根据c++执行将内存划分为5个区域:
- 代码区,存放函数体的二进制,即CPU执行的机器指令,并且是只读的;
- 常量区,存放常量,即程序运行期间不能被改变的量。
- 全局区(静态区),存放全局变量和静态变量。
- 栈区,由编译器自动分配释放,存放函数形参,局部变量,返回值等。
- 堆区,由程序员分配和释放,若程序员不释放,程序结束时由操作系统CPU释放

代码区中存放的其实就是CPU执行的机器指令,代码区是共享和只读的,共享是指对于频繁被执行的程序,只需要在内存中有一份代码就行。而只读则表示防止程序意外修改指令。
全局区是全局变量、静态变量和常量区、字符串常量和const修饰的常量存放在这里。
代码区和常量区、全局区在代码编译后就存在了
栈区和堆区是程序运行后才有。
不要返回局部变量的地址,栈区的数据由编译器开辟和释放。形参数据也是放在栈区的。
堆区由程序员开辟,若程序员不释放,则由操作系统回收
其实这就是说道引用到底是什么的问题了。
其实到现在这个阶段,不能说引用就是起别名这么低俗的说法。
下面看一段代码:
//引用
int i=5;
int &ri=i;
ri=8;
//引用汇编
int i=5;
00A013DE mov dword ptr [i],5 //将文字常量5送入变量i
int &ri=i;
00A013E5 lea eax,[i] //将变量i的地址送入寄存器eax
00A013E8 mov dword ptr [ri],eax //将寄存器的内容(也就是变量i的地址)送入变量ri
ri=8;
00A013EB mov eax,dword ptr [ri] //将变量ri的值送入寄存器eax
00A013EE mov dword ptr [eax],8 //将数值8送入以eax的内容为地址的单元中
return 0;
00A013F4 xor eax,eax
//常量指针
int i=5;
int* const pi=&i;
*pi=8;
//常量指针汇编
int i=5;
011F13DE mov dword ptr [i],5
int * const pi=&i;
011F13E5 lea eax,[i]
011F13E8 mov dword ptr [pi],eax
*pi=8;
011F13EB mov eax,dword ptr [pi]
011F13EE mov dword ptr [eax],8
- 引用是一个变量,有地址,数据类型为dword,也就是说,ri要在内存中占据4个字节的位置。
- 看一下引用的汇编和常量指针的汇编可以发现是相同的,ri对应pi,因此可以说在底层汇编实现上引用是按照指针常量的方式实现的
在高级语言层面,有一点注意就是数组元素允许是常量指针的,但不允许是引用。主要是为了避免二义性,假如定义一个“引用的数组”,那么array[0]=8;这条语句该如何理解?是将数组元素array[0]本身的值变成8呢,还是将array[0]所引用的对象的值变成8呢?对于程序员来说,这种解释上的二义性对正确编程是一种严重的威胁,毕竟程序员在编写程序的时候,不可能每次使用数组时都要回过头去检查数组的原始定义。
//可以
int i=5, j=6;
int* const array[]={&i,&j};
//不行
int i=5, j=6;
int& array[]={i,j};
- 引用必须初始化
- 引用初始化以后就不能更改了
- 具体见面试总结里面有说
引用作为函数参数传递可以简化指针操作,直接修改实参
值传递,形参不会修饰实参
地址传递和引用传递,形参会修饰实参
- 不要返回局部变量的引用
- 函数返回值如果是引用,则可以作为左值使用
用来修饰形参,防止误操作
int & ref = 10 //不行
const int& ref = 10 //可以int func(int a, int b = 20, int c = 30){
return a + b + c;
}
int main(){
func(10);
return 0;
}即函数有默认参数的话,在调用该函数的时候就不用再传入参数了,因为有默认的
注意:
-
如果函数的某个参数已经有了默认值,那么从该位置往后从左到右都必须有默认值
-
如果函数声明有默认参数,那么实现就不能有默认参数。如下,会报错
//声明 int func(int a=10, int b = 20); //实现 int func(int a, int b = 20){ //会出现二义性 return a + b; }
函数名称相同,参数不同(或者个数,或者顺序),提高复用性
-
注意事项
-
引用作为重载的时候
引用的时候加入const是可以作为重载条件的,有两个重载函数如下:
void func(int& a); void func(const int& a); //void func(int& a)版本 int a = 10; func(a); //void func(const int& a)版本 func(10)为什么会这样,原因是
a=10是一个变量,但是直接传入10是临时空间,只能用const int& a去接收这块临时的空间 -
重载碰到默认参数
由于c++避免二义性,因此带默认参数的函数会出现二义性,所以要避免这类型情况。
-
-
本质(底层逻辑)
-
如果没有函数重载,那么会产生命名空间污染问题,导致为了实现同一个功能起了很多不同的名字
-
编译器在编译
.c文件的时候会给函数进行简单的重命名,就是在原函数名称前面加上“_”,比如原函数名叫做add,编译后就叫做_add,如下图所示: -
c++在底层编译
.cpp文件的时候,虽然函数名称一样,但是在后面添加了一些其他东西导致名称是不一样的,如图:其中“?”表示开始,“@@YA”表示参数的开始,后面三个字符“HHH”和“MMM”分别表示函数返回值类型,两个参数类型,“@Z”表示函数名称结束,所以由于函数生成的符号表中的名称不一样,因此可以编译通过。
-

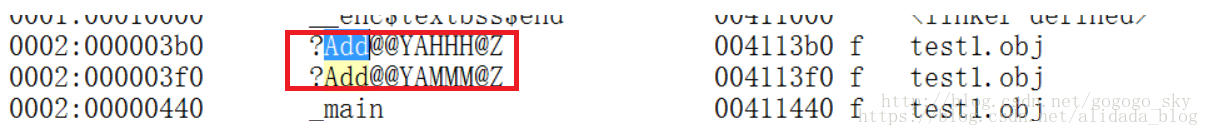
三大特性:封装、继承、多态
Class test{
//成员变量
//成员函数
};
-
封装
-
三种访问权限
- public。对成员来说,可以在类内被访问,类外也可以访问
- protected。对成员来说,可以在类内被访问,类外不可以访问,主要用在继承,子类可以访问父类的一些保护权限的内容。
- private。对成员来说,可以在类内被访问,类外不可以访问。子类不能访问父类的私有内容。
一般将成员变量属性设置为私有,可以自己控制读写权限,成员函数为共有。
类对象的默认访问控制是private的,但是结构的默认访问类型是public,结构没有成员函数只能纯粹的表示数据对象
-
-
成员函数
成员函数必须使用作用域解析符来指出函数所属的类,代码如下:
void Stock::update(double price);
位于类声明中的函数都将自动成为内联函数,但是内联函数也可以在类外定义,如下:
inline void Stock::update(double price);
由于内联函数的规则要求每个使用该函数的文件中都要对其进行定义,因此将内联函数放在头文件中是最好的。
- 类对象
每个新对象都有自己的存储空间,用于存储其内部变量和类成员。但是同一个类的所有对象共享类的方法,即类的函数。所有类对象都会执行同一个代码块,只是入栈的数据不同而已。
由于类设计的初衷是隐藏数据成员,因此类的初始化不能像结构那样,必须通过成员函数来访问成员数据。
因此c++提供了一个类构造函数,在创造对象时自动对它进行初始化。
注意事项:不能将类成员用作构造函数的参数名
因为构造函数的作用是初始化成员变量的值,因此构造函数的参数肯定是传入的值,不可能是类成员变量的值!因此为了避免这种混乱,需要在类成员函数的名称前加一个前缀,比如“m_”这样的。
-
使用构造函数
c++使用了两种用构造函数来初始化对象的方式:
//显示的调用构造函数 Stock food = Stock("World Cabbage", 250, 1.25); //隐式的调用构造函数 Stock garment("Furry Mason", 50, 2.5); //动态分配new Stock *pstock = new Stock("Furry Mason", 50, 2.5); /*动态的创建一个Stock对象,并将对象的地址赋给pstock指针,用指针管理该对象*/
切记,无法使用对象来调用构造函数,因为在构造函数构造出对象之前,对象是不存在的!因此构造函数是用来创建对象的,不能通过对象调用
-
默认构造函数
默认构造函数是指在没有显示的赋值时,用来创建对象的构造函数。如下:
Stock fluffyp;
上面这行代码之所以可以使用是因为对于类没有构造函数的话,c++编译器将自动提供一个默认构造函数,用来创建对象但不初始化值,一般默认构造函数的形式如
Stokc::Stock(){}如果类没有定义任何构造函数的时候,编译器才会提供默认构造函数。但是如果类定义了构造函数,就必须要写一个默认构造函数!
因此在以后设计类的时候,通常应提供所有成员隐式初始化的默认构造函数
-
赋值(构造函数作用2)
与结构赋值一样,在默认情况下给类对象赋值时,把一个对象的成员复制给另一个。这样一来,构造函数不仅仅可用于初始化新对象,还可以执行赋值操作
stock1 = Stock("wuhu", 10, 50.0);
上述代码右边指的是构造函数产生了一个新的临时的对象,然后将该临时对象的内容赋值给了stock1
我们将上述代码放在一起比较:
//显示的调用构造函数 Stock food = Stock("World Cabbage", 250, 1.25); stock1 = Stock("wuhu", 10, 50.0);
第一条语句有可能会创建临时变量也可能不会,创建临时变量的话就变成第二条语句这样的赋值了,因此如果可以初始化尽量不要赋值,提高效率。因此我们就有c++11的列表初始化。
当构造函数创建对象后,程序负责跟踪该对象,知道过期为止。对象过期时程序将自动调用一个特殊的成员函数 —析构函数,由析构函数完成清理工作。如果构造函数使用new分配内存,那么析构函数就要使用delete释放。如果构造函数不适用new,则析构函数什么都不用做。
下面给一段代码进行解释:
const Stock& topval(const Stock& s);
top = stock1.topval(stock2);
top = stock2.topval(stock1);这段代码比较两个对象的股票价格最高的,返回其中过一个,传入参数只有一个显示的引用。
c++使用this这种特殊的指针,指向用来调用成员函数的对象(谁调用该成员函数,this对象就是谁)。其实每个成员方法都有一个隐藏的形参this指针上述代码中stock1调用了topval函数,因此this指针就是stock1.
所有的类方法都将this指针设置为调用它的对象的地址
每个成员函数(包括构造函数和析构函数)都有this指针。this指针指向调用的对象,是对象的地址,因此*this才是这个对象,this只是个地址,*this作为对象的别名。
如果要创建类的多个对象,可以使用数组的方式,声明对象数组的方法与声明标准类型数组相同:
Stock mystuff[4];在类中定义的作用域为整个类,名称在类内是已知的,在类外不是。因此可以在不同类使用相同的成员名称而不引起冲突,必须通过对象来访问类的成员或方法。
-
在类中声明常量
要注意,在类中类只是描述一个结构的形式,在没有创建对象之前,类是没有用于存储的空间的,因此不能如下直接在类中生命一个变量值:
class temp{ private: const int Months = 12;//这样是不行的 };
如果我们要声明一个变量,要在前面加上
static关键字,表明该常量是与其他静态变量存储在一起的,而不是存储在对象中的。因此month可以被所有的对象共享。 -
作用域内枚举(枚举类)(c++11)
enum egg{small, medium, large} enum t_shirt{small, medium, large}
上述代码是常规的枚举类型,可以看到存在问题,即两个枚举定义的枚举量可能发生冲突,因为egg small和t_shirt small在一个作用域内。因此c++11提供了一种新的枚举类型,枚举作用域为类,叫做枚举类。
enum class egg{small, medium, large} enum class t_shirt{small, medium, large} egg choice = egg::small; tshirt choic = t_shirt::small;
不同枚举定义的枚举量就不会发生冲突了
同时枚举类还提高了作用域内枚举的类型安全。在有些情况下,常规枚举将自动转化为整型,比如赋值给int类型或者用于比较表达式时候,但是枚举类不能隐式的转换成整型。有必要的时候只能进行显示的转换
int(枚举)默认情况下c++11作用域内枚举的底层类型为int,但可以显示的更改底层类型,比如:
enum class : short pizza{small, medium,large}
如上述代码底层就变成了short类型。
c++多态有函数重载和运算符重载
运算符重载的格式如下:
(返回类型) operator OP (argument-list),例如operator +()重载+运算符,operator *()重载*运算符。但要切记,OP这个运算符一定是有效的,不能虚构一个运算符,比如@#等,因为这些符号在实际中本来就不是运算符。
举个例子:
A,B,C都是一个类的对象
//想求对象相加 A = B + C; //编译器角度 A = B.operator+(C)该函数隐式的使用A(调用了operator方法),显式的调用C(因为被当做参数传递了)
在重载运算符中,运算符左侧的对象是调用对象,而运算符右侧的对象是作为参数传递的
看一段代码:
class Time{ private: int hours; int minutes; public: Time(); Time operator +(const Time& t) const; }; Time::Time operator+(const Time& t) const{ Time sum; sum.minutes = minutes + t.minutes; sum.hours = hours + t.houts + sum.minutes/60; return sum } //使用重载运算符 time1 = time2 + time3;在这里面有两点需要注意:
要主要operator的返回值,到底返回什么。
上面代码中我们是要用time1来接收operator的返回,由于time1的类型是Time类,因此上面代码中operator的返回值也是Time。
注意返回值不能是引用。因为sum是局部变量,在函数结束时会被删除,因此引用将指向一个不存在的对象(vs编译器中会保存一次该引用,但是只能调用一次)。但是上述代码返回的是sum,是一个局部变量,在函数结束删除sum时候会构造一个sum的拷贝放到临时变量中。
重载有以下两个限制:
- 重载后的运算符必须至少有一个操作数是用户自定义的类型,不能两个操作数都是系统原有的类型。这样是防止用户对标准类型重载运算符,比如不能将+重载后作用于两个int类型的变量上
- 重载后的运算符不能违背原来的规则,比如不能将运算符变成一个变量类型
- 不能创建新的运算符,比如说创建一个**去求幂。
- 有以下几个运算符不能重载:
sizeof、.、::、?:、.*、const_cast、dynamic_cast、static_cast等 - 下面四个运算符必须通过成员函数去重载:
=、()、[]、->。
c++对私有部分成员的访问非常严格,在没有友元之前只能通过公有方法去访问。但是提供了对私有成员的另一种访问:友元,有3种:
- 友元函数
- 友元类
- 友元成员函数
在为类重载二元运算符(带两个参数的运算符)常常需要友元,因为问题描述如下:
对于重载的乘法运算符来说,比如代码如下:
Time operator*(const double num);比如上述代码可以满足:A = B * 2.75
但是我要写成A = 2.75 * B呢?由于重载运算符左边是double类型,而代码中左边是调用operator的对象,是Time类,所以就有问题。由于左侧的操作对象应该是Time类对象,而不应该是doule变量,所以编译器不能使用成员函数来调用该表达式。
上述问题的解决办法就是采用非成员函数,非成员函数不是对象调用的,它所使用的值都是显式的参数,比如下面的代码:
Time operator* (double m, const Time& t);上述代码解决了A = 2.75 * B这个问题,但又有一个新的问题即非成员函数不能访问私有成员,所以就需要友元函数。
+++
创建友元函数:
friend Time operator*(double m, const Time& t);加了friend前缀后,该函数就和成员函数有着一样的访问权限。
可能刚开始学的时候认为友元这个性质违背了OOP数据隐藏的概念,因为友元机制允许非成员函数访问私有数据。这个有些片面,应该将友元函数看作类的扩展接口的组成部分。类方法和友元只是表达类接口的两种不同机制而已。
+++
重载<<运算符
最初<<运算符是C和C++的位运算符,表示左移。ostream类对该运算符进行了重载,变成了一个输出工具。cout是一个ostream对象,能够识别所有的c++基本类型,原因是对于每种类型,ostream类声明都包含了相应的重载。
但要注意一点,重载<<符号的时候,函数的返回值一定要写成ostream&,如下代码:
ostream & operator<<(ostream& os, const Time& t); 因为cout<<不是调用一次,而是很多次,比如cout<<"hello"<<Time<<endl
+++
注意,只能在类声明中的原型上才能使用friend关键字,不能在函数定义中使用friend!!
友元类的所有方法都可以访问原始类的私有成员和保护成员。
友元类举例:
一个电视机类TV和一个遥控器Remote类,这两个不是包含也不是继承关系,但是遥控器可以控制电视机,也就意味着遥控器这个类可以访问电视机类中的成员,因此用友元类比较好。
class TV{ public: friend class Remote; bool volup(); bool voldown(); void chanup(); void chandown(); private: int state; int volume; int maxchannel; int channel; }; class Remote{ private: int mode; public: bool volup(Tv& t){ return t.volup(); } bool voldown(Tv& t){ return t.voldown(); } void chanup(Tv& t){ return t.chanup(); } void chandown(Tv& t){ return t.chandown(); } void set_chan(Tv& t, int c){ t.channel = c; } };
在上面两个类中的代码,大部分Remote类中的方法都是用Tv类的共有接口实现的,意味着这些方法不是真正需要用作友元。但是有一个Remote类中的函数直接访问了TV类中的私有成员,就是set_chan函数,因此这个方法才是唯一需要作为友元的方法。
可以选择让特定的类成员成为另一个类的友元,而不用让整个类成为友元,修改一下上述代码如下:
class Tv{
public:
friend void Remote::set_chan(Tv& t, int c);
...
};+++
c++处理内置类型转换:
在两种类型兼容的情况下,将一种标准类型变量的值赋给另一种标准类型变量的值时,c++将自动转换,代码如下:
long count = 8;
int side = 3.33c++内部将各种数值类型都看作是同样的东西—数字。但是c++不自动转换不兼容的类型,比如下面的语句是非法的,左边是指针,右边是整形数字
//不支持
int* p = 10;
//强转成int指针类型,指针值为10
int* p = (int*)10+++
下面说一说类相关的转换
有参的构造函数为类的转换提供了蓝图,或者说提供了原动力
//一个类的构造函数
Stonewt(double lbs);
//隐式转换
Stonewt myCat;
myCat = 16.9; 对于上面代码,使用构造函数Stonewt(double)来创建一个临时的Stonewt对象,并将19.6作为double参数传入,随后采用成员赋值的方式将该临时对象的值复制到myCat中,成为隐式转换,是自动进行的,不需要显式强制类型转换。
但有一个问题,即因为只有一个19.6类型的double变量,因此只支持一个参数的构造函数。
将构造函数用作类型转换函数仔细一看其实很棒,不用我们自己操作。但是有个问题,我们并不是总是需要,可能会导致意外的类型转换。因此c++新增了一个explicit关键字,用于关闭这种自动转换的特性。可以如下声明构造函数:
explicit Stonewt(double lbs);
//无法隐式转换
Stonewt myCat;
myCat = 16.9;
//必须显式转换
myCat = (Stonewt)16.9; 一旦加入了explicit,则不能隐式转换,必须显示转换
+++
我们可以将数字转换为类对象,那么可以反过来,将类对象转换为数字吗?如下所示:
Stonewt wolfe(285.7);
double host = wolfe;其实是可以这样做的,但是不能使用构造函数了,因为构造函数只能用于从某种类型到类类型的转换
要进行类类型到某种类型的转换,使用特殊的c++运算符函数——转换函数。转换函数是用户自定义的强制类型转换,可以像使用强制类型转换那样使用它们。
原型 operator typename()
转换函数有几个注意事项:
- 转换函数必须是类方法
- 转换函数不能指定返回类型
- 转换函数不能有参数
比如上面我要将类类型转换成double类型,则要在类中添加转换函数:
class Stonewt{
private:
...
int pounds;
public:
...
//这里面我以内联函数的形式写
operator int() const{
return pounds;
}
operator double() const{
return double(pounds);
}
};
//调用如下,之间调用即可,因为我们在类中定义了转换函数
Stonewt temp;
doule d = temp;+++
我们最好在程序的运行阶段,而不是编译阶段确定问题,这样动态的比较方便
因此一些问题也是因为动态分配内存导致的
静态成员变量
对于静态成员来说,无论创建了多少个对象,程序都只创建一个静态类变量的副本。
不能在类声明中初始化静态成员变量,因为类声明只是描述了如何分配内存,但是不实际分配内存。必须在类声明之外使用单独的语句来初始化,这是因为静态类成员是单独存储的,而不是对象的组成部分。所以一般静态数据成员在类声明中声明,在包含类方法的文件中初始化,初始化时使用作用域运算符来指出静态成员所属的类。但是如果静态成员是const或者枚举类型,则可以在类声明中初始化。
+++
问:为什么要有析构函数?
答:当删除类对象的时候可以释放掉对象本身所占用的内存,但是并不能自动释放属于对象成员指针所指向的内存。因此必须使用析构函数,在析构函数中使用delete来保证当对象过期时,可以释放掉由new所分配的内存。
在构造函数中使用new来分配内存时,必须在相应的析构函数中使用delete释放内存,如果使用new[]来分配内存,则应该使用delete[]来释放内存。
+++
类创建中一些特殊的成员函数
很多类中产生的问题都是由于特殊成员函数引起的,C++自动提供了下面这些成员函数:
- 默认构造函数,如果没有定义构造函数
- 默认析构函数,如果没有定义
- 拷贝构造函数,如果没有定义
- 赋值运算符,如果没有定义
- 地址运算符,如果没有定义
比如说我们自己设计一个string类,那么这几个函数都要着重考虑一下了。
-
默认构造函数
如果没有提供任何构造函数,c++将创建默认构造函数。因为创建对象时总会调用到构造函数。
但是类智能有一个构造函数,因为如果有多个构造函数就会产生二义性,如下:
class_temp A;
对象A对于编译器来说不知道去调用哪一个构造函数
-
拷贝构造函数
拷贝构造函数用于将一个对象复制到新创建的对象中,用于初始化过程中,而不是常规的赋值过程。赋值过程有赋值运算符,要重载赋值运算符。
拷贝构造函数原型如下:
Class_name(const Class_name &); //example String(const String& s);
当新建一个对象并且将其初始化为现有对象时,会调用拷贝构造函数,有如下例子:
StringBad ditto(motto); StringBad ditto = motto; StringBad ditto = StringBad(motto); StringBad * p = new StringBad(motto);
上面有四种使用拷贝构造的情况,第一种是最直接的拷贝构造使用方式,第二种和第三种可能使用拷贝构造函数直接创建ditto对象,也可能使用拷贝构造函数创建一个临时对象,然后将临时对象的值通过赋值运算符(没有自定义重载“=”就是编译器默认的赋值运算符)将内容赋值给ditto,这取决于具体实现。最后一个是生成一个匿名对象,并将匿名对象的地址赋给p指针。
当函数按值传递或者函数返回对象时都将使用拷贝构造函数。由于按值传递对象将调用拷贝构造函数,因此应该尽量按照引用传递对象,可以节省调用构造函数消耗的时间以及数据复制的空间。
+++
但是默认拷贝构造函数也是有问题的。
默认的拷贝构造函数将逐个复制非静态成员的值,因为是值复制,所以也叫做浅拷贝。默认拷贝构造函数即浅拷贝会有如下两个问题:
-
如果没有显式的定义拷贝构造函数,那么析构函数的调用次数肯定比构造函数的调用次数多的,因为默认拷贝构造函数也会调用析构函数,而我们没有显式的定义拷贝构造函数,因此调用次数上不平均。这意味着程序无法准确地记录创建对象的个数,因此只能显式的创建拷贝构造函数来统计。
-
最重要的一个问题,如果类中有用new创建的动态变量,则默认拷贝构造函数能整出点问题。
由于隐式的拷贝构造函数是按照值进行复制的,如下:
//A和B是对象 //str是new char创建的 A.str = B.str;
上述代码复制的并不是字符串本身,而是指向字符串的指针!!!即上述代码得到的不是两个字符串,而是两个指向同一个字符串的指针!!真相大白了家人们!之前我们说过默认拷贝构造函数也是要调用析构函数的,而我们的析构函数是自定义的delete,这就导致我们释放掉了指针指向的那个空间,那个空间已经没有字符串了,因此我们要访问字符串就会出现乱码,比如打印
A.str就可能会出错,但是有的编译器像vs会保留一次空间的值。更恐怖的是当B对象使用结束后也会调用析构函数释放掉str那片空间,但是str之前在调用默认拷贝构造函数的时候就已经没了,所以后果不可预测。**(本质上)**就是指针悬挂的问题+++
唯一解决办法就是定义一个显式构造函数,代码如下:
StringTemp::StringTemp(const StringTemp& st){ //引用计数 num_count++; len = st.size(); str = new char[len + 1]; //把st对象的str赋给本对象定义的str std:strcpy(str, st.str); }
可以看到必须定义显式拷贝构造函数的原因在于有一些类成员使用的是new初始化,指向数据的指针而不是数据本身。
-
-
赋值运算符
c++允许类对象赋值,并且自动为类重载赋值运算符,原型如下:
Class_name & Class_name::operator=(const Class_name&);接收并返回一个类对象的引用。+++
当将已经有的对象赋给另外一个对象的时候必调用这个,比如
StringTemp A; StringTemp B; ... //调用赋值运算符 A = B;一定要分清楚初始化与已有的对象给另一个对象赋值的区别
StringBad ditto = motto; StringBad ditto = StringBad(motto);
上面这两个代码就是初始化,但是有可能会调用赋值运算符,这个取决于编译器
+++
**赋值运算符也会出现相同的问题:数据受损。**和隐式拷贝构造函数一样的问题,解决办法就是提供深度赋值,但是要注意,赋值语算符重载的返回值是对象。
比如举个例子:
StringTemp& StringTemp::operator=(const StringTemp& st){ if(this == &st){ return *this; } delete [] str; len = st.size(); str = new char[len + 1]; std:strcpy(str, st.str); return *this; }
- 代码首先检查自我复制,如果是自己赋值自己,则返回*this,因为this是指针
- 如果地址不同,先释放掉str指向的内存。因为每个对象都有个str,但是我们要接收来自另一个对象的str,这样的话必须把自己对象的str所占用的内存给释放掉,这样不会浪费内存
- 接下来操作和显式拷贝构造一样。
+++
静态类成员函数
可以将成员函数声明为静态的,当类中函数成为静态的以后,有两个后果:
-
不能通过对象调用静态成员函数,此外静态成员函数都不能用this指针。
如果静态成员函数是在共有部分声明的,则可以使用类名+作用域解析符来调用,如下
//类中共有部分的static函数 static int HowMany(){ return num_strings; } //调用形式 int count = String::HowMany();
-
由于静态成员函数不与特定对象关联,因此只能使用静态数据成员。如上面代码,静态类成员函数可以访问静态类成员,但不能访问len,str这些变量。
当在类中使用new时,应该注意一下几点:
- 如果在构造函数中用new初始化指针成员,那么在析构函数中应该使用delete
- new和delete必须成对出现
- 应该定义一个复制构造函数,通过深拷贝将一个对象初始化为另一个对象
- 重载一个赋值运算符,通过深拷贝将一个对象复制给另一个对象。
当成员函数或者普通函数返回对象时,有几种返回方式可以选择:
- 返回指向对象的引用
- 指向对象的const引用
- const对象
-
返回指向const对象的引用
使用const引用的常见原因是提高效率。代码如下:
//version1 Vector Max(const Vector& v1, const Vector& v2){ if(...){ return v1; }else{ return v2; } } //version2 const Vector& Max(const Vector& v1, const Vector& v2){ if(...){ return v1; }else{ return v2; } }
- 返回对象的话会调用拷贝构造函数,而返回引用则不会。
- 引用指向的对象应该在调用函数执行时候存在
- 参数被声明为const对象,因此返回类型也得为const
+++
-
返回指向非const对象的引用
一般两种情况会这样,即不加const的引用:
-
重载赋值运算符,为了提高效率
String s1("hello"); String s2,s3; s3 = s2 = s1;
s2.operator=()的返回值被赋值给s3,因此返回String对象或者引用都可以,通过使用引用可以避免String的拷贝构造函数创建出来的新的临时的对象,提高效率。不加const是因为指向s2的引用可以对其进行修改而不是不变的。 -
重载
<<运算符String s1("hello"); cout<<s1<<"world";
在这里
operator<<(cout, s1)返回类型必须是ostream&,而不能是ostream的。如果是ostream,则要求调用ostream的拷贝构造函数,而ostream是没有共有的拷贝构造函数。
+++
-
-
返回对象
**使用场景:**如果返回的对象是调用函数中的局部变量,则不应该按引用方式返回,因为在被调用函数执行完成后,局部对象将调用其析构函数。当控制权重回调用函数手中(析构函数执行完出栈)时,引用指向的对象将不存在。这种情况下不要返回引用,而是返回对象就行
总之,如果函数要返回局部对象,则千万不要返回引用,而应该返回对象即可。
+++
先放一段代码:
class Act{...};
Act nice; //静态变量(外部变量)
int main(){
Act *pt = new Act; //动态变量
delete pt;
{
Act up; //动态变量
}
....
}分析上述代码析构函数被调用情况
- 如果对象是静态变量(外部、静态或来自命名空间),则在程序结束时候才会调用对象的析构函数。
- 如果对象是动态变量,当执行完该对象的程序块时就调用析构函数
- 如果对象是用new创建的,则当显式调用delete时才会调用析构函数。
c++程序执行构造函数的顺序如下:
- 调用构造函数
- 创建对象(对象在构造函数代码执行前被创建)
- 给类成员分配内存
- 执行构造函数内部代码,将值存储在内存中。
思考一个问题,一个类中有const成员变量,那如果用构造函数赋值会出现问题吗??
答案是会的,因为const数据成员必须在创建对象时就初始化,而不能在内部初始化。
所以c++提供了一类特殊的语法,成员列表初始化,形式如下:
Classy::Classy(int n, int m)::mem1(n), mem2(m),mem3(n*m){
...
}只有构造函数可以使用这种语法!!!
对于const成员和引用的类成员,也必须这样使用
+++
初始化工作是在对象创建时候完成的,还未执行括号中的任何代码,要注意一下几点:
- 这种语法只能用于构造函数
- 必须用这种语法初始化非静态const成员
- 必须用这种语法初始化引用数据成员
+++
C++11允许更直观的方式初始化,类内初始化:
class Classy{
int mem1 = 10;
const int mem2 = 20;
}上面代码与在构造函数中等价
+++
从一个类派生出另外一个类时,原始类成为基类,继承类成为派生类。也叫做父类和子类。
使用公有派生,基类的公有成员将成为派生类的公有成员;基类的私有部分也成为了派生类的一部分,但只能通过基类的公有和保护方法去访问。但是需要在派生类中添加自己的构造函数和自己所需的额外的数据成员和成员函数。
+++
由于派生类不能直接访问基类的私有成员,必须通过基类方法进行访问。那么就是说派生类构造函数不能直接设置哪些继承过来的数据,而必须使用基类的公有方法来访问私有的基类成员,具体说就是派生类构造函数必须是有基类构造函数。
创建派生类对象时,程序首先创建基类对象,也就是说基类对象应当在程序进入派生类构造函数之前被创建。c++使用成员初始化列表来完成,如下:
//RatedPlayer构造函数
RatedPlayer::RatedPlayer(unsigned int r, const string& fn, const string& ln, bool ht):TableTennisPlayer(fn, ln, ht){
rating = r;
}
RatedPlayer player1(1140, "mary", "duck", true);RatedPlayer构造函数把实参"mary", "duck", true赋给形参fn, ln, ht通过成员初始化列表,然后将这些实参传递给TableTennisPlayer构造函数中,TableTennisPlayer将创建一个对象,并将实参存储在对象中。然后程序进入RatedPlayer构造函数,完成RatedPlayer对象的创建,然后执行构造函数中的代码,将r赋值给rating。
但是如果没有成员列表初始化,程序还是要创建基类对象,就会使用默认的的基类构造函数。否则就显式的调用构造函数。
总结一下有关派生类构造函数的要点:
- 创建派生类对象前先创建基类对象
- 派生类构造函数应该通过成员初始化列表将基类信息传递给基类构造函数
- 派生类构造函数应该初始化新增的数据成员
释放对象的顺序与创建对象的顺序相反,即首先执行派生类的析构函数,然后执行基类的析构函数
基类构造函数主要负责初始化那些继承的数据成员,派生类构造函数主要用于初始化新增的数据成员。派生类构造函数总是调用一个基类的构造函数,可以使用成员列表初始化指明要使用的基类构造函数,否则使用默认的基类构造函数
+++
派生类与基类之间有一些特殊的关系:
-
派生类对象可以使用基类的方法,条件是该方法不是私有的
-
基类指针可以在不进行显式类型转换的情况下指向派生类对象
-
基类引用可以在不进行显式类型转换的情况下引用派生类对象
RatedPlayer player1(1140, "mary", "duck", true); TableTennisPlayer& rt = player1; TableTennisPlayer* pt = &player1;
**注意事项:**基类指针或者引用只能用于调用基类方法,不能使用rt或者pt来调用派生类方法。对于c++来说引用和指针类型要与赋给的类型匹配才行,但是对于继承来说是例外的。但是这种例外是单向的,即只能将基类的引用或指针赋给派生类对象,而不能将派生类对象的引用或指针赋给基类对象
c++有3中继承方式:公有继承,保护继承和私有继承。
公有继承是最常用的方式,他建立的是一种is-a的关系,即派生类对象也是一个基类对象。进而可以对基类对象执行的操作对派生类对象也可以。
举个例子,香蕉是一种水果,进而香蕉就是派生类,水果就是基类。香蕉可以继承水果类的重量和热量成员
公有继承不建立has-a的关系。比如午餐可能包含水果,但是午餐并不是水果。我们只能说午餐李有水果,但是午餐并不能从水果哪里继承,就只能has-a,将水果对象作为午餐类的数据成员。
公有继承不建立is-like-a的关系。比如人们说律师就像鲨鱼,但是律师并不是鲨鱼。
公有继承不建立is-implemented-as-a关系(作为……来实现)。例如可以用数组来实现栈,但从数组类派生出栈类是不合适的,因为栈并不是数组。
公有继承不建立uses-a关系。比如计算机可以使激光打印机,但是从计算机类派生出打印机类是没有意义的,当然了,可以使用友元函数或类来处理双方通信。
综上,c++中最多的还是is-a的关系!!
在使用继承的时候,最简单的就是对派生类对象使用基类的方法,不作任何修改。但很多时候我们都希望同一个方法在派生类和基类中表现得不同,即方法的行为应该取决于调用方法的对象。这种复杂的行为成为多态——方法随着上下文而异。多态公有继承有两种实现方式:
- 在派生类中重新定义基类的方法(重载)
- 使用虚方法
+++
//1. viewcount不是virtual的
void viewcount() const;
//2.viewcount是virtual的
virtual void viewcount() const;
//1情况下
Brass dom(arg1, arg2);
BrassPlus dot(arg1,arg2);
Brass& b1_ref = dom;
Brass& b2_ref = dot;
b1_ref.viewcount(); //使用Brass::viewcount()
b2_ref.viewcount(); //使用Brass::viewcount()
//2情况下
Brass dom(arg1, arg2);
BrassPlus dot(arg1,arg2);
Brass& b1_ref = dom;
Brass& b2_ref = dot;
b1_ref.viewcount(); //使用Brass::viewcount()
b2_ref.viewcount(); //使用BrassPlus::viewcount()首先方法前面加上关键字virtual时,这些方法被称为虚方法。
如果类方法没有使用virtual关键字,程序将根据引用或指针本身的类型来选择调用基类的方法还是派生类的方法。
如果类使用了virtual,程序将根据引用或者指针指向的对象的类型来选择方法。
经常在基类中将派生类会重新定义的方法称为虚方法,方法在基类中被声明为虚的以后,在派生类中将自动称为虚方法。但是,在派生类中将某些方法用virtual标注也是可以的。如果想在派生类中重新定义基类的方法,通常将基类的方法定义为虚的,因为这样程序会根据对象类型来选择调用的方法。
+++
虚析构函数
如果没有虚析构函数,那么程序结束时候,就只会调用对应于指针类型的析构函数,对于上述代码来说只会调用Brass类的析构函数。
如果析构函数是虚的,将会调用对象类型的析构函数,比如上面代码第二种情况,指针指向的是BrassPlus对象,调用BrassPlus的析构函数,然后自动调用基类的析构函数(基类和继承类那里有说)
因此必须要有虚析构函数,不然只能调用对应指针类型的那个类的析构函数,而不能调用对象对应类的析构函数。
+++
将源代码中的函数调用解释为执行特定的函数代码块成为函数名联编。在c语言中很简单,因为每个函数名对应一个不同的函数,没有重载。但是c++有重载了,编译器必须查看函数参数以及函数名称才能确定使用哪一个函数。
在编译过程中进行联编称为静态联编。编译器生成能够在程序运行时选择正确的虚方法的代码,成为动态联编。(dynamic binding)
+++
在c++中,动态联编通过指针和引用调用方法相关,由继承控制的。通常c++不允许将一种类型的地址赋给另外一种类型的指针,也不允许一种类型的引用指向另一种类型。但是指向基类的指针或者引用可以转换成派生类对象,而不必进行显示类型转换。
将派生类引用或指针转换为基类引用或指针成为向上强制转换,改规则是is-a关系的一部分,比如之前的BrassPlus 对象都是Brass对象,因为继承。反过来,将基类指针或引用转换为派生类指针或引用成为向下强制转换。如果不使用显式转换类型,向下强制转换是不允许的,因为is-a关系式不可逆的,派生类可以新增数据成员,但这些新增的数据成员不能应用与基类。
+++
问:为什么有两种联编同时默认是静态联编?
答:效率和概念模型。首先是效率,为了使得程序能够早运行阶段做策略,必须用一些方法来跟踪基类指针或引用指向的类型,会增加额外的处理开销。大多数情况下都不太会对基类方法重定义或重载,使用静态联编更合理。其次是概念模型,指的是有一些派生类中的成员函数不应该重新定义,就应该继承基类的定义。总之就是,如果要在派生类中重新定义基类的方法,就设置为虚方法,否则别设置虚方法。
虚函数表(vtbl),虚函数表指针(vptr)
首先要知道每一个派生类对象实际上是由两个部分组成的:
- 父类部分,包括成员变量,成员函数,vptr等这些都是共享给子类的,当然要加上权限限制
- 子类部分,子类自己定义的成员变量成员函数。
可以看到子类其实就是一个特殊的父类,享有父类的所有属性,是is-a的关系,因此子类可以强制转换成父类,通常是用dynamic_cast将子类指针转为父类指针。当转换成父类指针的时候,父类指针的访问域就变成了下图内存模型中的上半部分,下半部分属于子类的域是没有办法访问的。


通常函数的地址都在编译的时候确定好了,但虚函数的地址需要等到运行的时候才能确定,因为你无法确定一个基类的指针或引用指向的是基类对象还是派生类对象。综上,虚函数表指针是在对象执行构造函数的时候确定的,对于基类来说执行基类构造函数时直接把虚函数表填充为基类的虚函数地址,基类对象的vptr指向vtbl。对于派生类,创建对象时先执行基类构造函数,因此派生类对象的vptr指向的虚函数表vtbl里的内容首先是基类中的所有虚函数的地址,然后接着执行派生类构造函数,修改派生类对象vptr指向的虚函数表中的内容,将派生类的虚函数地址填进去。
+++
虚函数的内存分布
根据下面代码会给出一个该类的内存分布图:
class A {
public:
virtual void v_a(){}
virtual ~A(){}
int64_t _m_a;
};
int main(){
A* a = new A();
return 0;
}内存分布图如下:
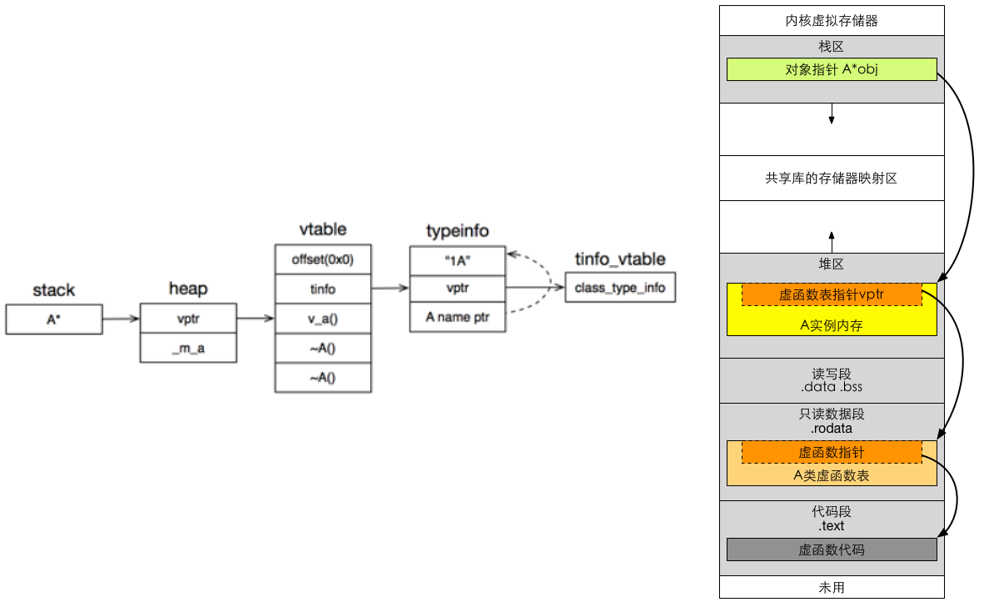
- main函数内部使用new创建的对象,因此主函数main的栈帧上有一个A类类型的指针指向堆里面分配好的A对象的实例(stack→heap)
- 在堆中,对象a的实例由上到下是一个vptr和声明的成员变量
- vptr指向虚函数表中的第一个虚函数起始地址
- 虚函数表中还有一个tinfo的指针指向typeinfo表,存储着A类的基础信息,包括父类名称、类名称
+++
虚函数执行过程
当调用一个虚函数时,首先通过对象内存中的vptr找到虚函数表vtbl,接着通过vtbl找到对应虚函数的实现区域并进行调用。 当一个类声明了虚函数或者继承了虚函数,这个类就会有自己的vtbl。vtbl核心就是一个函数指针数组,有的编译器用的是链表,不过方法都是差不多。vtbl数组中的每一个元素对应一个函数指针指向该类的一个虚函数,同时该类的每一个对象都会包含一个vptr,vptr指向该vtbl的地址。 在有继承关系时(子类相对于其直接父类)
- 一般继承时,子类的虚函数表中先将父类虚函数放在前,再放自己的虚函数指针。
- 如果子类覆盖了父类的虚函数,将被放到了虚表中原来父类虚函数的位置。
- 在多继承的情况下,**每个父类都有自己的虚表,子类的成员函数被放到了第一个父类的表中。**也就是说当类在多重继承中时,其实例对象的内存结构并不只记录一个虚函数表指针。基类中有几个存在虚函数,则子类就会保存几个虚函数表指针
下图是c++ primer plus中虚函数实现机制的示意图:
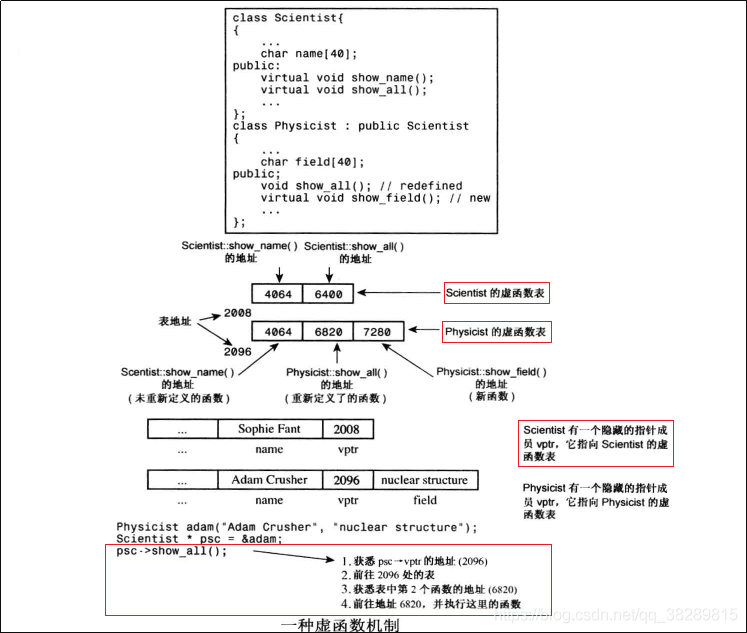
先看最下面,首先根据
Scientist* psc = &adam这局代码找到adam对象中的vptr为2096,然后找到vptr指向的2096地址的虚函数表,在上图中间位置,虚函数表示数组指针形式的。然后前往地址6820,并执行这里的函数。
总结一下调用过程:
- 首先获取对象内存中的vptr指针指向的虚函数表vtbl
- 进入vtbl,一般是数组指针形式的,找到对应虚函数的地址并调用
+++
性能分析
第一步是通过对象的vptr找到该类的vtbl,因为虚函数表指针是编译器加上去的,通过vptr找到vtbl就是指针的寻址而已。
第二部就是找到对应vtbl中虚函数的指针,因为vtbl大部分是指针数组的形式实现的
在单继承的情况下调用虚函数所需的代价基本上和非虚函数效率一样,在大多数计算机上它多执行了很少的一些指令
在多继承的情况由于会根据多个父类生成多个vptr,在对象里为寻找 vptr 而进行的偏移量计算会变得复杂一些
空间层面为了实现运行时多态机制,编译器会给每一个包含虚函数或继承了虚函数的类自动建立一个虚函数表,所以虚函数的一个代价就是会增加类的体积。在虚函数接口较少的类中这个代价并不明显,虚函数表vtbl的体积相当于几个函数指针的体积,如果你有大量的类或者在每个类中有大量的虚函数,你会发现 vtbl 会占用大量的地址空间。但这并不是最主要的代价,主要的代价是发生在类的继承过程中,在上面的分析中,可以看到,当子类继承父类的虚函数时,子类会有自己的vtbl,如果子类只覆盖父类的一两个虚函数接口,子类vtbl的其余部分内容会与父类重复。如果存在大量的子类继承,且重写父类的虚函数接口只占总数的一小部分的情况下,会造成大量地址空间浪费。同时由于虚函数指针vptr的存在,虚函数也会增加该类的每个对象的体积。在单继承或没有继承的情况下,类的每个对象只会多一个vptr指针的体积,也就是4个字节;在多继承的情况下,类的每个对象会多N个(N=包含虚函数的父类个数)vptr的体积,也就是4N个字节。当一个类的对象体积较大时,这个代价不是很明显,但当一个类的对象很轻量的时候,如成员变量只有4个字节,那么再加上4(或4N)个字节的vptr,对象的体积相当于翻了1(或N)倍,这个代价是非常大的。
+++
虚函数注意事项
-
构造函数
首先要知道构造函数不能是虚函数。
原因:如果构造函数时虚的,也要从虚函数表中找,但是创建对象要用到构造函数,如果构造函数是虚的话,vptr指针就没有了,因为你找不到构造函数,构造不出对象,构造不出对象你就没有vptr。而且在构造函数中调用虚函数实际执行的肯定是父类的函数,因为你派生类的都没构造好,调个锤子。
-
析构函数
析构函数当然是虚的,除非类不做基类。并且通常要给基类一个虚析构函数,即使他并不需要
原因:(主要针对基类指针来销毁派生类对象这个行为)如果析构函数不是虚的,派生类析构的时候调用的是基类的析构函数,而基类的构造函数只是对基类部分做了析构,从而导致派生类部分出现内存泄露。如果加了virtual,则先回调用派生类对象的析构函数,然后再调用基类的析构函数
-
友元
友元不能是虚函数,因为友元又不是类成员,而只有类成员才能使虚函数。
但是友元函数可以是虚成员函数
-
内联函数
虚函数在c++中叫做dynamic binding。内联函数为了提高效率,通常是在编译期间对调用内联函数的地方做代码替换而已,所以内联函数对于程序中频繁调用的小函数非常有用。同时要知道,再类中定义的函数,会被默认的当成内联函数。
所以,当使用基类指针或引用来调用虚函数的时候,不能使用内联函数。
但是使用对象(并不时指针或者引用)来调用时,可以当做内联函数,因为编译器是默认静态联编的。
-
静态成员函数
static成员不属于任何类对象或类实例,所以即使给此函数加上virutal也是没有任何意义的。
此外静态与非静态成员函数之间有一个主要的区别,那就是静态成员函数没有this指针,从而导致两者调用方式不同。
虚函数依靠vptr和vtable来处理。vptr是一个指针,在类的构造函数中创建生成,并且只能用this指针来访问它,因为它是类的一个成员,并且vptr指向保存虚函数地址的vtable,因此虚函数的执行顺序是:虚函数的调用关系:this -> vptr -> vtable ->virtual function
对于静态成员函数,它没有this指针,所以无法访问vptr. 这就是为何static函数不能为virtual。
-
纯虚函数
析构函数可以是纯虚的,但纯虚析构函数必须有定义体,因为析构函数的调用是在子类中隐含的。
+++
关键字protected与private相似,再类外只能通过共有方法来访问protected成员
private和protected的区别主要在继承里面。派生类的成员可以直接访问基类的保护成员,但不能访问基类的私有成员。
对于外部世界来说,保护成员的行为和私有成员一致;对派生类来说,保护成员的行为和公有成员一致
在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。而针对每种动物的方法又有所不同,此时需要使用多态特性,也就需要在基类中定义虚函数。
纯虚函数是在基类中声明的虚函数,它要求任何派生类都要定义自己的实现方法,以实现多态性。实现了纯虚函数的子类,该纯虚函数在子类中就变成了虚函数。
定义纯虚函数是为了实现一个接口,用来规范派生类的行为,也即规范继承这个类的程序员必须实现这个函数。派生类仅仅只是继承函数的接口。纯虚函数的意义在于,让所有的类对象(主要是派生类对象)都可以执行纯虚函数的动作,但基类无法为纯虚函数提供一个合理的缺省实现。所以类纯虚函数的声明就是在告诉子类的设计者,“你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。
含有纯虚函数的类称之为抽象类,它不能生成对象(创建实例),只能创建它的派生类的实例。抽象类是一种特殊的类,它是为了抽象和设计的目的为建立的,它处于继承层次结构的较上层。抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出。如果派生类中没有重新定义纯虚函数,而只是继承基类的纯虚函数,则这个派生类仍然还是一个抽象类。如果派生类中给出了基类纯虚函数的实现,则该派生类就不再是抽象类了,它是一个可以建立对象的具体的类。
代码如下:
//baseDMA.h
#ifndef BASEDMA_H_
#define BASEDMA_H_
#include <iostream>
class baseDMA{
private:
char * label;
int rating;
public:
baseDMA(const char * s = "null", int r = 0); //构造函数
baseDMA(const baseDMA & bd); //复制构造函数
baseDMA & operator=(const baseDMA & bd); //赋值运算符函数
virtual ~baseDMA();
friend std::ostream & operator<<(std::ostream & os, const baseDMA & bd); //输出运算符,友元函数
};
//不用动态内存分配的派生类
class lacksDMA : public baseDMA
{
private:
enum {LEN = 40};
char color[LEN];
public:
lacksDMA(const char * s = "null", int r = 0, const char * c = "none");
lacksDMA(const baseDMA & bd, const char * c = "none");
//友元函数并不属于类,所以不能被继承,必须自己写哦
friend std::ostream & operator<<(std::ostream & os, const lacksDMA & ld);
};
//用动态内存分配的派生类
class hasDMA : public baseDMA
{
private:
char *style;
public:
hasDMA(const char * s = "null", int r = 0, const char * sty = "none");
hasDMA(const baseDMA & bd, const char * sty = "none");
~hasDMA();//析构函数
hasDMA(const hasDMA & hd);//复制构造函数
hasDMA & operator=(const hasDMA & hd);//赋值运算符函数
//友元函数并不属于类,所以不能被继承,必须自己写哦
friend std::ostream & operator<<(std::ostream & os, const hasDMA & ld);
};
#endif // BASEDMA_H_-
第一种情况,基类使用new,派生类不使用new
对应上述代码中不用动态内存分配的派生类。不需要为lackDMA类定义显式析构函数、拷贝构造函数、赋值运算符。
不需要析构函数。如果派生类为定义析构函数则编译器将定义一个不执行任何操作的默认构造函数。但派生类的默认构造函数需要执行完自身代码后调用基类构造函数。由于派生类lackDMA成员没有动态分配内存,所以不用做什么操作。
不需要拷贝构造函数。首先之前说过默认拷贝构造函数对有动态内存分配的成员是不合适的,但是对于没有动态内存分配的成员是合适的。但是派生类是从baseDMA类继承而来的,也是不需要的,原因如下。派生类的默认拷贝构造函数会使用显式的baseDMA拷贝构造函数来复制lackDMA对象的baseDMA部分。因此如果派生类没有动态内存分配的话,用默认拷贝构造函数是可以的。
不需要赋值运算符重载。跟上面一样,派生类的默认赋值运算符将会使用基类的赋值运算符对基类组件进行赋值
-
第二种情况,基类使用new,派生类使用new
上述代码中hasDMA就是使用了动态内存分配。在这种情况下必须为派生类定义显式的析构函数、拷贝构造函数和赋值运算符
+++
在现实生活中,一些新事物往往会拥有两个或者两个以上事物的属性,为了解决这个问题,C++引入了多重继承的概念,C++允许为一个派生类指定多个基类,这样的继承结构被称做多重继承。(派生类有两个或两个以上的直接基类) 当一个派生类要使用多重继承的时候,必须在派生类名和冒号之后列出所有基类的类名,并用逗好分隔。如下:
class Derived : public Base1, public Base2, … {};多继承会出现问题:在派生类中对基类成员的访问应该是唯一的。但是,在多继承情况下,可能造成对基类中某个成员的访问出现了不一致的情况,这时就称对基类成员的访问产生了二义性。
-
问题1:派生类在访问基类成员函数时,由于基类存在同名的成员函数,导致无法确定访问的是哪个基类的成员函数,因此出现了二义性错误。
代码如下:
class Base1 { public: void fun(){cout<<"base1 "<<endl;}; }; class Base2 { public: void fun(){cout<<"base2 "<<endl;}; }; class Derived:public Base1,public Base2{}; int main() { Derived obj; obj.fun(); //产生歧义,编译时出错 return 0; }
解决办法有两个:
-
使用作用域运算符指明访问的是base1的还是base2的fun函数。
obj.Base1::fun(); //指明访问base1的fun函数 obj.Base2::fun(); //指明访问base2的fun函数
-
在派生类中重定义该函数
-
-
问题2:当一个派生类从多个基类派生时,而这些基类又有一个共同的基类,当对这个共同的基类中成员变量进行访问时,可能出现二义性问题。
代码如下:
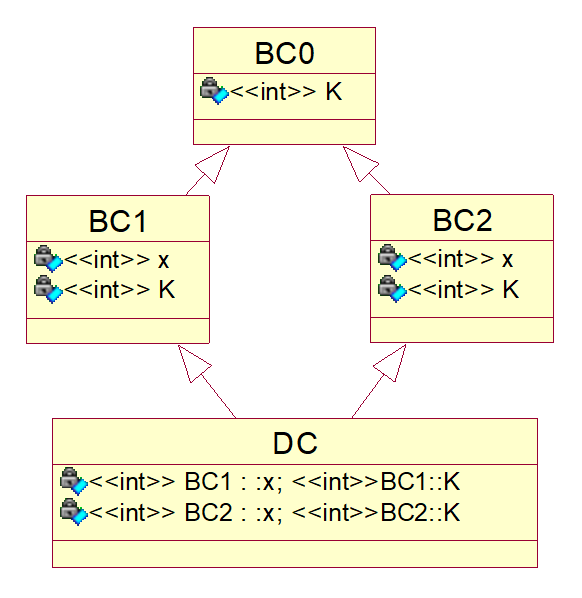
class BC0 { public: int K; }; class BC1 : public BC0 { public: int x; }; class BC2 : public BC0 { public: int x; }; class DC : public BC1, public BC2{ };
类的基础结构图如下:
解决方法也是两个:
-
还是使用作用域运算符,指明访问哪一个基类的数据
d.BC1::x = 2; // from BC1 d.BC2::x = 3; // from BC2 d.K = 4; // error C2385: 对"K"的访问不明确(编译错误) d.BC1::K = 5; // from BC1 d.BC2::K = 6;
-
使用虚基类。产生二义性的最主要的原因就是BC0在派生类DC中产生了2个对象,从而导致了对基类BC0的成员k访问的不一致性。要解决这个问题,只需使这个公共基类Base在派生类中只产生一个子对象即可。
class BC0 { public: int K; }; class BC1 : virtual public BC0 { public: int x; }; class BC2 : virtual public BC0 { public: int x; }; class DC : public BC1, public BC2 { }; void main( ) { DC d; //虚继承使得BC0仅被DC间接继承一份 d.K = 13; // OK }
-
+++
-
默认构造函数
默认构造函数要么没有参数,要么所有参数都有默认值才行。如果类为定义任何构造函数,编译器将自动定义一个默认构造函数用来创建对象。
如果派生类构造函数的成员初始化列表没有显式的调用基类构造函数,则编译器将使用基类的默认构造函数来构造派生类对象的基类部分。
-
拷贝构造函数
拷贝构造函数接受其所属类的对象作为参数,在下面几种情况下将使用拷贝构造函数:
- 将新对象初始化为一个已存在的对象
- 按值将对象作为参数传递给函数
- 函数按值类型返回对象
- 编译器临城临时对象
编译器会默认提供拷贝构造函数,但不提供具体定义。当类中有动态内存分配的情况时需要自定义拷贝构造函数
-
赋值运算符
默认的赋值运算符用于处理同类对象之间的赋值。
切记,不要讲赋值和初始化搞混了!!!如果语句创建新的对象则使用初始化,如果不是新鲜创建的对象则是赋值
-
构造函数
构造函数不同于其他类方法,因为他创建新对象,而其他类方法仅仅是被现有对象调用,这是构造函数不被继承的原因。
如果构造函数能被继承,表示派生类对象可以使用基类对象的方法,但是构造函数在执行的时候,对象并不存在。
-
转换
默认是隐式的转换,从参数类型到类类型的转换
在构造函数中使用关键字
explicit将禁止进行隐式转换,代码如下:class Star{ public: explicit Star(const char*); ... }; int main(){ Star north; north = "polaris"; //不允许 north = Star("polaris"); //可以转换 }
要将类对象转换成其他类型需要定义相应的转换函数,前面说过了。转换函数可以使没有参数的类成员函数,也可以是返回类型是目标类型的函数
Star::Star double(){...} //将star类转换成double Star::Star const char*(){...} //将star类转换成const char
-
按值传递与传递引用
在编写参数类型是类对象的函数时,应该按照引用而不是值来传递对象。这样做是为了提高效率。因为按值传递对象将会涉及到临时拷贝,调用拷贝构造函数,然后调用析构函数,调用这些函数需要花费时间,当对象非常大的时候就会显得很耗时。
另外如果不修改对象就传const。
按引用传递对象的另一个原因就是在继承使用虚函数的时候,被定义为接受基类引用参数的函数可以接受派生类
-
返回对象和返回引用
应该返回引用而不是类对象的原因在于返回对象涉及生成对象的临时副本,因此调用对象的时间成本包括调用拷贝构造函数来生成副本所需要的时间和调用析构函数删除副本所需要的时间。返回引用可以节省时间和内存。
其实直接返回对象与函数参数按值传递类似
但有时候必须返回对象,而不涉及返回引用。函数不能返回在函数中创建的临时对象的引用,因为当函数结束时,临时对象将会消失,引用是非法的。在这种情况下应该返回对象,以生成一个程序可以使用的副本。
+++
c++提供了两种模板机制:函数模板和类模板
含义:建立一个通用的函数,其函数返回值类型和形参类型可以不具体指定,用一个虚拟类型代表
语法如下:
template<typename T>
函数声明定义解释:
- template——声明创建一个模板
- typename——表明后面符号的一个数据类型,也可以用class代替
- T就是数据类型,抽象出来
调用方式(重要):
-
自动类型推导
mySwap(a, b) -
显式指定类型
mySwap<int>(a, b)
意义:
模板将数据类型参数化,还是为了编程方便
+++
模板注意事项:
- 自动类型推导,必须推导出一致的数据类型T才可以使用。也就是说参数类型和你模板定义的得一致才行。
- 模板必须要确定出T的类型
普通函数与模板函数的区别:
- 普通函数调用时可以发生自动类型转换(隐式类型转换)
- 如果使用函数模板,自动类型推导的话,则不会发生隐式转换
- 如果使用函数模板,显式指定类型,则可以发生隐式转换
普通函数与函数模板的调用规则:
-
优先调用普通函数
-
可以使用空模板参数来强制调用模板函数
myPrint<>(arg1, arg2,...) -
函数模板也可以重载
-
如果函数模板可以产生更好的匹配,优先调用函数模板
+++
定义:建立一个通用类,类中的成员的数据类型可以不具体制定,和函数模板差不多
类模板和函数模板的区别:
-
类模板没有自动类型推导的使用方式,只有显式指定参数类型
template<class T, class m> class Person{.....}; Person p1; //error!! Person<string, int> p2; //correct!!
-
类模板在模板参数列表中可以有默认参数
template<class T, class m = int> class Person{.....}; Person<string> p2; //正确!!
类模板中成员函数创建时间:
-
普通类中的成员函数在编译的时候就创建
-
类模板中的成员函数在调用的时候才会创建
class MyClass1{ void show1(){cout<<"show1";} }; class MyClass2{ void show2(){cout<<"show2";} }; template<class T> class Myclass_template{ T obj; void showClass1(){ obj.show1(); } void showClass2(){ obj.show2(); } }; int main(){ Myclass_template<MyClass1> m1; m1.showClass1(); //编译不报错,运行不报错 m1.showClass2(); //编译不报错,运行时候报错 }
类模板对象做函数参数:
就是类模板实例化出的对象,作为参数的形式传入函数
-
指定传入的类型 —— 直接显示对象的数据类型
void print(Person<string, int>&p);
-
参数模板化 —— 将对象中的参数变为模板进行传递
template<class T1, class T2> void print(Person<T1, T2>& p);
-
整个类模板化 —— 将整个对象类型模板化进行传递
template<class T> void print(T& p);
类模板与继承:
-
当派生类继承基类的一个类模板时,子类在声明时,要指定出分类中的T类型
template<class T> class Father{ T m; }; //报错 class Son: public Father{ }; //正确 class Son: public Father<int>{ };
因为子类要继承父类中的成员变量,但是模板没有指定内存大小,所以是不确定的,而不确定性是c++所嗤之以鼻的。因此继承的时候得指定要继承模板的数据类型才行。
但是这样不灵活,父类中的类型就被定死了,有违背c++灵活编程,所以这种方法不太实用
-
如果不指定,编译器无法给子类非配内存
-
如果要灵活的话,子类也需变为类模板
template<class T1, class T2> class Son: public Father<T2>{ T1 obj; };
类模板成员函数的类外实现
//构造函数类外实现
template<class T1, class T2>
Person<T1, T2>::Person(T1 name, T2 age){}
//成员函数类外实现
template<class T1, class T2>
void Person<T1, T2>::show(){}类模板分文件编写
出现问题:类模板中成员函数创建时机是在调用阶段,导致分文件编写是链接不到。
解决方案:
-
直接包含.cpp源文件
-
将声明和实现写到同一个文件中,并更改后缀名成.hpp(主流实现)
#pragma once //防止头文件重复包含 #include<iostream> using namespace std; //类模板与继承 template<class T> class Baba { public: void fun(); }; //成员函数类外实现 //第二种写法 template<class T> void Baba<T>::fun() { cout << "成员函数类外实现" << endl; }
上述文件要改成.hpp后缀