- Gartner2021 Network Detection and Response市场报告
-
标准入侵检测的发展、意义、评价指标、关键技术、检测框架、代表应用等。
-
CICflowmeter是一款流量特征提取工具,该工具输入pcap文件,输出pcap文件中包含的数据包的特征信息,共80多维,以csv表格的形式输出。具备java和python两个版本,python版本可以直接通过
pip install cicflowmeter进行安装。该工具提取的都是传输层的一些统计信息,且特征均区分正向以及反向,以一个TCP流或一个UDP流为一个单位。TCP流以FIN标志为结束,UDP以设置的flowtimeout时间为限制,超过时间就判为结束。 具体工作原理如下:
从pcap文件中逐个读取packet,将每个数据包添加到对应的流中在currentFlows存储当前还未结束得所有TCP、UDP流。在添加的过程中不断地更新每个流的统计特征,最终将统计特征写入csv文件。判断新加入的数据包是否属于当前所有未结束的流,如果属于当前流则判断正向还是反向,之后判断时间是否超时、不超时则判断是否含有FIN标志,如果两者都不满足,则声明一个BasicFlow对象,根据id从currentFlows中拿到与当前数据包对应的流,调用addPacket将该数据包加入到对应流中。如果前面判断不在当前所有未结束的流中,则直接创建一个新得流,里面只含当前数据包,存入到currentFlows中。如果属于当前某个未结束的流,且超时或存在FIN标志,则说明当前flow结束,超时则从currentFlows中移除对应流,新建flow存入currentFlows中,含FIN标志则直接从currentFlows中移除对应流。结束的flow直接调用onFlowGenerated函数将流打印存储起来。
-
使用某银行应用中的数据集进行HTTP Web攻击检测模型项目。该项目检测对象为HTTP流量,具有的一个比较特别的点是在训练阶段不使用攻击样本,而只使用正常样本,是一种类似异常检测思路,而不是大部分人使用的分类的方式。
-
基于HMM的Web异常参数检测项目。
-
KDD大赛的一个竞赛项目,主要目的是使用机器学习得手段建立一个入侵检测器。其中的入侵行为主要包括:DDOS、密码暴力破解、缓冲区溢出、扫描等多种攻击行为。数据格式为一些基本的统计信息。
