throwing bad_alloc after calling model_fn #12
Comments
|
Hmm, I'm guessing the problem is that I do:
To avoid having to write out data files, and this creates very large allocations that may or may not fail depending on exactly how tensorflow/python was compiled (e.g., what version of the C++ standard library its using). I don't think that |
|
To check whether this is the issue, can you add a quick change where you truncate the SQuAD training data and if the bad alloc goes away. |
|
It works when I truncate the training data! |
|
Getting another error for memory during training after enqueuing and dequeuing batches of data from infeed and outfeed. |
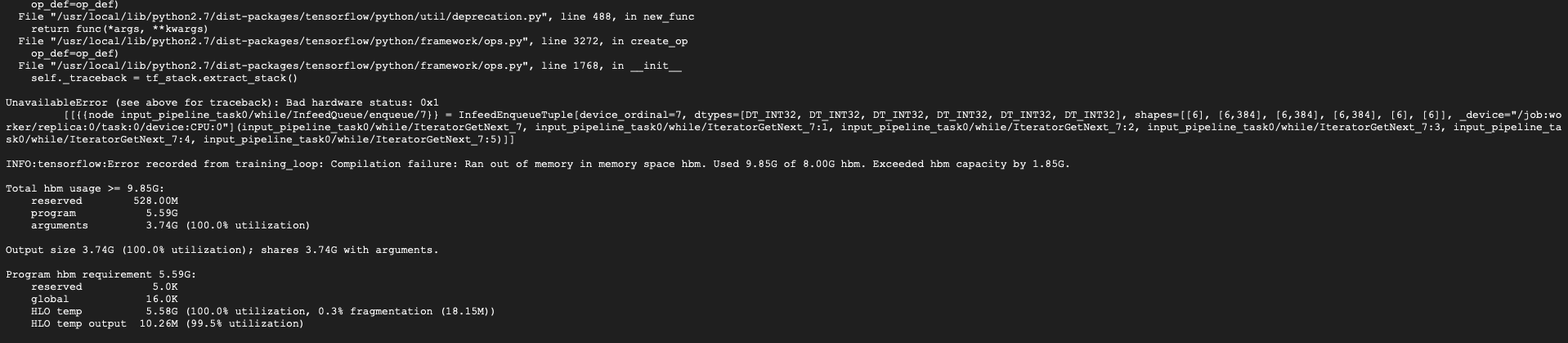
|
I'll work on a fix for the first issue. Actually I just realized that I can just write the TF record files to For the second issue, can you try reducing the batch size to 32? On our internal version of TF using a batch size of 48 only uses 7.48 GB of memory but things might be different between versions and that's cutting it close anyways. I may need to find a better learning rate and num_epochs for batch size 32, but it should work as well as 48 in terms of final accuracy. |
|
A batch size of 32 still results in being 200 mb over the memory capacity. Using 24 works for now, not sure how this will impact performance yet. |
|
That's a pretty huge difference, I'll coordinate with the TPU team here to figure out what's causing the mismatch. |
|
Jason, |
|
For the memory issue, I just confirmed that the TPU memory usage different is in fact due to improvements that have been made to the TPU compiler since TF 1.11.0 was released. So with TF 1.11.0 it seems like 24 is the max batch size, and in the next upcoming version it will be 48. (I'm assuming you're using 1.11.0, since that's what the README said to use). |
|
I confirmed that fine-tuning Thanks for bringing up this issue! Please let me know if your |
|
Thanks so much Jacob! I'm no longer getting the I also tried using a TPU v3.0 with the parameters you originally gave (batch size of 48) and ran it with no issues, and got a F1 score of 90.9! Amazing work! |
|
@JasonJPu Can you please comment on inference performance? Is it comparable to QANet? |
|
@webstruck inference is pretty slow, and depends on if you use TPU or GPU |
Awesome research! This is a huge breakthrough for NLP.
I'm running BERT-large on a Cloud TPU doing fine-tuning for squad, but I keep getting
I have nothing else running so I'm not sure why the machine is running out of memory, and followed the steps exactly for setup (ie putting the pre-trained model on a google bucket, set up for TPU, etc).
The text was updated successfully, but these errors were encountered: