Generating random numbers with jax.random.split can be >200x slower than np.random.normal
#968
Comments
|
Thanks for the clear benchmark! I think this is essentially timing dispatch overheads. NumPy's dispatch overheads are a lot lower than JAX's, which makes it much faster at doing lots of small operations. (Interestingly, lots of small operations is what Python+NumPy is already considered bad at compared to something like pure C. One way to think about JAX, at least in its current state, is that it pushes that contrast further, in that it's even better than NumPy at large array-oriented operations because of its jit compilation and use of accelerators, but it's even worse at doing lots of small operations.) One way to make things faster is to use from jax import jit
@jit
def split_and_sample(key):
key, subkey = random.split(key)
val = random.normal(subkey, shape=(3,))
return key, val
def sample_repeatedly_with_split(key):
for _ in range(10000):
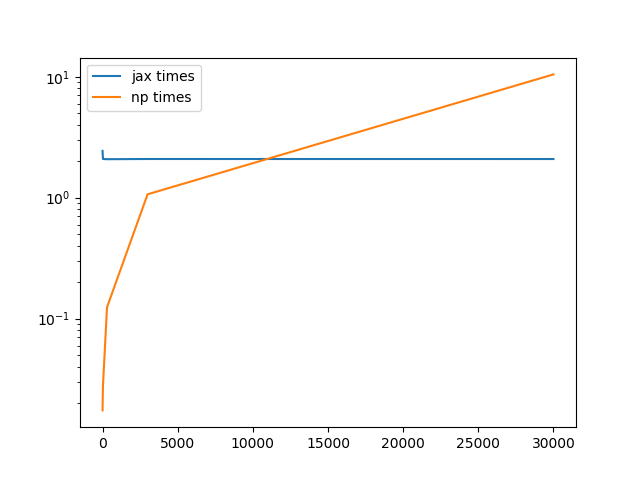
key, _ = split_and_sample(key)That sped things up, but only by a factor of 2. (That's also including compilation time, though that's probably small.) To measure something other than dispatch overheads, which isn't specific to PRNG stuff but would be measurable in pretty much any JAX vs NumPy micro benchmark like this, we can make the arrays bigger. Here are a few different sizes, with the largest being 30000 (which don't forget is smaller than a 200x200 array, which has size 40000, so these aren't very big sizes):
Here's the full script (check for bugs!): import time
from jax import random, grad, jit
import jax.numpy as np
import numpy.random as npr
@jit
def split_and_sample(key):
key, subkey = random.split(key)
val = random.normal(subkey, shape=shape)
return key, val
def sample_repeatedly_with_split(key):
for _ in range(10000):
key, _ = split_and_sample(key)
return key
def sample_repeatedly():
for _ in range(10000):
npr.normal(size=shape)
jax_times, np_times = [], []
sizes = [3, 30, 300, 3000, 30000]
for size in sizes:
shape = (size,)
key = random.PRNGKey(0)
now = time.time()
sample_repeatedly_with_split(key=key).block_until_ready() # async!
jax_times.append(time.time() - now)
now = time.time()
sample_repeatedly()
np_times.append(time.time() - now)
import matplotlib.pyplot as plt
plt.semilogy(sizes, jax_times, label="jax times")
plt.semilogy(sizes, np_times, label="np times")
plt.legend()
plt.savefig('issue968.png')The Still, if you want to generate lots of small arrays and can't stick everything under a What do you think? |
|
By the way, JAX's PRNG code is implemented entirely in Python. Not bad performance compared to the hand-written C/Fortran underlying NumPy's PRNG! |
|
Hi Matt, Thanks for the quick update! I realized that I should've "jitted" the function in the first place to avoid repeating some of the small computations. Thanks also for pointing out that jax uses async dispatch, as I was really curious about the motivation for a Also, awesome work on the pure Python PRNG! |
Here seems to be one related example on large amount of small computations. However, it seems not easy to jit it. This raises error message,
|
|
(It might be best to open a separate issue thread.) Indeed, not everything can be |
|
That's a helpful discussion, I'm having the same problem with For the problem here, is |
|
Your approach of iterating over a large key array and then re-casing it to def sample_repeatedly_with_split(key):
subkeys = jax.random.split(key, 10000)
key = subkeys[0]
return jax.vmap(sample)(subkeys[1:])I suspect this will virtually always be faster than a Python-side for-loop over the |
Currently, I'm relying on
jax.random.splitandjax.random.normalfor random number generation. I expect generating random numbers with this combination to be slower, but it's still surprising given the following results (on CPU):Results:
sample with split takes 8.6022 secs `npr.normal` takes 0.0296 secsSome profiling results (with cProfile and pstats) show:
myscript.cprof% stats 20 Wed Jul 3 10:13:14 2019 myscript.cprof 7879396 function calls (7264157 primitive calls) in 8.870 seconds Ordered by: cumulative time List reduced from 1909 to 20 due to restriction <20> ncalls tottime percall cumtime percall filename:lineno(function) 293/1 0.002 0.000 8.877 8.877 {built-in method builtins.exec} 1 0.000 0.000 8.877 8.877 split_prof.py:1(<module>) 1 0.091 0.091 8.602 8.602 split_prof.py:12(sample_repeatedly_with_split) 20003/20000 0.197 0.000 4.365 0.000 api.py:109(f_jitted) 30000 0.034 0.000 4.076 0.000 xla.py:518(<genexpr>) 20001 0.102 0.000 4.042 0.000 lax_numpy.py:2161(_rewriting_take) 20004 0.089 0.000 3.580 0.000 lax.py:1206(index_in_dim) 20007/20000 0.143 0.000 3.062 0.000 core.py:656(call_bind) 20003/20000 0.090 0.000 2.574 0.000 xla.py:604(xla_call_impl) 40274/40273 0.081 0.000 2.410 0.000 core.py:139(bind) 10000 0.028 0.000 2.295 0.000 random.py:376(normal) 10000 0.021 0.000 2.121 0.000 random.py:161(split) 40006 0.134 0.000 2.114 0.000 xla.py:50(apply_primitive) 20005 0.048 0.000 1.781 0.000 lax.py:1192(slice_in_dim) 20009 0.271 0.000 1.733 0.000 lax.py:586(slice) 20003/20000 0.085 0.000 1.660 0.000 linear_util.py:199(memoized_fun) 40006 0.983 0.000 1.318 0.000 xla.py:83(execute_compiled_primitive) 20013 0.128 0.000 1.284 0.000 lax.py:549(reshape) 20003 0.503 0.000 0.691 0.000 xla.py:629(execute_compiled) 59994 0.116 0.000 0.598 0.000 linear_util.py:173(__eq__)Note I named my script
split_prof.py. It seems there's considerable overhead with XLA, even when I'm not actively jitting any functions.The text was updated successfully, but these errors were encountered: