| layout | title | comments | author | excerpt | picture |
|---|---|---|---|---|---|
post |
Collaborative Filtering with Neural Networks |
true |
florian-strub |
Collaborative Filtering methods are key algorithms for Recommender Systems. They are used by major companies such as Netflix, Amazon or Spotify to suggest items to users. While Neural Networks have tremendous success in image and speech recognition, Collaborative Filtering received less attention as it deals with sparse inputs/targets. After a quick introduction to Recommendation Systems, we show how to implement a well-defined Autoencoders to perform Collaborative Filtering. |
Deep Learning has well-known state-of-the-art results in Computer Vision, Speech Recognition or Natural Language Processing. This post intends at using Neural Networks on a different topic : Recommender systems and Collaborative Filtering. It turns out that a well-defined Autoencoder can compete with the best Collaborative Fitering algorithms. This post focus on understating and implementing such Autoencoders.
#Collaborative Filtering#
Recommendation systems are a subclass of algorithms that seek to predict the rating that a user would give to an item. A good recommendation system may dramatically increase the amount of sales of a firm or retain customers. For instance, 80% of movies watched on Netflix come from the recommender system of the company.
One of the most successful approach of Recommendation systems is to use the explicit feedback of users to build a Matrix of ratings. This technique is known as Collaborative Filtering.
For instance, if we gather the feedback of movies of all users into a matrix, we obtain a sparse matrix of ratings. Note that the sparsity is induced by unknown values.
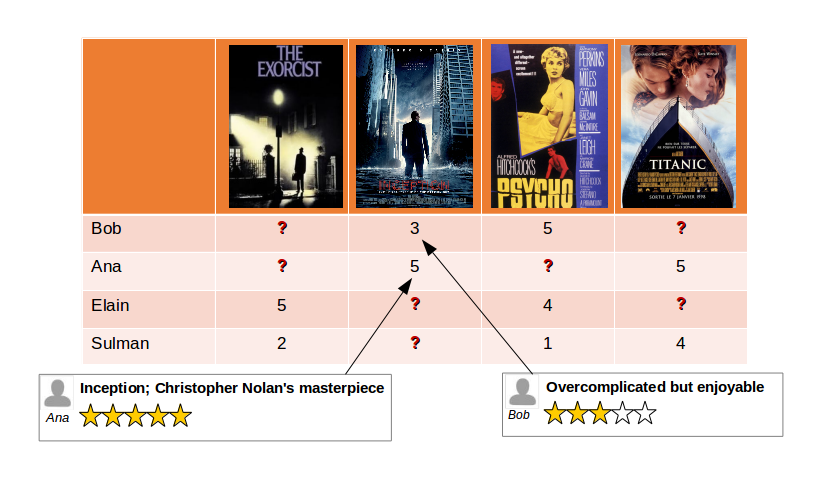
In this case, should we recommend Bob to watch The Exorcist or Titanic?
Collaborative Filtering aims at estimating the ratings a user would have given to other movies by using the ratings of all the other users. Inherent features of users or items such as the genre, age, actors or some descriptions are not taken into account. The goal is then to turn the previous sparse matrix of ratings into a dense one:

Therefore, the Recommender System will advise Bob to watch The Exorcist.
If Bob eventually rates The Exorcist, the matrix is re-estimated and so on... In practice, the matrix of ratings is very sparse. IMDB currently indexes around 1,7 millions movies while users rarely rate more than a few hundreds movies.
I would recommend the following paper [1] to curious people which provide a great insight regarding the challenges of the field (Latent factors, Cold-Sart Problem, Hybrid Systems etc.)
In this post, we will introduce a Collaborative Filtering approach based on Stacked Denoising Autoencoders. A preliminary (and excellent!) work was first pulished in 2007 by Ruslan Salakhutdinov [2].
As a short reminder, Autoencoders are unsupervised Networks where the output of the Network plan to reconstruct the initial input. The Network is constrained to use narrow hidden layers, forcing a dimensionality reduction on the data.
In a Collaborative Filtering task, the goal is to turn the sparse matrix of ratings into a dense one. To do so, we are going to decompose the matrix by either its lines or columns and feed them to the Autoencoder. The output layer will reconstruct the lines/columns and complete them.

