[ALBERT]: In run_squad_sp, convert_examples_to_features gives error in case sentence piece model is not provided. #98
Comments
|
Download the model from tensorflow hub. The downloaded models will have an With no SPM ModelOutputWith SPM ModelOutput |
|
I had a similar issue, |
|
The trained model is uncased, so the returned value of But in Hope this works. |
|
@np-2019 - It is better not to use XLNET preprocessing. Here things are bit different. The provided code runs without any error. If you are familiar with BERT preprocessing, it is very close except the usage of SentencePiece Model. |
Thanks @wxp16 it helped. |
|
Sharing my learning, using XLNet pre processing will not help. As sequence of tokens in XLnet and Albert differs. SQUAD2.0 will get pre processed but training will not converge. Better to make selective changes in Albert Code only. |
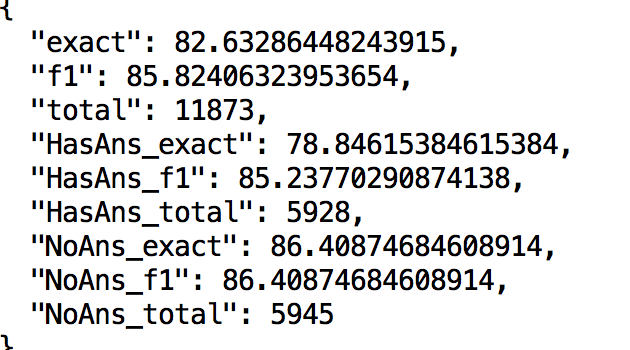
|
@np-2019 - Thats pretty good results. Which Albert model ( large, xlarge and version (v1 or v2) ) you have used? |
|
@np-2019 , Its very nice that you are able to reproduce the results successfully. according to XLnet paper: section 2.5: "We only reuse the memory that belongs to As we can see, CLS token has different locations, will it not cause any problem if we format data according to XLNet ? |
I am trying to run Albert model on SQUAD dataset. In case SP model is not used, convert_examples_to_features will not go through. Please let me know, where I can find SP model.
The text was updated successfully, but these errors were encountered: