代码分析是一个很大的主题,存在许多代码分析算法。我们不可能在这里介绍所有这些算法,也超出了本文档的范围。事实上,这一节的目的只是概述 ASM 中使用的算法。关于这一主题的更好介绍,可以在有关编译器的书中找到。接下来的几节将介绍代码分析技术的两个重要类型,即数据流和控制流分析:
- 数据流分析包括:对于一个方法的每条指令,计算其执行帧的状态。这一状态可能采用一种多少有些抽象的方式来表示。例如,引用值可能用一个值来表示,可以每个类一个值,可以是{null, 非 null,可为 null}集合中的三个可能值表示,等等。
- 控制流分析包括计算一个方法的控制流图,并对这个图进行分析。控制流图中的节点为指令,如果指令 j 可以紧跟在 i 之后执行,则图的有向边将连接这两条指令
i→j。
有两种类型的数据流分析可以执行:
- 正向分析是指对于每条指令,根据执行帧在执行此指令之前的状态,计算执行帧在这一 指令之后的状态。
- 反向分析是指对于每条指令,根据执行帧在执行此指令之后的状态,计算执行帧在这一 指令之前的状态。
正向数据流分析的执行是对于一个方法的每个字节代码指令,模拟它在其执行帧上的执行,通常包括:
-
从栈中弹出值,
-
合并它们,
-
将结果压入栈中。
-
这看起来似乎就是解释器或 Java 虚拟机做的事情,但事实上,它是完全不同的,因为其目 标是对于所有可能出现的参数值,模拟一个方法中的所有可能执行路径,而不是由某一组特定方法参数值所决定的单一执行路径。一个结果就是,对于分支指令,两个路径都将被模拟(而实际解释器将会根据实际条件值,仅沿一条分支执行)。
另一个结果是,所处理的值实际上是由可能取值组成的集合。这些集合可能非常大,比如“所有可能值”,“所有整数”,“所有可能对象”或者“所有可能的 String 对象”,在这些情况下,可以将它们称为类型。它们也可能更为准确,比如“所有正整数”,“所有介于 0 到 10 之间的整数”,或者“所有不为 null 的可能对象”。要模拟指令 i 的执行,就是要对于其操作数取值集合中的所有组合形式,找出 i 的所有可能结果集。例如,如果整数由以下三个集合表示:P=“正整数或 null”,N=“负整数或 null”,A=“所有整数”,要模拟 IADD 指令,就意味着当两个操作数均为 P 时返回 P,当两个操作数均为 N 时返回 N,在所有其他情况下返回 A。
最后一个后果是需要计算取值的并集:例如,与(b ? e1 : e2)对应的可能值集是 e1 的可能值与 e2 的可能值的并集。更一般地说,每当控制流图包含两条或多条具有同一目的地的边时,就需要这一操作。在上面的例子中,整数由三个集合 P、N 和 A 表示,可以很容易地计算出这些集合中两个集合的并集:除非这两个集合相等,否则总是 A。
控制流分析的基础是方法的控制流图。举个例子,3.1.3 节 checkAndSetF 方法的控制流图给出如下(图中包含的标记类似于实际指令):
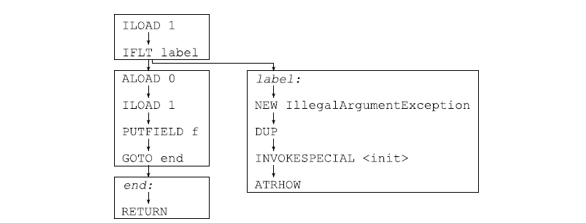
这个图可以分解为四个基本模块(如图中的矩形所示),一个基本模块就是这样一个指令序列:除最后一条指令外,每个指令都恰有一个后继者,而且除第一条外,所有其他指令都不是跳转的目标。