Note that the input/output size will depend on the matrix dimension.
Before implemeting the Autoencoder, we need to define how to handle unknwon values.
In the forward pass, a naive but efficient approach is to turn unkwown values into zero values. This is strictly equivalent to removing the neurons from the network. In other words, unknown values are ignored.
In the backward pass, the same idea can be applied. When no rating exist, the error is set to zero as it cannot be computed.

At first sight, there is very few constraint in such Autoencoders. Actually, dropout already removed 50% of the weights. Beware that more than 95% of the ratings are missing in real datasets. Thus, the bottleneck of the autoencoder is often greater than the number of ratings in the input vector! If we change the toys example by a bit more realistic autoencoder. It is not straightfroward that the network will be able to learn a useful representation from a very sparse representation.

The autoencoder is acctually diverted from its original purpose. It does not aim to reconstruct the initial input anymore, it aims at predicting the missing data.
By keeping this idea in mind, we applied the Denoising loss [2] to emphasize the prediction aspect during the training. First, a few input ratings are masked on every input vector to simulate missing ratings. And then, a higher error is returned when the output rating is erroneously predicted.
The training loss becomes

where \tilde{x} is the corrupted input x, J are the indices of the corrupted elements of x, nn(x)_j is the jth output of the Network, K(x) are the indices of known values of x. The loss is based on two main hyperparameters Alpha, Beta. They balance the evolution of the Network between denoising the input (alpha) and reconstructing the input (beta).
Finally, the full training process is described below

A more advanced description is described in our paper [4]). Importantly, we explain in this paper the underlying idea that links classic Collaborative Filtering techniques and Autoencoders and propose ideas that may explain why neural Networks performs well in Collaborative Filtering tasks.
Now, let's start the interesting part!
First, we need to install the nnsparse package. It will provide us with the basic tools to handle sparse data.
luarocks install nnsparse
We are going to work on a small but classic dataset called movieLens-1M. This dataset contains 1 million ratings from 1 to 5 given by 6040 users on 3700 movies.
To avoid memory overflow, data must be stored in sparse tensors. Given the toy matrix in the first section, the sparse matrix of users/items would be:

{kind=link}
The following code parses the movieLens-1M dataset and turns it into a sparse reprensation of items
local train, test = {}, {}
-- Step 1 : Load file
local ratesfile = io.open("ml-1m/ratings.dat", "r")
-- Step 2 : Retrieve ratings
for line in ratesfile:lines() do
-- parse the file by using regex
local userIdStr, movieIdStr, ratingStr, _ = line:match('(%d+)::(%d+)::(%d%.?%d?)::(%d+)')
local userId = tonumber(userIdStr)
local itemId = tonumber(movieIdStr)
local rating = tonumber(ratingStr)
-- normalize the rating between [-1, 1]
rating = (rating-3)/2
-- we are going to autoencode the item with a training ratio of 0.9
if torch.uniform() < 0.9 then
train[itemId] = train[itemId] or nnsparse.DynamicSparseTensor()
train[itemId]:append(torch.Tensor{userId, rating})
else
test[itemId] = test[itemId] or nnsparse.DynamicSparseTensor()
test[itemId]:append(torch.Tensor{userId, rating})
end
end
-- Step 3 : Build the final sparse matrices
for k, oneTrain in pairs(train) do train[k] = oneTrain:build():ssortByIndex() end
for k, oneTest in pairs(test) do test[k] = oneTest:build():ssortByIndex() end
It is important to unbias the lines/columns by the training mean to increase the final results.
-- Step 4 : remove mean
for k, oneTrain in pairs(train) do
local mean = oneTrain[{ {},2 }]:mean()
train[k][{ {},2 }]:add(-mean)
test[k] [{ {},2 }]:add(-mean)
endWe will first implement a shallow Autoencoder with sparse inputs for items. Deeper Autoencoder can be used, but the final results will only be increased by a small margin. So let's keep things simple!
- On CPU:
local network = nn.Sequential()
network:add(nnsparse.SparseLinearBatch(6040, 500)) --There are 6040 users in movieLens-1M
network:add(nn.Tanh())
network:add(nn.Linear(500, 6040))
network:add(nn.Tanh())- On GPU:
local network = nn.Sequential()
network:add(nnsparse.Densify(6040)) --GPU does not handle sparse data, so we densify the input on the fly
network:add(nn.Linear(6040, 750))
network:add(nn.Tanh())
network:add(nn.Linear(750, 6040))
network:add(nn.Tanh())
network:cuda()As described above, training the autoencoder requires to use a Denoising Loss.
The nnsparse package offers a full Denoising Loss (Gaussian Noise/Masking Noise/ Salt&Paper Noise) for CPU and a Masking Loss that both work on CPU/GPU.
We will use the latter since we want to focus on the prediction aspect.
-- define the Loss function
lossFct = nnsparse.MaskCriterion(nn.MSECriterion(), {
alpha = 1,
beta = 0.5,
hideRatio = 0.25,
})
lossFct.inputDim = 6040 --require for sparse inputs
lossFct.sizeAverage = false
-- Create minibatch
local input, minibatch = {}, {}
--shuffle the indices of the inputs to create the minibatch
local shuffle = torch.randperm(inputSize)
shuffle:apply(function(k)
if train[k] then
input[#input+1] = train[k]
if #input == batchSize then
minibatch[#minibatch+1] = input
input = {}
end
end
end)
if #input > 0 then
minibatch[#minibatch+1] = input
end
-- Classic training
local w, dw = network:getParameters()
for _, input in pairs(minibatch) do
local function feval(x)
-- Reset gradients and losses
network:zeroGradParameters()
-- AutoEncoder targets
local target = input
-- Compute noisy input for Denoising autoencoders
local noisyInput = lossFct:prepareInput(input)
-- FORWARD
local output = network:forward(noisyInput)
local loss = lossFct:forward(output, target)
-- BACKWARD
local dloss = lossFct:backward(output, target)
local _ = network:backward(noisyInput, dloss)
-- Return loss and gradients
return loss/batchSize, dw:div(batchSize)
end
sgdConfiguration.evalCounter = t
optim.sgd (feval, w, sgdConfiguration )
end Torch criterions do not handle sparse targets by default. Thus, it is necessary to wrap them into another criterion.
The nnsparse.SparseCriterion takes a dense output and a sparse target as parameters.
It then computes the loss/dloss regarding the indices of the target.
-- Create minibatch
local noRatings = 0
local input, target, minibatch = {}, {}, {}
for k, _ in pairs(train) do
if test[k] ~= nil then --ignore when there is no target
input [#input +1] = train[k]
target[#target +1] = test[k]
noRatings = noRatings + test[k]:size(1)
if #input == batchSize then
minibatch[#minibatch+1] = {input = input, target = target}
input, target = {}, {}
end
end
end
if #input > 0 then
minibatch[#minibatch+1] = {input = input, target = target}
end
-- define the testing criterion
local criterion = nnsparse.SparseCriterion(nn.MSECriterion())
criterion.sizeAverage = false
-- Compute the RMSE by predicting the testing dataset thanks to the training dataset
local err = 0
for _, oneBatch in pairs(minibatch) do
local output = network:forward(oneBatch.input)
err = err + criterion:forward(output, oneBatch.target)
end
err = err/noRatings
print("Current RMSE : " .. math.sqrt(err) * 2) -- The RMSE is rescaledHere we are! The shallow autoencoder can be trained.
The full code can be found here.
A more advanced implementation can be found here.
For movieLens-1M, the network should be trained in a few minutes (~20 epoches). The final RMSE should be around 0.839 with the following hyperparameters. Deeper Networks can go up to a RMSE of 0.831.
local sgdConfiguration = {
learningRate = 0.07,
learningRateDecay = 0.9,
weightDecay = 0.05,
}As a benchmark, Alternative Least Squares [3] is a widely used Collaborative algorithm. It has a final RMSE around 0.850 on movieLens-1M - cf Mahout + Script
Furthermore, the bigger is the dataset, the better will be the Autoencoder. The current state of the art results can be obtained with a shallow autoencoder for movieLens-10/20M.
Once you have your network, you are free to implement your recommendation system!
More advanced Network can be built to integrate side information such as movie tags, age/sex/job etc. [4] Boosting can also be used to mix both User/Item-autoencoders to compute a single matrice.
- Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, (8), 30-37.,
- Salakhutdinov, R., Mnih, A., & Hinton, G. (2007, June). Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th international conference on Machine learning (pp. 791-798). ACM.
- Zhou, Y., Wilkinson, D., Schreiber, R., & Pan, R. (2008). Large-scale parallel collaborative filtering for the netflix prize. In Algorithmic Aspects in Information and Management (pp. 337-348). Springer Berlin Heidelberg.
- Strub, F., Mary, J., Gaudel R., (2016). Hybrid Collaborative Filterings and Neural Networks. Under review