Home
This page is for the master branch only.
Recent features added to master:
-
SVM wrapper function for MADlib
-
LDA wrapper function for MADlib
-
K-means wrapper for MADlib
PivotalR is an R package which you can download from CRAN. However, GitHub has the latest code.
- Display the summary of a table in GUI
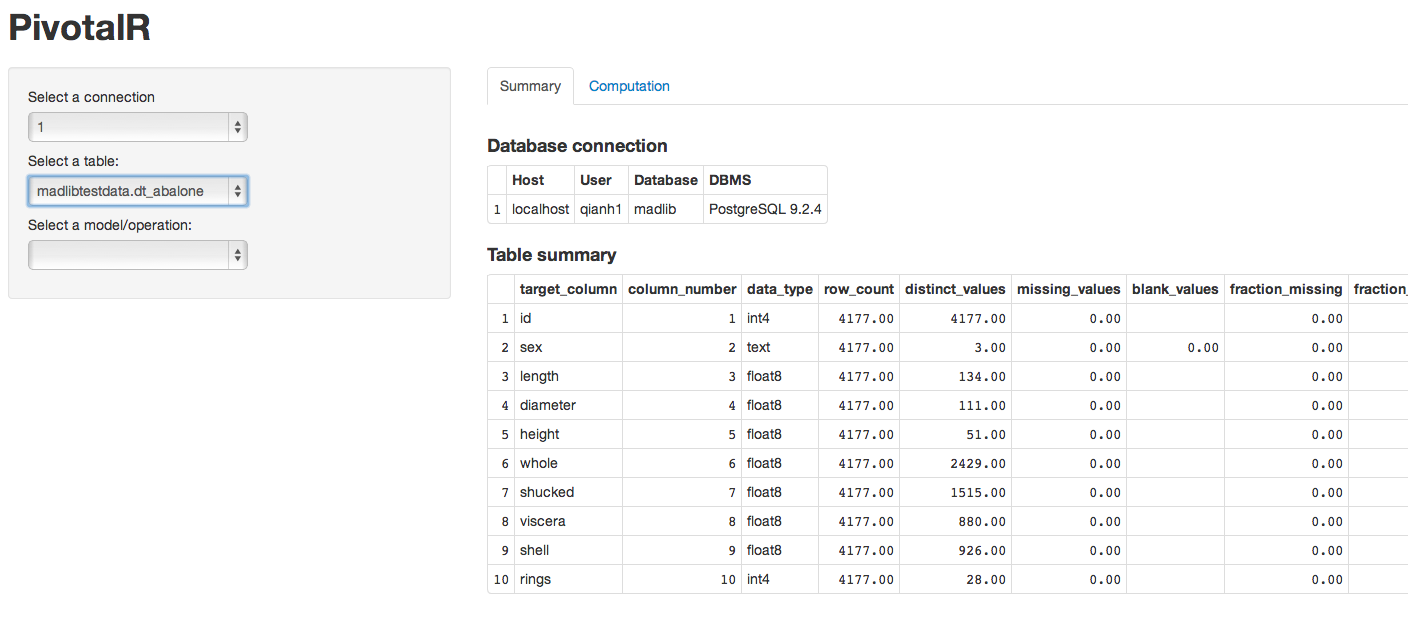
- Linear regression in GUI
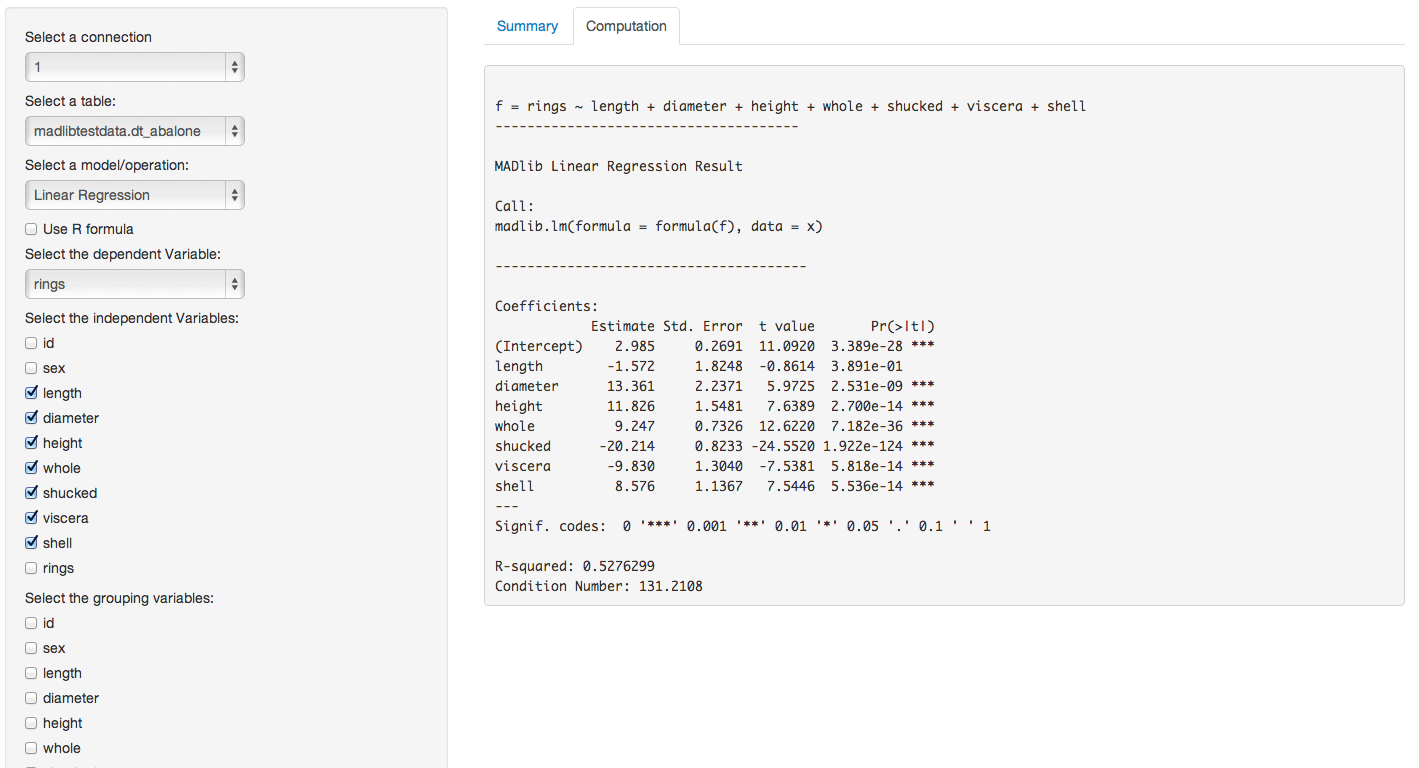
PivotalR is an R front-end to PostgreSQL and PostgreSQL-like databases like Pivotal Greenplum and Pivotal HDB/HAWQ.
When running on databases from Pivotal, PivotalR utilizes the full power of parallel computation and distributed storage inherent in Greenplum and HDB/HAWQ, and thus gives the normal R user access to Big Data. Users turn to PivotalR when they run out of memory on their R client.
PivotalR also provides an R wrapper for Apache MADlib (incubating). MADlib is an open-source library for scalable in-database analytics. It provides data-parallel implementations of mathematical, statistical and machine-learning algorithms for structured and unstructured data.
PivotalR mimics the regular R syntax for manipulating data.frame to operate on the tables stored in the database. We try to make PivotalR's learning curve as smooth as possible.
PivotalR also brings R's powerful graphical functionalities to Big Data stored in the database or in Hadoop.
PivotalR enables the user to create prototypes of machine learning algorithms quickly using regular R syntax. These prototypes acquire parallel computation power automatically when running on Greenplum or HDB/HAWQ.
To proceed, first copy your R script then make changes to make the script runnable in PivotalR. The goal of PivotalR is to minimize the amount of changes that are needed to convert a normal R script to parallel R script.
Here is an example PivotalR script.
