- Sử dụng mô hình của transformers để tạo ra 1 Chatbot có thể xử lí dữ liệu nhanh và tốt.
- Tensorflow >= 2.
- wget
- gradio
- Các cuộc phỏng vấn về tennis.
- Nguồn dữ liệu: Tennis Corpus
- T: input (1 câu hội thoại) output (1 câu hội thoại)
- E: Tennis Corpus
- F: Transformers
- P: Sparse Categorical Cross Entropy, Metrics: Accuracy
- A: Optimizer: Adam, Costum Learning Rate
- Tải dữ liệu về:
Loại 1: (Không có weight)
!git clone https://github.com/litahung/Chatbot-transformers.git
Loại 2: (Có weight)
import gdown
url = 'https://drive.google.com/uc?id=1Gk3YEln3gTRM5XF8pe585VIiq3_ai3Cn'
output = 'transformerschatbot.zip'
gdown.download(url, output, quiet=False)
!unzip '/content/transformerschatbot.zip' -d '/content/transformerschatbot/'
- Di chuyển đến vị trí chứa dữ liệu:
cd `đường dẫn`
- cài đặt các thư viện cần thiết:
!pip install -r requirements.txt
import gradio as gr
import main
- Hyperparameter:
main.Get_Hyper()
Kích thước 1 câu - max_length: 20
Batch size - batch_size: 256
Số lớp "encoder layer" và "decoder layer" - num_layers: 2
số lượng Units - num_units: 512
chiều sâu Model - d_model: 256
Số lượng head trong Multi-head attention - num_heads: 8
Dropout - dropout: 0.1
Activation - activation: relu
Epochs - epochs: 20
Nếu muốn đổi thông tin Hyperparameter, vui lòng mở file main.py và đổi thông tin trong class Args rồi restart runtime
- Sử dụng:
iface = gr.Interface(fn=main.predict, inputs='text' , outputs="text")
iface.launch()
- Train mô hình:
main.train_model()
-Một trong những ưu điểm của transformer là có khả năng xử lý song song cho các từ. Như chúng ta thấy, Encoders của mô hình transformer là một dạng Feedforward Neural Nets, bao gồm nhiều encoder layer khác, mỗi encoder layer này xử lý đồng thời các từ. Trong khi đó, với mô hình LSTM, thì các từ phải được xử lý tuần tự. Ngoài ra, mô hình Transformer còn xử lý câu đầu vào theo 2 hướng mà không cần phải stack thêm một hình LSTM nữa như trong kiến trúc Bidirectional LSTM.

- Vì mô hình ta dự đoán từ song song, nên chỉ đưa tất cả câu nhúng vào Word Embedding để dự đoán thì mô hình sẽ không thể nhận biết được vị trí của các từ. Vì vậy Positional Encoding sẽ giúp mô hình có thể nhận biết vị trí các từ.
- Vị trí của các từ được mã hóa bằng một vector có kích thước bằng word embedding và được cộng trực tiếp vào word embedding.
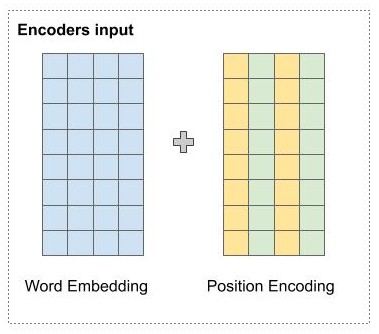
- Cụ thể, tại vị trí chẵn, tác giả sử dụng hàm sin, và với vị trí lẽ tác giả sử dụng hàm cos để tính giá trị tại chiều đó.

-
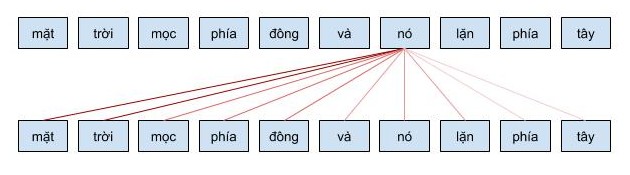
Cho phép mô hình mã hóa 1 từ có thể sử dụng thông tin của những từ liên quan tới nó (những từ đằng trước)
-
Ví dụ: khi từ
nóđược mã hóa, nó sẽ chú ý vào các từ liên quan như làmặt trời.
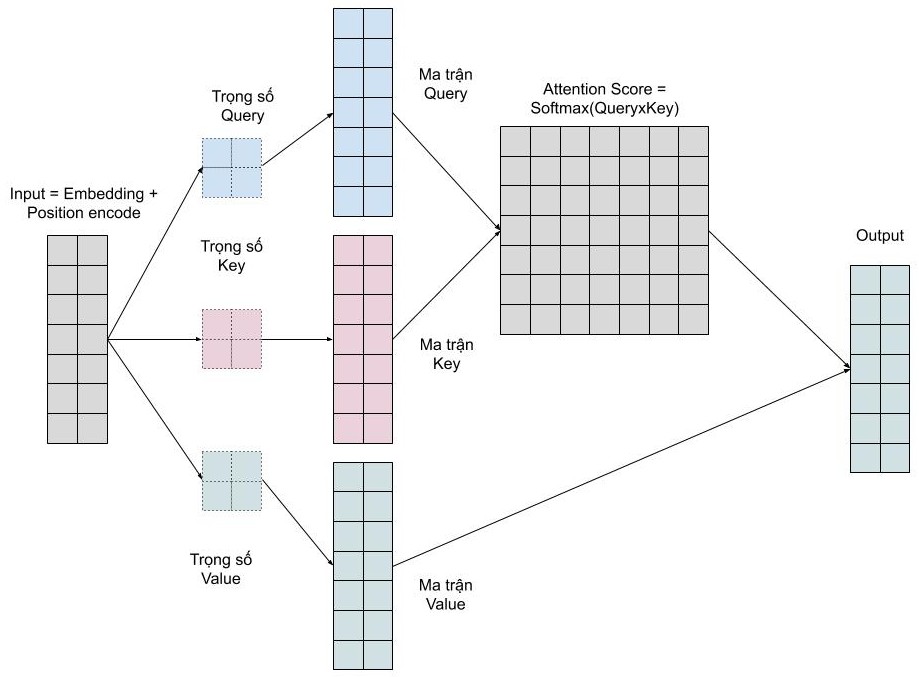
Cụ thể hơn, quá trình tính toán attention vector có thể được tóm tắt làm 3 bước như sau:
- Bước 1: Tính ma trận query, key, value bằng cách khởi tạo 3 ma trận trọng số query, key, vector. Sau đó nhân input với các ma trận trọng số này để tạo thành 3 ma trận tương ứng.
- Bước 2: Tính attention weights. Nhân 2 ma trận key, query vừa được tính ở trên với nhau để với ý nghĩa là so sánh giữa câu query và key để học mối tương quan. Sau đó thì chuẩn hóa về đoạn [0-1] bằng hàm softmax. 1 có nghĩa là câu query giống với key, 0 có nghĩa là không giống.
- Bước 3: Tính output. Nhân attention weights với ma trận value. Điều này có nghĩa là chúng ta biểu diễn một từ bằng trung bình có trọng số (attention weights) của ma trận value.
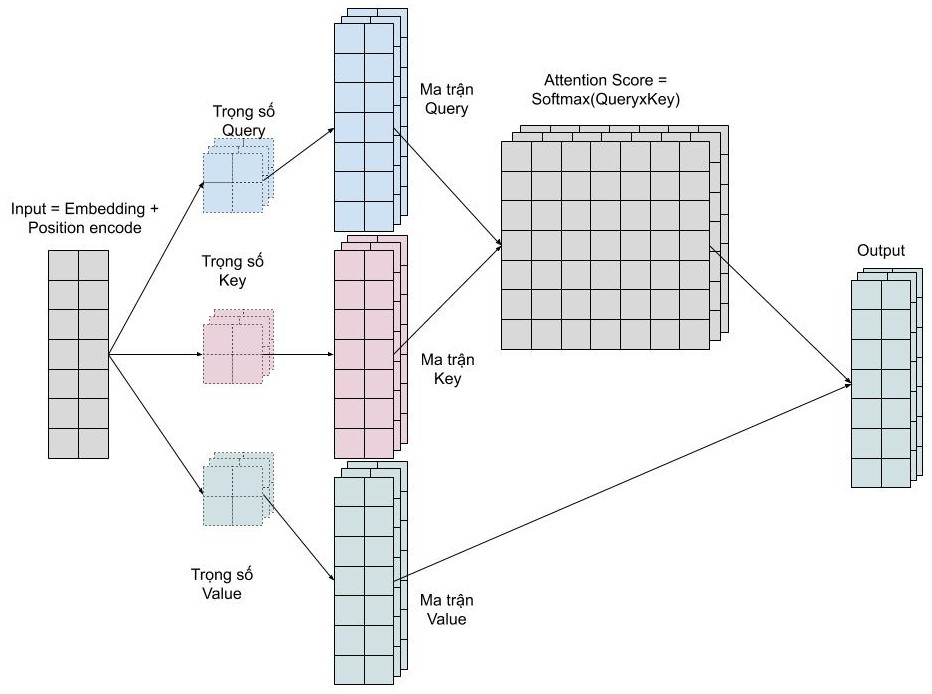
Với mỗi self-attention, chúng ta học được một kiểu pattern, do đó để có thể mở rộng khả năng này, chúng ta đơn giản là thêm nhiều self-attention. Tức là chúng ta cần nhiều ma trận query, key, value mà thôi. Giờ đây ma trận trọng số key, query, value sẽ có thêm 1 chiều depth nữa. Multi head attention cho phép mô hình chú ý đến đồng thời những pattern dễ quan sát được như sau.
- Chú ý đến từ kế trước của một từ
- Chú ý đến từ kế sau của một từ
- Chú ý đến những từ liên quan của một từ
![]()
Gồm các phần chính sau:
- Input Embedding
- Positional Encoding
num_layersencoder layers
Input của chúng ta được nhúng vào Embedding và kết hợp với Positional encoding để tạo thêm dữ liệu giúp mô hình nhận biết được vị trí của các từ trong câu nhờ Positional encoding. Sau đó ta đưa vào các encoder layers. Và cuối dùng đưa qua Decoder.

gồm các phần chính sau:
- Multi-head attention (có padding mask)
- 2 lớp dense
Đầu ra của mỗi sublayer encoder layers là LayerNorm (x + Sublayer (x)). Quá trình chuẩn hóa được thực hiện trên chiều d_model cuối cùng.

Gồm các phần chính sau:
- Output Embedding
- Positional Encoding
num_layersdecoder layers
Mục tiêu của chúng ta là nhúng vào Embedding và kết hợp với Positional encoding để tạo thêm dữ liệu giúp mô hình nhận biết được vị trí của các từ trong câu nhờ Positional encoding. Sau đó ta đưa vào các decoder layers để dự đoán. Và cuối dùng đưa qua 1 lớp Linear.

Gồm các phần chính sau:
- Masked multi-head attention (bao gồm look ahead mask và padding mask)
- Multi-head attention (bao gồm padding mask). value và key từ bộ dữ liệu output của encoder làm input. dữ liệu query từ output của masked multi-head attention.
- 2 lớp dense
decoder dự đoán từ tiếp theo bằng cách tập trung vào output của encoder và self-attention vào output của chính nó (output decoder).
