo, lo que es verdadero es la regresion a la media , segun la cual cuando ocurre un evento extremo, el siguiente evento probablementee sera menos extremo.
La media es una medida de tendencia central que nos perimite inferir donde se encuentran la mayoria de los valores de la poblacion. La media de una poblacion normalmente se denota μ, mientras que la media de una muestra se denota como x̄.
La media se calcula dividiendo la suma total de todos los valores por la cantidad de valores.
El siguiente es un ejemplo de como calcular la media de un conjunto de nuemeros usando Python.
import random
def media(X):
return sum(X) / len(X)
if __name__ == '__main__':
X = [random.randint(9, 12) for i in range(20)]
mu = media(X)
print(f'Arreglo X: {X}')
print(f'Media = {mu}')La varianza y la desviacion tipica nos indican que tan separados estan los datos. Siempre que hablamos de varianza y de desviacion tipica en ralacion con la media, es decir, comparandola con la media.
Para calcular la varianza lo que hacemos es calcular la diferencia entre cada valor y la media, elevarlo al cuadrado y hacer el mismo proceso con todos los elements de la muestra. Una vez hemos hecho esto, simplemente dividimos por el tamaño de la muestra.
La desviacion estandar es la raiz cuadrada de la varianza. La ventaja de que sea la raiz cuadrada de la varianza es que nos da la misma unidad que la media (la varianza nos da las unidades al cuadrado), lo que nos permite hacer comparaciones.
def varianza(X):
mu = media(X)
acumulador = 0
for x in X:
acumulador += (x - mu) ** 2
return acumulador / len(X)
def desviacion_estandar(X):
return (varianza(X)) ** 0.5
if __name__ == '__main__':
X = [random.randint(9, 12) for i in range(20)]
mu = media(X)
var = varianza(X)
desv = desviacion_estandar(X)
print(X)
print(f'la media es {mu}')
print(f'la varianza es {var}')
print(f'la desviacion estander en {desv}')La distribucion normal es una de las ditribuciones de probabilidad de variable continua que aparece con mayor frecuaencia en estadistica. Las distribuciones de probabilidad son funciones que asigna a cada suceso la probabilidad de que dicho suceso ocurra, y de variable continua se refiere a aquellas variables que puede tomar cualquier valor dentro del numero infinito de valores dentro de un intervalo.
La distribucion normal se puede definir completamente mediante su media y su desviacion estandar, es decir, si sabemos la media y la desviacion estandar podemos calcular la distribucion normal. La distribucion normal nos permite calcular la probabilidad de que algo suceda usando la regla empirica, la cual veremos con posterioridad.
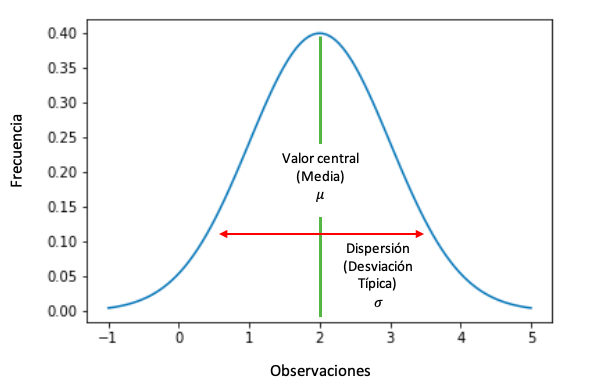
como podemos apreciar en la imagen la distribucion normal es simetrica respecto de su media.
Con repescto a la regla empirica que nombramos anteriormente debemos saber que tambien la podemos conocer con la regle 68-95-99,7. Esta regla nos permite analizar como se distribuyen dentro de una distribucion normao los datos, esto lo hacemos analizanado los datos que podemos encontrar a una desviacion tipica de distancia con repecto de la media, a dos desviaciones tipicas y a tres desviaciones tipicas.
Las simulaciones de montecarlo es un metodo estadistico utilizado para resolver problemas matematicos complejos mediante la generacion de variables aleatoria. Un metodo estadistico es una secuencia de procedimientos para el manejo de datos cualitativos y cuantitativos en una investigacion.
Las simulaciones de montecarlo nos permite crear simulacones para predecir el resultado de un problema, tambien nos permite convertir un problema deterministico en problemas estocasticos.
import random
import collections
#generar barajas, las variables las nombre en mayusculas
#porque es una convencion
PALOS = ['espada','corazon','rombo','trebol']
VALORES = ['as','2','3','4','5','6','7','8','9','10','jota','reina','rey']
#funcion para generar la baraja
def crear_baraja():
barajas = [ ]
for palo in PALOS:
for valor in VALORES:
barajas.append((palo,valor))
return barajas
#ahora creamos una funcion para obtener una mano
def obtener_mano(barajas, tamaño_mano):
#la funcion random.sample escoge una muestra aleatorio de barajas
#y el tamaño de la mano le indica cuantas barajas vamos
#a obtener
mano = random.sample(barajas, tamaño_mano)
return mano
#funcion para encontrar las probabilidadeas de los pares en
#una barja
def par(valores_acumulados):
for val in valores_acumulados:
if val == 2:
return 1
#retorna cero al finalizar el ciclo
return 0
def main(tamaño_mano, intentos):
#creamos una baraja
baraja = crear_baraja()
#guarda todas las manos que obtengamos en la simulacion
manos = [ ]
for _ in range(intentos):
mano = obtener_mano(baraja, tamaño_mano)
manos.append(mano)
#ahora vamos a calcular la probabilidad de que nos salga
#un par dentro de una mano de cualquier tamaño
# pares = 0
for mano in manos:
valores = [ ]
for carta in mano:
valores.append(carta[1])
counter = dict(collections.Counter(valores))
for val in counter.values():
#es exactamente dos porque si una carta aparece
#exactamente dos veces es un par
if val == 2:
pares += 1
#si encontramos un par ya dejamos de buscar
#porque solo queremos encontrar dos
break
probabilidad_pares = pares / intentos
return f'la probabilidad de encontrar un par dentro de una mano es de {tamaño_mano} barajs es {probabilidad_pares}'
if __name__ == '__main__':
barajas = crear_baraja()
tamaño_mano = int(input('de que tamaño quieres que sea el tamaño de la mano?? '))
intentos = int(input('cauntas veces quieres generar la simulaicon?? '))
#mano = obtener_mano(barajas, tamaño_mano)
print(main(tamaño_mano, intentos))Calcularemos PI con puntos al azar esparcidos en un plano cartesiano utilizando los scripts de desviación estándar y media que creados anteriormente. Queremos tener un 95% de certeza, entonces para ello realizaremos el cálculo para 1/2 del área de un circulo, optimizando nuestros recursos.
import random
from varianza import desviacion_estandar
def aventar_agujas(numero_agujas):
dentro_del_circulo = 0
for _ in range(numero_agujas):
#random nos retorna un valor entre cero y uno. Pero
#lo que queremos es obtener es uno o menos uno de forma
#aleatoria, para ello lo que hacmeos es que lo multiplicamos
#de forma aletaria por uno o menos uno
x = random.random() * random.choice([1,-1])
y = random.random() * random.choice([1,-1])
distancia_desde_el_centro = (x**2 + y**2)**0.5
if distancia_desde_el_centro <= 1:
dentro_del_circulo += 1
# elif distancia_desde_el_centro < 1:
# dentro_cuadrado += 1
return (4 * dentro_del_circulo) / numero_agujas
#las veces que vamos a correr la simulacion
def estimacion(numero_agujas, numero_intentos):
estimaciones_pi = [ ]
for _ in range(numero_intentos):
estimacion_pi = aventar_agujas(numero_agujas)
estimaciones_pi.append(estimacion_pi)
media_estimados = sum(estimaciones_pi) / len(estimaciones_pi)
sigma = desviacion_estandar(estimaciones_pi)
return (media_estimados, sigma)
#en esta estimacion le meto una aproximacion al calculo
def estimar_pi(precision, numero_intentos):
numero_agujas = 1000
sigma = precision#inicializamos sigma en precision
while sigma >= precision/1.96:
media, sigma = estimacion(numero_agujas, numero_intentos)
numero_agujas *= 2
return media
if __name__ == '__main__':
print(estimar_pi(0.01, 10))Sin embargo, gracias a los aportes que encontré en esta clase me anime a realizar un script para visualizar todas la simulaicón, este es el resultado:
import random
from varianza import desviacion_estandar
from bokeh.plotting import figure, output_file, show
numero_agujas = int(input('con cuantas agujas quieres correr la simulacion?? '))
in_circle_x = [ ]
in_circle_y = [ ]
out_circle_x = [ ]
out_circle_y = [ ]
dentro_del_circulo = 0
for _ in range(numero_agujas):
x = random.uniform(1,-1)
y = random.uniform(1,-1)
if (x**2 + y**2) ** 0.5 < 1:
in_circle_x.append(x)
in_circle_y.append(y)
dentro_del_circulo += 1
else:
out_circle_x.append(x)
out_circle_y.append(y)
#pi = (4 * dentro_del_circulo) / numero_agujas
output_file("line.html")
plot = figure(plot_width=600, plot_height= 600)
plot.circle(in_circle_x, in_circle_y, size=5, color='blue', alpha=0.5)
plot.circle(out_circle_x,out_circle_y,size=5, color='red',alpha=0.5)
show(plot)Este es la visualizacion obtenida:

El muestreo es el proceso mediante el cual obtenemos una muestra de una poblacion con la finalidad de estimar valores o corroborar hipótesis. El muestreo es importante cuando por ejemplo no tenemos la capacidad de computo suficiente para hacer todos los calculos.
Es importante saber que las muestras tienden a tener el mismo comportamiento de la poblacion original, gracias a esto podemos llegar a conclusiones validas para la poblacion original.
Hasta ahora el tipo de muestreo que hemos utilizado es el muestreo probabilistico, el cual consiste en seleccionar la muestra de forma aleatoria. Este tipo de muestreo tiene dos formas principales de usarse:
-En un muestreo aleatorio: en este tipo de muestreo cualquier miembro de la poblacion puede ser escogido con la misma probabilidad. Este tipo de muestreo lo deberiamos hacer cuando la poblacion tiene caracteristicas similares.
-En un muestreo estratificado: en este tipo de muestreo primero se divide a la poblacion en subgrupos para despues seleccionar aleatoriamente a miembros de estos subgrupos. Esto se realiza con la finaidad de evitar sesgos en la investigacion. Este tipo de muestreo lo deberiamos realizar cuando existen subgrupos dentro de nuestra poblacion.
Este teorema nos permite convertir culaquier tipo de distribucion a la distribucion normal. El teorema funciona de la siguiente manera, de una poblacion de la cual no sabemos su distribucion cogemos una muestra de tamaño n y sacamos la media de dicha muestra. Repetimos este proceso unas cuantas veces y como el teorema del limite central me dice que si el tamaño de la muestra es suficientemente grande, la distribucion de esas medias muestrales va a ser aproximadamente la distribucion normal. Esto quiere decir que cuanto mayor sea el tamaño de la muestra, la distribucion de esas medias muestrales va a tender a ser normal con mayor exactitud.
Los datos experimentales son aquellos que obtenemos al realizar un experimento, los obtenemos mediante el metodo científico. Cuando hablamos del metodo cientifico siempre es necesario empezar con una teoria que queremos validar o demostrar que es falsa. Una vez ya hemos identificado nuestra teoria, el siguiente paso es realizar experimentos que nos permitan verficar o falsear nuestra hipotesis.
La regresion lineal es una tecnica que nos permite aproximar una funcion a un conjunto de datos obtenidos de manera experimental.
En el siguiente ejemplo podemos ver la implementacion de la tecnica de regresion lineal usando jupyter notebooks: Collab - Regresión Lineal.