-
该数据集来自加拿大新不伦瑞克大学的加拿大网络安全研究所,与前面的入侵检测数据集最大的不同点在于该数据集改变了原有的静态数据集一次检测的方式转变为动态生成一段时间内每天的动态数据,IDS 2012数据集中只包含原始pcap数据,从2017开始还包含了使用提出的特征生成工具CICFlower。
数据集 攻击类型 CIC IDS 2012 内部渗透、HTTP Dos、Ddos、SSH爆破 98G CIC IDS 2017 常见Dos(DoS slowloris、DoS Slowhttptest、DoS Hulk、DoS GoldenEye)、Web攻击(暴力破解、XSS、SQL注入)、渗透(Dropbox下载、Portscan + Nmap)、僵尸网络、端口扫描、DDos 55G CIC IDS 2018 常见Dos(Slowloris、Slowhttptest、Hulk、GoldenEye、心脏滴血)、Web攻击(DVWA、XSS和暴力破解)、渗透(Dropbox下载、Portscan + Nmap)、僵尸网络(ARES:远程shell、上传下载、屏幕捕获、登录秘钥窃取)、DDoS+PortScan 298G
一个总结各种与安全数据相关的数据集的网站。数据格式也非常多样。
-
该博客一个比较全面的HTTP流量日志分析系统,是一个比较详细的系统设计,检测部分包括了规则匹配、统计特征检测、机器学习检测三种方法,机器学习部分采用了tf-idf+ngram等方式进行向量化然后使用SVM进行检测。是一种非常基础非常简单的安全和AI结合的实践。
-
数据科学在Web威胁感知中的应用【阿里云-楚安】
楚安大佬在AI安全领域的一篇非常经典的博客。
-
学点算法搞安全之HMM【百度-兜哥】
兜哥写的一篇关于HMM用于Web参数异常检测的一篇论述性的文章,并附带了一些基本实现。HMM应用于Web参数异常检测核心思想为使用大量白样本构建HMM模型,使模型能够正确识别正常参数的形式,然后对于新的请求参数使用该HMM模型进行判别,根据得出的概率值判断是否为异常参数。在实际使用中存在的问题也比较明显,HMM模型要每个URL都要训练一个HMM模型,因此检测的成本巨大,只能用于小站点的防护。
-
该博客为写成在将机器学习应用到携程的恶意攻击检测系统中的企业实践,整个文章论述了将机器学习应用到入侵检测系统中的整体思路以及遇到的各种问题及解决方法。里面一些比较精彩的点:
-
该文章将机器学习模型主要用来做效率优化,构建低误报的模型来进行数据的过滤,然后再使用正则进行确定是否为攻击。
-
整个系统先使用白名单机制来过滤掉97%的流量。在param的value部分不包含符号、控制符以及白名单IP的流量都可直接视为白数据。
-
机器学习和正则都判为黑的发送到自动化验证系统验证能否攻击成功。
-
-
企业安全数据分析实践与思考【阿里-cdxy】
阿里cdxy大神关于阿里巴巴在将数据分析技术应用到企业安全中的一些思路的分享ppt,配套讲解视频。里面有一些做法还是比较特别的。
- 多层日志进行协同进行是否成功入侵判别。
- 多层日志协同进行自动化事件完整过程建模,快速追踪(入侵链路可视化)。
- 随着数据的积累,安全数据分析将基于图结构的高级知识表达方式发展。
-
利用机器学习检测HTTP恶意外连流量【360云影实验室】
360云影实验室
-
WAF建设运营及AI应用实践【腾讯】
本文较为透彻的讲解了腾讯在进行WAF建设的思路、部署位置等,并且讲述了AI在整个WAF系统中所起的作用。其中比较记忆深刻的点:1.在流量到来时,应当使用多种方式来对流量进行初筛,流量中正常流量与恶意流量的比例为10000:1,应当先过滤掉绝对正常的流量。提到的方法为:先过滤掉公司自己的出口IP,再过敏感攻击特征关键字进行字符串匹配,筛选出疑似流量。 2.对于xss这类语法较为明显的攻击,采用antlr4作为词法分析器和文法分析器进行分析,判断是否符合语法。 3.对于判断符合js语法的请求进一步使用hmm来进行打分,判断是否为xss攻击
-
门神WAF众测总结【腾讯】
腾讯门神WAF进一步完善的一个众测策略,比较有借鉴意义的一个WAF完善方式。文章中比较详细的分析了整个众测过程中成功绕过门神WAF的各种攻击,对这些攻击按照攻击所针对防御策略预处理阶段、词法分析阶段、语法分析等不同阶段进行分析,但是并为直接给出完善措施,需要自己去思考。
-
蚂蚁金服在研究只有少量已经标注的正样本和大量无标注样本时,使用PU-Learning(Positive Unlabled Learning)进行恶意URL检测的原理、效果介绍。核心就是其中PU-Learning的具体做法,使用two-stage strategy(两个阶段,先进行训练模型,然后根据已有数据找阈值将数据进行标注)和cost-sensitive strategy(正例与负例误分类采用不同惩罚系数的损失函数),声称已经通过这个模型发现了新的攻击模式,值得尝试一下的策略。
-
腾讯网站管家WAF在AI WAF方向的实践经验,本文不包含一些具体的技术细节,主要是构建AI WAF的一些大体思路。1.提出降低漏报、误报的思路:two-stage法,第一阶段使用无监督的聚类来进行异常检测(声称可以实时,但是聚类如何进行实时,推测是一个准实时的算法),然第二阶段使用监督学习的方式来将第一阶段监测为异常的作为黑样本数据来进行模型训练。
-
强化学习用于入侵检测的一篇博客,是一家智能身份认证公司博客中发出的,该文章使用openAI Gym和NSL-KDD数据进行构建了一个虚拟环境,训练强化学习系统使其能够对连接进行判断是否为攻击。其中还是存在比较明显的缺陷。首先在该文章所采用的的方法中,RL的action为对连接打正常标记与异常标记两种,而这两种action并不能对state产生任何影响,不符合一个RL系统的基本要求,因此这种建模方式十分不推荐。
-
Davide, Ariu, and, et al. "HMMPayl: An intrusion detection system based on Hidden Markov Models[J]" pdf.(HMM用于Web参数检测)
-
2020年最新AI-IDS用于入侵检测的应用型论文,论文中对从2017年以来对AI在IDS方向上的应用做了系统性的总结,然后提出了作者在AI-IDS应用到实际生产环境中的方法。比较有参考意义的一论文。文章的主要亮点在于:1.可拓展性,能够根据需求不断进行拓展 2.应用性强 3.对以往研究的总结很全面 4.使用实例展示了AI-IDS在未知威胁检测方面的能力。
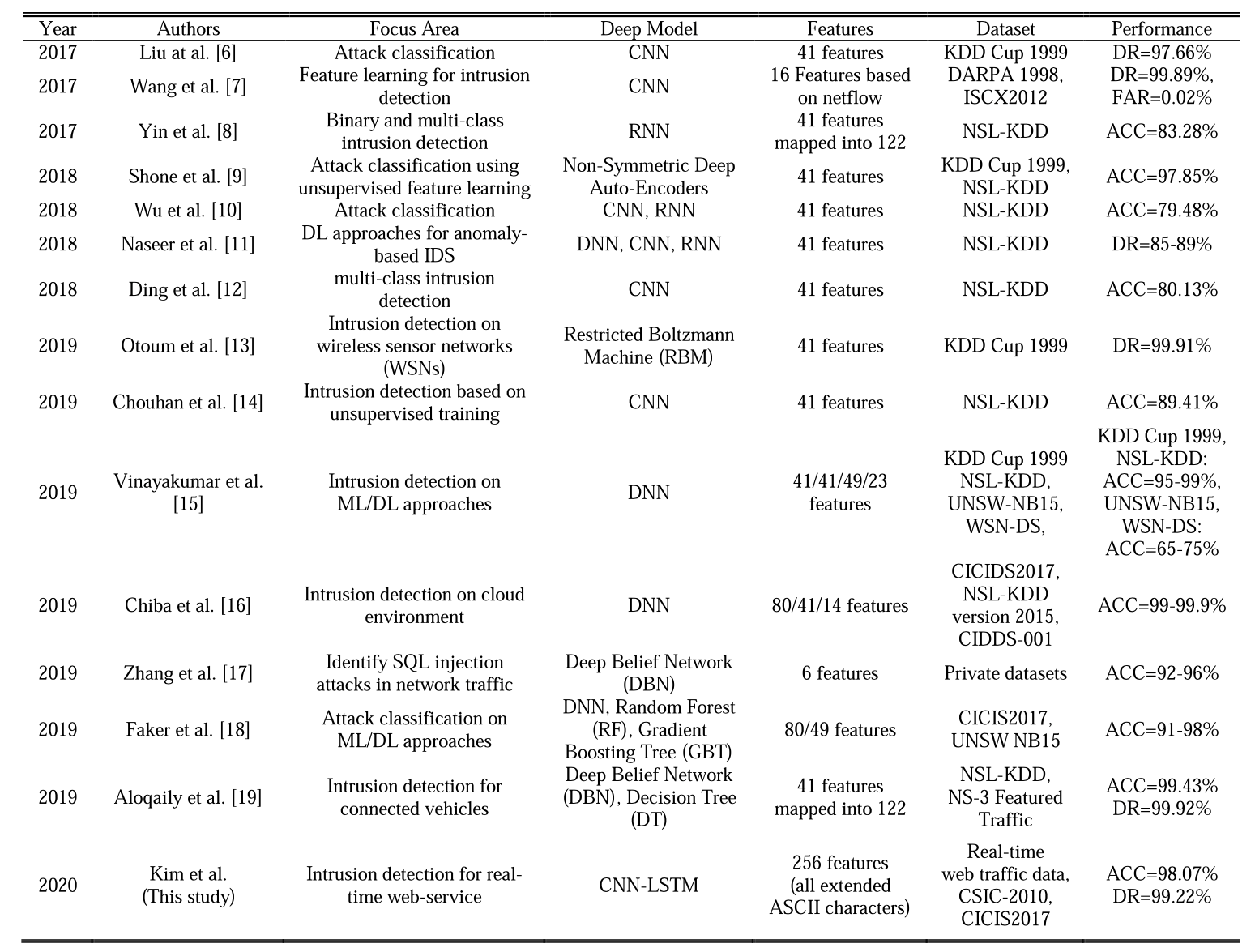
文章中一些一些观点与我们在实践中的思路不谋而和:
-
AI-IDS要与传统IDS并行运行,传统IDS作为IDS的一个评判标准
-
在模型上线的初期,预测的结果并不可靠,需要长期维护模型达到稳定后才可以信任模型
-
AI-IDS产生的安全事件只保留排除掉传统IDS的那一部分,剩下的才重点研究
-
