Efficient queuing of tasks that start waiting? #165
Comments
|
I guess the other thing would be the cost of the fibers involved for these; for example, if the tasks are enqueued and each allocated a Fiber (that holds 1MB of stack) and then all sit waiting keeping those fibers pinned it'll cause large memory growth. I'd want these tasks to not take a fiber from the pool until they were able to be executed. |
|
Yes - you are right to be concerned about scheduling a whole load of tasks, each starting with an immediate wait - you're forcing a task to start with an immediate fiber yield. It's going to be slow and you're likely going to allocate a whole fiber stack per task. If you are using
The internals of
Does this make sense? Does this work for you? |
|
Also: For these sorts of chained fan-out fan-in patterns, I think it's conceptionally simpler to consider the B's and D's here as a task with sub-tasks (example): So instead of thinking: We have: Where void taskB(int n) {
marl::WaitGroup wg(n);
for (int i = 0; i < n; i++) {
marl::schedule([=] {
defer(wg.done());
// Do [Bi] work
});
}
wg.wait();
}Or if there's a known finite amount of work for marl::parallelize([=] { /* B0*/ }, [&] { /* B1*/ }, [&] { /* B2*/ }); |
|
But to reiterate - if you go the path of using void taskB(int n, marl::Ticket ticketB) {
for (int i = 0; i < n; i++) {
// once all these sub-tasks are done, the last reference to ticketB will
// be dropped, automatically calling the next ticket in the queue.
marl::schedule([=, ticketB] {
// Do [Bi] work
});
}
}This avoids a fiber yield at |
|
Interesting - I hadn't played with Ticket::onCall yet. So it looks like if I scheduled work in there I'd avoid the potential fiber overallocation issue (as the tasks wouldn't exist until they were able to be started); though it would still introduce one additional fiber swap (ticket.done() -> schedule(onCall) -> schedule(new work)) - which could be optimized away if I were doing things myself as in the done/callAndUnlock handler I could just directly schedule the followup work. Digging deeper it seems like at least if the ticket.done() returns immediately the onCall may use the same fiber, and if the onCall returns immediately after scheduling more work it'll allow the same. Would still be nice to avoid the work when not required, though :)
Ohh I like that - I'd been worried about WaitGroup for fan-in because of that extra wake after wait (when that was the end of the task). These examples are very helpful in helping me find parts of the code to dig into. Thanks for taking the time to share them :) Maybe one thing that falls out of this discussion is some notes on onCall usage in ticket.h? I had skipped over it initially thinking it was a function for internal use and missed its awesome superpowers :) |
You only get a fiber swap whenever a task cannot progress further. So in this example, you'd only get a fiber swap if the caller of
Correct. It may - it may end up on any worker thread, and it may be stolen by another idle worker.
Good idea. I'll add some more documentation. |
|
Noodling more on what spawned my original question (trying to map an existing task graph into marl); this may be situation where I'm trying to hold it wrong. I basically have a semi-declarative graph I want to traverse and enqueue work for marl to chew on, and I want to be able to efficiently transfer the data flow modeled in that graph to marl with the minimum overhead and maximum freedom for marl to schedule things aggressively. If it helps ground things I'm basically implementing Vulkan's execution model :) In one model (I think what I was trying at first) I'd walk the entire graph and create all the tasks then hand them to marl and have it run those tasks as they were able. For that it'd need to be possible to create tasks that were initially suspended (like creating threads initially suspended in pthreads/win32) for the reasons we talked about above. The nice thing is that the code to go from the representation I have to tasks is straightforward and well-scoped (walk graph, enqueue tasks, return). The bad thing is that (as things are today) it may oversubscribe resources like fibers unless this was handled by the scheduler. An alternative model (the one using onCall) would prevent the oversubscription but would fragment the code that processes the graph. Each onCall would have to keep track of where it was in the graph and what nodes should be traversed next, and each onCall would be performing that work (less ideal for cache locality, the original representation must stay live or liveish for the duration of all work, etc). I think both can implement the same algorithm but the former feels more natural if starting with a representation that already has some tasks and dependencies defined. Maybe there's a data structure similar to Ticket/Queue that would allow this to be written like the former but implemented effectively as the latter. Fun stuff to think about :) |
|
So, based on what you've described - does this sort of fit the bill? #167 |
|
Wow, that may be precisely what's needed. That allows nice localized DAG construction (can be done from arbitrary threads/fibers - possibly with multiple DAGs being produced in parallel) and execution (run a sequence of DAGs when ready from a serialized ticket queue, for example), which makes modeling things like Vulkan/Metal queues and CUDA streams really natural. Since it's just built from marl primitives it allows a nice mix of DAG and non-DAG work (such as parallel fan-out from within DAG work) and DAGs to be chained (to mimic the half-static/half-dynamic behavior of queuing systems that may be producing DAG fragments instead of a global DAG of all work). Running each DAG as a fiber helps limit the explosion of pinned fibers to tasks. It'll also make attributing time (via tracing/profiling) to a DAG much easier as there's a place to put begin/end markers. Very cool - and a good demonstration of how to layer things together with marl primitives/fibers. If anything I think for people coming into marl it's a useful higher-level data structure that shows how the system can be used. I love it :) For my particular uses (emulating command queues/command buffers) this fits nicely. I can even construct the DAG while recording the command buffer (instead of needing to record the command buffer and then run over it all again to produce the schedule), which is a nice elision of work. Submitting/queue management becomes just ordering the |
|
Great to hear. I'll get the PR ready for review. Please feel free to nit-pick if there's stuff you'd like changed. |
|
#167 has now landed. Is there anything else you need here Ben? |
|
Assuming not. Closing for now. |
In my usage pattern I'm creating a possibly large number of tasks that may have a decent % initially waiting. For example, think of the pathological Ticket::Queue use case where the first (or one of the first) operations would be a wait:
Right now each task will get enqueued, switched to, and then immediately switched out when ticket.wait() blocks and for certain workloads this can be the norm instead of a pathological case.
Maybe the better approach for this is to use the tasks-in-tasks technique to only create the tasks when they are runnable? If so, are there other performance gotchas from doing that? For example, in this artwork:
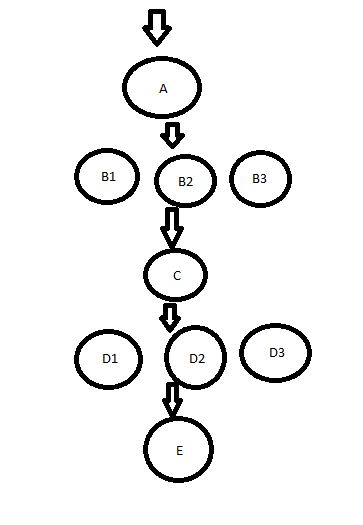
Would it be more efficient to queue up all of these using tickets (so Bn waits for A, C waits for Bn (waitgroup, etc), etc) ahead of time or better instead to have each queue up the following ones (so A only, then A runs and enqueues Bn, etc)?
I'm mostly interested in the fan-out case where A->Bn may be going 1 to 100 and Bn->A would be going 100 to 1. I wouldn't want C to wake 100 times only to wait 99 of them, for example. But I also wouldn't want to pessimize the fanout across threads at Bn by waiting until A was executing to enqueue the tasks.
Thoughts?
The text was updated successfully, but these errors were encountered: