Auto Scaling

Amazon Auto Scaling is a versatile service that provides automatic capacity adjustments not only for Amazon EC2 instances but also for other AWS resources. By dynamically scaling resources based on predefined metrics such as CPU utilization or network traffic, Auto Scaling enables you to optimize performance and cost efficiency. Moreover, it seamlessly integrates with various AWS services, allowing dynamic scaling across a wide range of resources.
- Dynamic scaling: Auto Scaling automatically adjusts the number of EC2 instances, Docker services running on ECS, Kubernetes clusters on EKS, read/write capacity on DynamoDB, Aurora database instances, and other resources in response to changes in demand, ensuring your applications have the right amount of resources at all times.
- Scaling policies: You can define scaling policies that determine when and how to scale EC2 instances, Docker services, read/write capacity on DynamoDB, and others based on metrics such as CPU utilization, network traffic, or custom metrics.
- Integration with AWS services: Auto Scaling can be integrated with other AWS services like Amazon CloudWatch, Elastic Load Balancing, AWS Identity and Access Management (IAM) for more efficient and dynamic scaling across a variety of resources.
- Instance health monitoring: Auto Scaling continuously monitors the health of EC2 instances, containers, databases, etc., and replaces unhealthy instances to maintain desired capacity and availability.
- Scheduled scaling: You can set up scheduled scaling actions to automatically adjust the capacity of your instances, containers, databases, etc., based on predictable patterns, such as increasing during peak hours and decreasing during periods of lower demand.
- Integration with AWS Elastic Beanstalk: Auto Scaling can be used with AWS Elastic Beanstalk to automatically scale your web applications based on traffic patterns.
- Scalability means that application / system can handle greater loads by adapting.
- There are two kinds of scalability:
- Vertical Scalability
- Vertical Scalability means increase the size of the instance
- Improve any part of the instance
- Your application runs on a t2.micro, Scaling that application vertically means running it on a t2.large
- Vertical scalability is very common for non distributed systems, such as a database.
- Theres usually a limit to how much you can vertically scale (hardware limit)
- Horizontal Scalability (= elasticity)
- Horizontal Scalability means increase the number of the instance / system for your application
- Horizontal scaling implies distributed systems
- This is very common for web applications / modern applications
- Vertical Scalability


- High Availability usually goes hand in hand with horizontal scaling
- High availability means running your application / system in at least 2 Availability Zones
- The goal of high availability is to survive a data center loss (disaster)


- Scalability: ability to accomodate a larger load by making the hardware stronger (scale up), or by adding nodes (scale out)
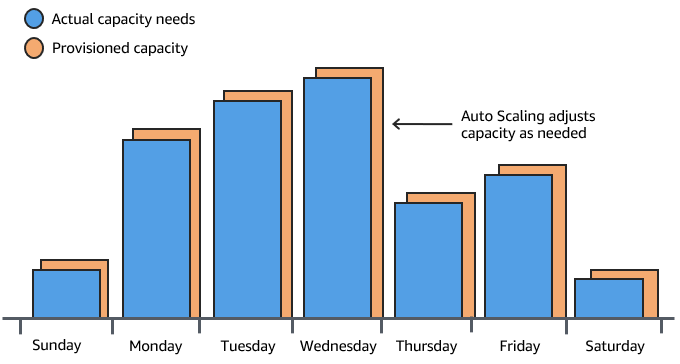
- Elasticity:once a system is scalable, elasticity means that there will be some "auto-scaling" so that the system can scale based on the load. This is "cloud-friendly", pay-per-use, match demand, optimize costs
- Agility:(not related to scalability - distractor) new IT resources are only a click away, wich means that you reduce the time to make those resources available to your developers from weeks to just minutes.
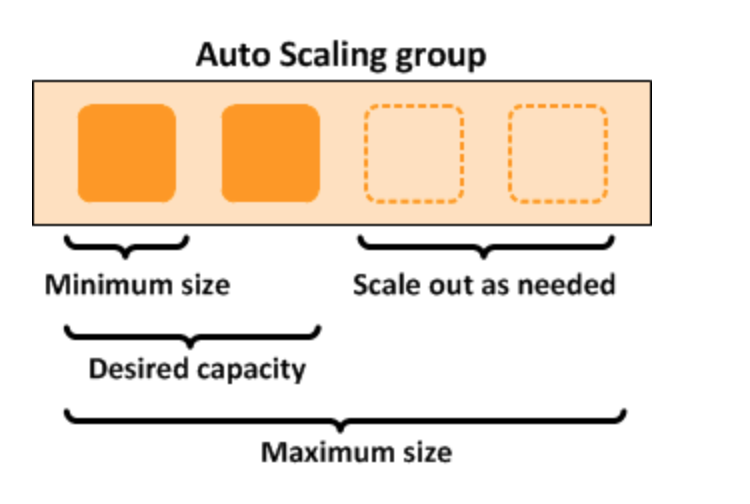
- Manual Scaling: update the size of an ASG manually
- Dynamic Scaling: respond to changing demand
- Simple / Step Scaling
- When a Cloud Watch alarm is triggered (example CPU > 70%), then add 2 units
- When a Cloud Watch alarm is triggered (example CPU < 30%), then remove
(Adjusts the number of running instances based on application demand) - Target Tracking Scaling
- Example: I want the avarege ASG CPU to stay around 40%
- Scheduled Scaling
- Antecipate a scaling based on known usage patterns
- Example: increase the min capacity to 10 at 5pm on Wednesday
(Auto Scaling helps ensure your application has the necessary capacity to handle both current and future demand)
- Simple / Step Scaling
- Predictive Scaling
- Use Machine Learning to predict future traffic ahead of time
- Automatically provisions the right number of resources in advance
- Define appropriate scaling policies: Analyze your application's performance metrics and expected demand to define scaling policies that ensure optimal resource allocation, whether for EC2 instances, Docker services, database instances, etc.
- Use dynamic scaling: Enable dynamic scaling based on real-time metrics to automatically adjust the number of instances, containers, read/write capacity on DynamoDB, etc., in response to changes in demand, ensuring optimal performance and cost efficiency.
- Monitor and optimize: Regularly monitor and analyze your application's performance, and adjust scaling policies as needed to optimize resource allocation and maintain optimal performance across various AWS resources.
- Enable detailed monitoring: Activate detailed monitoring for your Auto Scaling groups to collect more granular metrics and make more informed scaling decisions, regardless of the resource used.
- Use scheduled scaling: Take advantage of scheduled scaling actions to automatically adjust the capacity of your instances, containers, databases, etc., based on predictable patterns, such as increasing during peak hours and decreasing during periods of lower demand.
- Integrate with other AWS services: Leverage integration with other AWS services such as Amazon CloudWatch, Elastic Load Balancing, AWS Identity and Access Management (IAM) for more efficient and dynamic scaling across a variety of resources.
- Optimize the cooldown period: Configure an appropriate cooldown period to prevent Auto Scaling from starting or terminating additional instances immediately after a scaling activity, allowing time for new instances to stabilize, whether for EC2 instances, Docker services, database instances, etc.