固定的时间后,会根据产生的安全事件完善已有的传统IDS
建模过程中的一些特殊点:
- 采用标准化的UTF-8编码对数据进行编码,将每个字符的表示范围控制在(-1.1), ys = −(ys − 128)/128,据说是因为这样可以训练更加迅速
-
-
阿里云安全高级工程师周涛在RSA 2019上对入侵检测在阿里安全领域时间进行的经验分享,其中比较有趣的点在于:
-
入侵检测多阶段检测:正常流量过滤->已知威胁检测 -> 告警事件关联。
-
面对统计学习与机器学习误报的问题以及告警数据量过多的问题,提出了使用有向图进行告警关联,将告警聚合成为告警事件,方便安全运维人员进行人工核验,将告警从每天3000条下降到每天告警事件数量在100个以下。
-
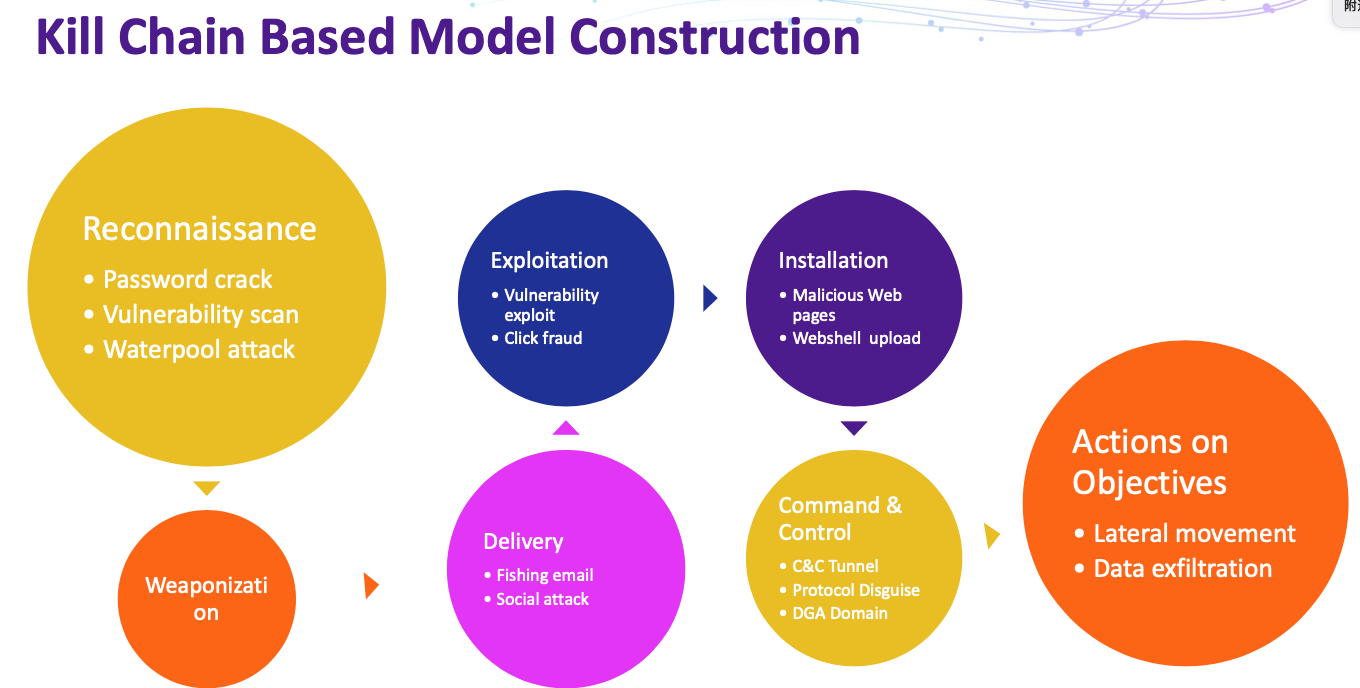
使用kill Chain中不同阶段数、威胁设计的网络分布、各个告警模型的准确率进行风险评估。
-
2018年对企业中的域名安全进行风险评估(主要是针对C&C域名),利用先验知识提取流量自身内部特征和外部拓展特征共89中,流量自身内部特征分为通讯特征、域名特征、URL特征、UA特征、返回码、referer特征、Content-type特征,外部特征包括WHOIS特征、Host类型特征、Geolocation特征,然后对域名为恶意域名的概率进行评估,作为其风险值。论文作者使用3个月的企业数据作为训练集,然后使用1个月的数据作为时间窗口进行统计,作为测试集,研究人员主要人工对top100域名进行人工核验,其中97个为恶意域名,并且virtual只能发现72个,证明系统具有较强的未知风险发现能力。
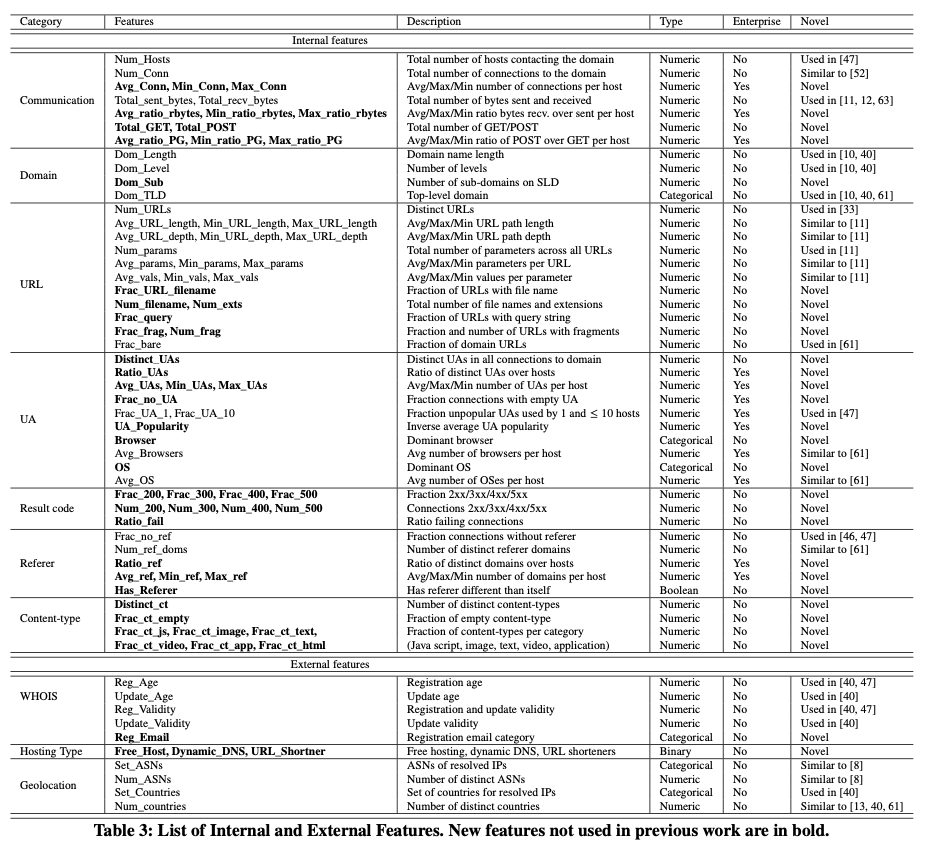
该论文提出的方法主要应用于企业内部,使用的比较全面的方法进行数据过滤,极大的减轻了数据的标注与处理压力,其中包含的过滤方法主要包括:
- 只关注最近新出现的域名:这种过滤方法基于三种认知,1.恶意域名大多都具有较短的生命周期 2. 长时间存在的域名大概率都已经包含在已知的威胁情报中 3. 论文更加关注新的恶意趋势
- 域名流行度:排除掉每天企业中访问主机数量最多的50个域名
- CDN域名
- 合法广告流量
- 连接量很少的域名:改文章主要关注点在于C&C域名,因此很大程度上在一个月的时间内连接数不会少于5次