Coordinate System Conventions #39
Comments
|
Also what's the difference between It appears that the |
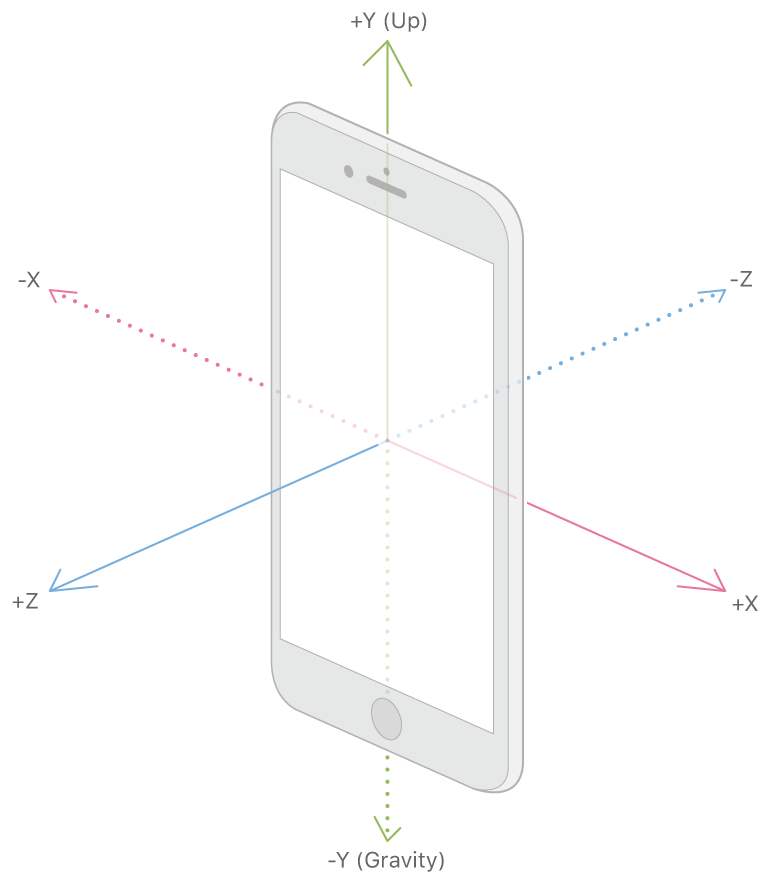
The device coordinate is the one you mentioned (xy is the device plane, and z is normal).
This is the reference I use for Projection matrix. Finally, there are two approaches how folks convert world coordinates to image coordinates. Graphic folks (including Objectron) usually use projection * view matrix, where as some multiview geometry/computer vision folks like to use intrinsic @ transform. Either one should work. If I recall, we should also have transform = inv(view). In this tutorial, we show how to get pixels from 3D points using projection+view matrices. Let me know if you have other questions. Happy to help. |

{kind=link}
|
Thanks very much for the clarification! I am using the projection * view approach to go from world to NDC. How do you take into account the device orientation? For the example in the tutorial, the images are loaded as shape (H, W) = (1920, 1440). If in the I'm trying to train a NeRF model using a video from Objectron so need to make sure the coordinate systems are aligned and the image size is also set correctly. |
|
Our images are 1080x1920, so w=1080, h=1920. Sorry for the typo above. What we tend to do is to swap the xy in the output coordinates. You can see how we use projection and view matrices to convert 3D points to image pixels here: Also if you want to train NeRF, we found out that the default camera poses (from AR sessions) are not accurate enough, so we ran an offline bundle adjuster to optimize it. The results are stored in sfm_data.pbdata, instead of geometry.pbdata. More info and some examples here and https://fig-nerf.github.io/. |
|
Thanks! I'll try using the optimized camera poses instead. So the projection and view transforms assume the image shape is w=1080, h=1920 but when inspecting the Instead of swapping the xy in the output values how should I modify the view and projection so that I get the xy values correctly as the output? i.e. should I swap the fx, fy and px, py position? Also for the |
|
Also is there an example of how to parse the |
So projection matrix assumes landscape mode.
|
|
@ahmadyan thanks for clarifying that the projection matrix assumes landscape mode. This was confusing as the video orientation is portrait mode so if I assume the image size in the NeRF model is (H, W) = (1920, 1440) then the rays are not aligned correctly with the image. I will try swapping the rows and columns as you mentioned. Regarding the |
|
The correct filename is sfm_arframe.pbdata There are 2 known issues which we are working to fix:
|
|
@ahmadyan thanks a lot, I will try this out for a few videos! |
|
@ahmadyan how did you set the raysampling min/max depths for the NeRF model? Did you set it separately for each object video? |
|
We used the jax-nerf implementation. |
|
@ahmadyan Thanks, This thread has been insightful as I didn't know that an adjustment had to be made as below.
I have tried making that adjustment, for Projection Matrix (P) as 2)More importantly, matrices like the view, projection matrices are device dependent. Wouldn't it be important to |
|
|
@ahmadyan Thanks for the information, This thread has been insightful for those who would like to apply Objectron in neural rendering. Just wondering how to compute the distance between the tracked object and the camera. import numpy as np
dist = lambda a, b: ((a - b)**2).sum()**0.5
def read_pbdata(path):
# read the annotation file
with open(path, 'rb') as pb:
sequence = annotation_protocol.Sequence()
sequence.ParseFromString(pb.read())
return sequence
anno_path = './Objectron/laptop/test/annotations/annotation_21.pbdata'
frame_idx = 0
annotations = read_pbdata(anno_path)
# take the object position (world coordinate) for object translation
obj_pos = np.array(annotations.objects[0].translation)
# annotation of a frame
frame_anno = annotations.frame_annotations[frame_idx]
camera = frame_anno.camera
# take the camera position from the view matrix
camera_pos = np.array(camera.view_matrix).reshape(4, 4)[:3, 3]
# calculate the distance between the camera and object
print(dist(camera_pos, obj_pos))However, the result is not reasonable when I observe the video and estimate the distance between camera and object position. Is there other methods that can correctly calculate the distance between camera and object position? |
|
It is a lot simpler than that. The object has 9 key-point, the first keypoint is the center. The .z (as in the point_3d[2]) in the camera frame coordinate is the distance between the camera and the object. Look at this tutorial and pay attention to this line |
|
The object's annotation points are given in camera coordinates. How can those be converted into world coordinates where the world's origin sits right inside the object's centererpoint and is aligned with the coordinate axis? |
|
In general, if have the camera pose P and point x, you can apply inv(P) @ x to get the points out of the camera coordinates and into the world coordinates. I don't fully understand the second part of your question thought. |
Can someone please clarify the conventions for the world-to-camera and camera projection transforms? In particular:
view_matrixandprojection_matrixgiven assuming this world convention?projection_matrixgiven in terms of NDC or screen? i.e. do we need to convert fx, fy using the image width/height to get NDC values?The text was updated successfully, but these errors were encountered: