Latent experiment #48
Conversation
afdf23b
to
cd035ea
Compare
cd035ea
to
200d4e2
Compare
|
I think now we're seeing something on the right track. The main issue here is that you should just take |
|
@lxuechen I've applied all comments and run it but it doesn't seem good after 400 iterations: Regarding taking last entry of |
The version on master records the The current version with augmentation tracks the absolute quantity, so we only need to take the end result in order to get a value consistent with what we previously had. |
examples/latent_sde.py
Outdated
| def forward(self, ts, batch_size, eps=None): | ||
| eps = torch.randn(batch_size, 1).to(self.qy0_std) if eps is None else eps | ||
| eps = torch.cat([torch.randn(batch_size, 1).to(self.qy0_std), torch.zeros(batch_size, 1) | ||
| .to(self.qy0_std)], dim=1) if eps is None else eps |
There was a problem hiding this comment.
This part is a little weird, since the second entry of y0 is likely not 0 (it seems to be qy0_mean), due to tensor broadcasting.
Additionally, the KL divergence compute is also weird.
This should be able to be modified by computing eps, y0, and the KL as before, but "append" y0 with zeros on the extra logqp dimension just before starting sdeint.
I think this might have been a major cause in the bad performance.
There was a problem hiding this comment.
OK, so regarding y0 it was me completely not paying attention to the code 🙄 - fixed it.
Right now result is almost identical to master version (after 200 iterations):

Also after above explanation of computing subintervals and examining it once again I think now I fully understand latent_sde.py - so subintervals define which points we want after all from the whole solve and those here are the xs from cos training data. Then in loss we check how much prediction is off from cos data and we don't want to do it with just MSE because according to the paper it would cause overfitting (is it correct?), instead we check probability density function with mean at predicted values at xs cos data.
But only fitting to the data it would make it arbitrary between data points (correct?). And here's such case after 500 iters:

Instead we want it to behave as Ornstein–Uhlenbeck process while fitting the data, so we compute through the whole solve how much our solution still behave like OU process (and regularize it that way).
To compute the difference we use KL divergence to see how much they differ.
We start computing KL div between mean and std params of prior and posterior and then within solve - accumulate KL div for each step where KL div dQ/dP from Girsanov theorem will be Doléans-Dade exponential where it's u-1/2*|u|^2. But I can't see where u = (f-h)/g came from and how it would look like if prior and posterior had different diffusions, and why u is missing from that KL div step definiton. Do you have a link to the theory where I can look for it?
That's added to the loss, and we also decrease learning rate to make training process faster at the beginning.
I hope that I didn't completely lost the point here.
Could be py0_mean and py0_logvar be just tensors as we do not train them?
There was a problem hiding this comment.
There are easier and more intuitive ways to derive this, but for a formal derivation, you can check out section 9.5 of our paper.
Placing a prior and inferring the posterior would give us Bayesian uncertainty estimates, especially at time points where data is not observed. This is also done when GPs are used for time series modeling. One additional advantage is that it also helps prevent overfitting.
examples/latent_sde.py
Outdated
| y = y[:, 0:1] | ||
| f, g, h = self.f(t, y), self.g(t, y), self.h(t, y) | ||
| z = f - h | ||
| g = torch.where( |
There was a problem hiding this comment.
Could we abstract this and the next line into a helper function _stable_division as before in misc?
The functionality of this step is clearer if we give these lines of code a name by wrapping them in a help function.
Minor nit: You may also call the resulting value u to better match the derivations.
examples/latent_sde.py
Outdated
| torch.ones_like(g).fill_(1e-7) * g.sign() | ||
| ) | ||
| z = z / g | ||
| z = .5 * (torch.norm(z, dim=1, keepdim=True) ** 2.) |
There was a problem hiding this comment.
I don't think the parentheses here are needed, since exponential has higher precedence than multiplication. z = .5 * torch.norm(z, dim=1, keepdim=True) ** 2 should work.
examples/latent_sde.py
Outdated
| def forward(self, ts, batch_size, eps=None): | ||
| eps = torch.randn(batch_size, 1).to(self.qy0_std) if eps is None else eps | ||
| y0 = self.qy0_mean + eps * self.qy0_std | ||
| y0 = torch.cat([y0, torch.zeros(batch_size, 1).to(self.qy0_std)], dim=1) |
There was a problem hiding this comment.
Maybe just use .to(y0) to save some compute, since the property qy0_std is recomputed each time.
|
Thanks for patiently addressing the issues I mentioned! I think this PR is just a few small fixes away from getting merged. |
|
@lxuechen All done! |
torchsde/_core/misc.py
Outdated
| y = torch.where( | ||
| y.abs() > epsilon, | ||
| y, | ||
| torch.ones_like(y).fill_(epsilon) * y.sign() |
There was a problem hiding this comment.
Quick comment: can this be torch.full_like(y, epsilon * y.sign()) instead?
(Untested, might have the syntax slightly wrong.)
There was a problem hiding this comment.
Sure!
API says that second arg should be a number. This works for me: torch.full_like(y, epsilon) * y.sign()
examples/latent_sde.py
Outdated
| @@ -28,6 +28,7 @@ | |||
|
|
|||
| from examples import utils | |||
| from torchsde import sdeint, sdeint_adjoint, SDEIto, BrownianInterval | |||
| from torchsde._core.misc import _stable_division | |||
There was a problem hiding this comment.
Let's not put _stable_division in core, but directly in this file.
This is to mimic positional encoding in transformers. Also it's incorrect to say that the value of sine determines the value of cosine, e.g. sin(pi/4) == sin(3pi/4), but cos(pi/4) != cos(3pi/4). This is elementary trigonometric. |
|
All done!
I was thinking about something completely different while writing this, not even looking at what functions are used, let's say because of current late night hour (embarrassment) |
1285ea2
to
97f55f5
Compare
No worries! I understand that might happen at times. |
|
Thanks for all the assistance once again! This or the following week I will try to do next small thing from milestone list (also started simple benchmark which I was asking earlier, will see how it goes). (I thought about turning open source contributions into some simple master thesis to be able to spend more time on this but unfortunately I haven't found anyone interested in supervising it at uni for coming year). Also I've got a question related to constraints of gradient computation (please let me know if it's inappropriate to ask here!) As there's a heat equation example and PINNs use gradient descent it eventually computes higher order derivatives of Tensorflow's control flows like loops and ifs (used for choosing correct bsplines). (I also tried learning coefficients straight from GD but also failed) So do you think that computing gradient of such complex logic might be unfeasible to acquire solution or there's no reason to say that and it's rather implemented incorrectly? |
|
Sorry for the late response, as I've been incredibly busy lately. Obviously, I'm not an expert on the specific models you described. What I may potentially comment on in an educated manner is the part about differentiating through control flow and obtaining high-order derivatives. Since both TF eager-mode and Pytorch use tape-based systems, taking gradients through control flow shouldn't be a problem, even if that control flow is pure Python code (Python if-else, for, while statements). Obviously, things get tricky when you start with TF graph-mode and jitting/scripting PyTorch code, and things typically break without there being potential simple fixes. Obviously, this is only coming from my limited experience. Second-order gradients typically aren't a problem either, if the specific computation can be grouped into Hessian-vector products, which can then be computed using just vector-Jacobian products. I haven't seen examples of taking gradients beyond the second-order in the ML literature so far. |
* Added BrownianInterval * Unified base solvers * Updated solvers to use interval interface * Unified solvers. * Required Python 3.6. Bumped version. * Updated benchmarks. Fixed several bugs. * Tweaked BrownianInterval to accept queries outside its range * tweaked benchmark * Added midpoint. Tweaked and fixed things. * Tided up adjoint. * Bye bye Python 2; fixes #14. * tweaks from feedback * Fix typing. * changed version * Rename. * refactored settings up a level. Fixed bug in BTree. * fixed bug with non-srk methods * Fixed? srk noise * Fixed SRK properly, hopefully * fixed mistake in adjoint * Fix broken tests and refresh documentation. * Output type annotation. * Rename to reverse bm. * Fix typo. * minor refactors in response to feedback * Tided solvers a little further. * Fixed strong order for midpoint * removed unused code * Dev kidger2 (#19) * Many fixes. Updated diagnostics. Removed trapezoidal_approx Fixed error messages for wrong methods etc. Can now call BrownianInterval with a single value. Fixed bug in BrownianInterval that it was always returning 0! There's now a 2-part way of getting levy area: it has to be set as available during __init__, and then specified that it's wanted during __call__. This allows one to create general Brownian motions that can be used in multiple solvers, and have each solver call just the bits it wants. Bugfix spacetime -> space-time Improved checking in check_contract Various minor tidy-ups Can use Brownian* with any Levy area sufficient for the solver, rather than just the minimum the solver needs. Fixed using bm=None in sdeint and sdeint_adjoint, so that it creates an appropriate BrownianInterval. This also makes method='srk' easy. * Fixed ReverseBrownian * bugfix for midpoint * Tided base SDE classes slightly. * spacetime->space-time; small tidy up; fix latent_sde.py example * Add efficient gdg_jvp term for log-ODE schemes. (#20) * Add efficient jvp for general noise and refactor surrounding. * Add test for gdg_jvp. * Simplify requires grad logic. * Add more rigorous numerical tests. * Fix all issues * Heun's method (#24) * Implemented Heun method * Refactor after review * Added docstring * Updated heun docstring * BrownianInterval tests + bugfixes (#28) * In progress commit on branch dev-kidger3. * Added tests+bugfixes for BrownianInterval * fixed typo in docstring * Corrections from review * Refactor tests for * Refactor tests for BrownianInterval. * Refactor tests for Brownian path and Brownian tree. * use default CPU * Remove loop. Co-authored-by: Xuechen Li <12689993+lxuechen@users.noreply.github.com> * bumped numpy version (#32) * Milstein (Strat), Milstein grad-free (Ito + Strat) (#31) * Added milstein_grad_free, milstein_strat and milstein_strat_grad_free * Refactor after first review * Changes after second review * Formatted imports * Changed used Ex. Reversed g_prod * Add support for Stratonovich adjoint (#21) * Add efficient jvp for general noise and refactor surrounding. * Add test for gdg_jvp. * Simplify requires grad logic. * Add more rigorous numerical tests. * Minor refactor. * Simplify adjoints. * Add general noise version. * Refactor adjoint code. * Fix new interface. * Add adjoint method checking. * Fix bug in not indexing the dict. * Fix broken tests for sdeint. * Fix bug in selection. * Fix flatten bug in adjoint. * Fix zero filling bug in jvp. * Fix bug. * Refactor. * Simplify tuple logic in modified Brownian. * Remove np.searchsorted in BrownianPath. * Make init more consistent. * Replace np.searchsorted with bisect for speed; also fixes #29. * Prepare levy area support for BrownianPath. * Use torch.Generator to move to torch 1.6.0. * Prepare space-time Levy area support for BrownianPath. * Enable all levy area approximations for BrownianPath. * Fix for test_sdeint. * Fix all broken tests; all tests pass. * Add numerical test for gradient using midpoint method for Strat. * Support float/int time list. * Fixes from comments. * Additional fixes from comments. * Fix documentation. * Remove to for BrownianPath. * Fix insert. * Use none for default levy area. * Refactor check tensor info to reduce boilerplate. * Add a todo regarding get noise. * Remove type checks in adjoint. * Fixes from comments. * Added BrownianReturn (#34) * Added BrownianReturn * Update utils.py * Binterval improvements (#35) * Tweaked to not hang on adaptive solvers. * Updated adaptive fix * Several fixes for tests and adjoint. Removed some broken tests. Added error-raising `g` to the adjoint SDE. Fixed Milstein for adjoint. Fixed running adjoint at all. * fixed bug in SRK * tided up BInterval * variable name tweak * Improved heuristic for BrownianInterval's dependency tree. (#40) * [On dev branch] Tuple rewrite (#37) * Rename plot folders from diagnostics. * Complete tuple rewrite. * Remove inaccurate comments. * Minor fixes. * Fixes. * Remove comment. * Fix docstring. * Fix noise type for problem. * Binterval recursion fix (#42) * Improved heuristic for BrownianInterval's dependency tree. * Inlined the recursive code to reduce number of stack frames * Add version number. Co-authored-by: Xuechen <12689993+lxuechen@users.noreply.github.com> * Refactor. * Euler-Heun method (#39) * Implemented euler-heun * After refactor * Applied refactor. Added more diagnostics * Refactor after review * Corrected order * Formatting * Formatting * BInterval - U fix (#44) * Improved heuristic for BrownianInterval's dependency tree. * fixed H aggregation * Added consistency test * test fixes * put seed back * from comments * Add log-ODE scheme and simplify typing. (#43) * Add log-ODE scheme and simplify typing. * Register log-ODE method. * Refactor diagnostics and examples. * Refactor plotting. * Move btree profile to benchmarks. * Refactor all ito diagnostics. * Refactor. * Split imports. * Refactor the Stratonovich diagnostics. * Fix documentation. * Minor typing fix. * Remove redundant imports. * Fixes from comment. * Simplify. * Simplify. * Fix typo caused bug. * Fix directory issue. * Fix order issue. * Change back weak order. * Fix test problem. * Add weak order inspection. * Bugfixes for log-ODE (#45) * fixed rate diagnostics * tweak * adjusted test_strat * fixed logODE default. * Fix typo. Co-authored-by: Xuechen Li <12689993+lxuechen@users.noreply.github.com> * Default to loop-based. Fixes #46. * Minor tweak of settings. * Fix directory structure. * Speed up experiments. * Cycle through the possible line styles. Co-authored-by: Patrick Kidger <33688385+patrick-kidger@users.noreply.github.com> * Simplify and fix documentation. * Minor fixes. - Simplify strong order assignment for euler. - Fix bug with "space_time". * Simplify strong order assignment for euler. * Fix bug with space-time naming. * Make tensors for grad for adjoint specifiable. (#52) * Copy of #55 | Created pyproject.toml (#56) * Skip tests if the optional C++ implementations don't compile; fixes #51. * Create pyproject.toml * Version add 1.6.0 and up Co-authored-by: Xuechen <12689993+lxuechen@users.noreply.github.com> * Latent experiment (#48) * Latent experiment * Refactor after review * Fixed y0 * Added stable div * Minor refactor * Simplify latent sde even further. * Added double adjoint (#49) * Added double adjoint * tweaks * Updated adjoint tests * Dev adjoint double test (#57) * Add gradgrad check for adjoint. * Relax tolerance. * Refactor numerical tests. * Remove unused import. * Fix bug. * Fixes from comments. * Rename for consistency. * Refactor comment. * Minor refactor. * Add adjoint support for general/scalar noise in the Ito case. (#58) * adjusted requires_grad Co-authored-by: Xuechen Li <12689993+lxuechen@users.noreply.github.com> * Dev minor (#63) * Add requirements and update latent sde. * Fix requirements. * Fix. * Update documentation. * Use split to speed things up slightly. * Remove jit standalone. * Enable no value arguments. * Fix bug in args. * Dev adjoint strat (#67) * Remove logqp test. * Tide examples. * Refactor to class attribute. * Fix gradcheck. * Reenable adjoints. * Typo. * Simplify tests * Deprecate this test. * Add back f ito and strat. * Simplify. * Skip more. * Simplify. * Disable adaptive. * Refactor due to change of problems. * Reduce problem size to prevent general noise test case run for ever. * Continuous Integration. (#68) * Skip tests if the optional C++ implementations don't compile; fixes #51. * Continuous integration. * Fix os. * Install package before test. * Add torch to dependency list. * Reduce trials. * Restrict max number of parallel runs. * Add scipy. * Fixes from comment. * Reduce frequency. * Fixes. * Make sure run installed package. * Add check version on pr towards master. * Separate with blank lines. * Loosen tolerance. * Add badge. * Brownian unification (#61) * Added tol. Reduced number of generator creations. Spawn keys now of finite length. Tidied code. * Added BrownianPath and BrownianTree as BrownianInterval wrappers * added trampolining * Made Path and Tree wrappers on Interval. * Updated tests. Fixed BrownianTree determinism. Allowed cache_size=0 * done benchmarks. Fixed adjoint bug. Removed C++ from setup.py * fixes for benchmark * added base brownian * BrownianPath/Tree now with the same interface as before * BInterval(shape->size), changed BPath and BTree to composition-over-inheritance. * tweaks * Fixes for CI. (#69) * Fixes for CI. * Tweaks to support windows. * Patch for windows. * Update patch for windows. * Fix flaky tests of BInterval. * Add fail-fast: false (#72) * Dev methods fixes (#73) * Fixed adaptivity checks. Improved default method selection. * Fixes+updated sdeint tests * adjoint method fixes * Fixed for Py3.6 * assert->ValueError; tweaks * Dev logqp (#75) * Simplify. * Add stable div utility. * Deprecate. * Refactor problems. * Sync adjoint tests. * Fix style. * Fix import style. * Add h to test problems. * Add logqp. * Logqp backwards compatibility. * Add type annotation. * Better documentation. * Fixes. * Fix notebook. (#74) * Fix notebook. * Remove trivial stuff. * Fixes from comments. * Fixes. * More fixes. * Outputs. * Clean up. * Fixes. * fixed BInterval flakiness+slowness (#76) * Added documentation (#71) * Added documentation * tweaks * Fix significance level. * Fix check version. * Skip confirmation. * Fix indentation errors. * Update README.md Co-authored-by: Patrick Kidger <33688385+patrick-kidger@users.noreply.github.com> Co-authored-by: Mateusz Sokół <8431159+mtsokol@users.noreply.github.com> Co-authored-by: Sayantan Das <36279638+ucalyptus@users.noreply.github.com>
Hi!
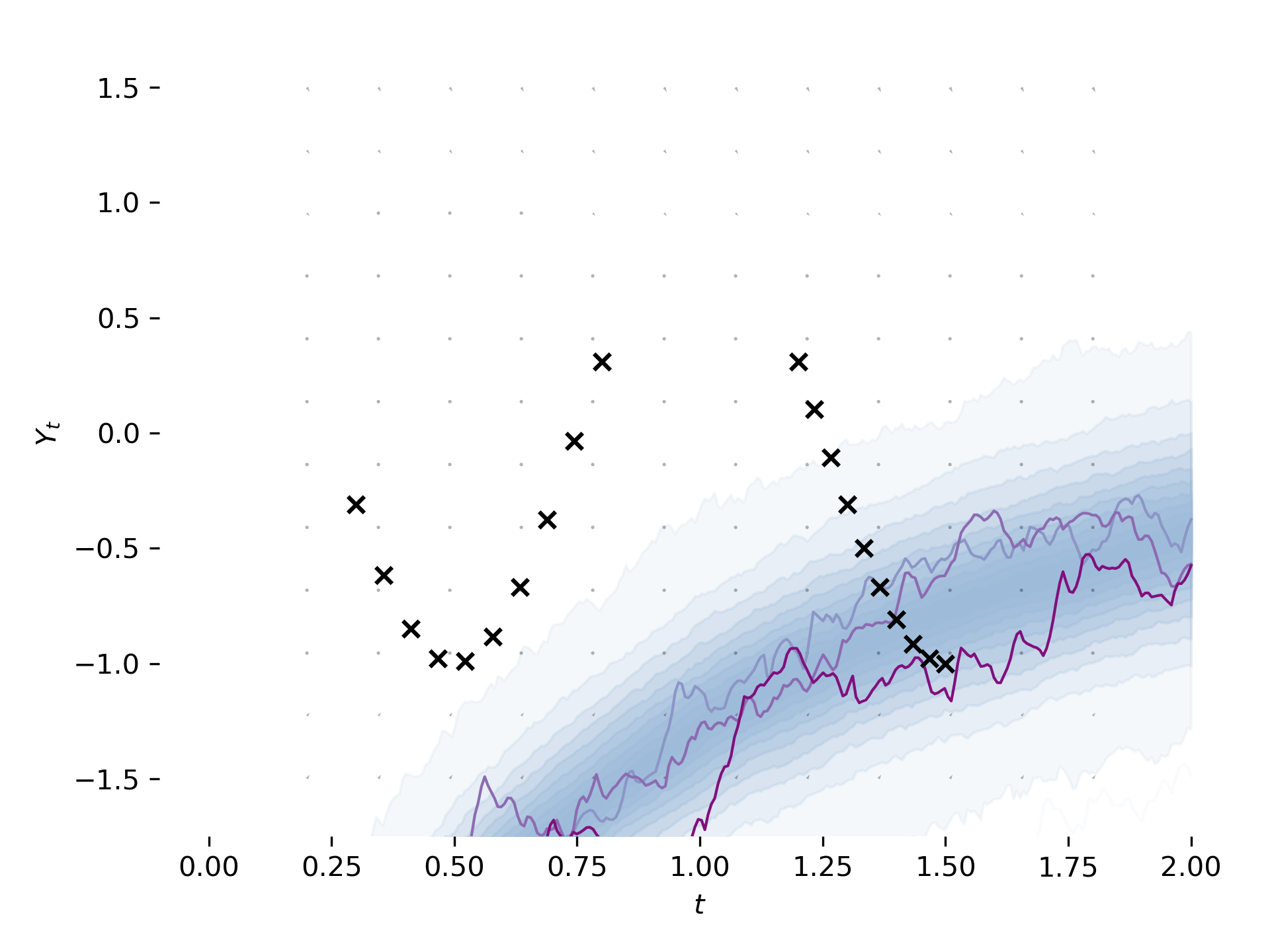
Following next instructions in #38 (comment) here's my idea for that - I've looked what flow exactly is for previous version available on
masterand hopefully recreated it.That's a result after 300 iterations (still not similar to 300 in previous version):
WDYT?
btw. running it locally was still slow and burning laptop so I ended up running it on CGP instance (e2-highcpu-8) as I found they have student packs and got one iteration at 4sec.