Este repositório representa o projeto apresentado pela equipe 3GTeam no Hackathon da A3Data no mês de Junho de 2021.
Onde os times devem implementar pipeline de extração, transformação e disponibilização de dados. Após extração, limpeza, organização e estruturação dos dados, as perguntas chave do desafio devem ser respondidas de maneira visual.
Perguntas Chave:
- Nos últimos 10 anos, quais foram os salários médios de homens e mulheres que trabalham com tecnologia na região sudeste do Brasil por ano?
- Nos últimos 10 anos, quais foram os salários médios das pessoas por nível de escolaridade que trabalhavam no setor de agronegócio na região sul do Brasil?
- Entre os setores de tecnologia, indústria automobilística e profissionais da saúde, qual deles teve o maior crescimento? Qual foi o número de trabalhadores em cada setor por ano?
- Nos últimos 10 anos, quais foram os setores que possuem, em cada ano, o maior número de trabalhadores que possuem jornada semanal inferior a 40h?
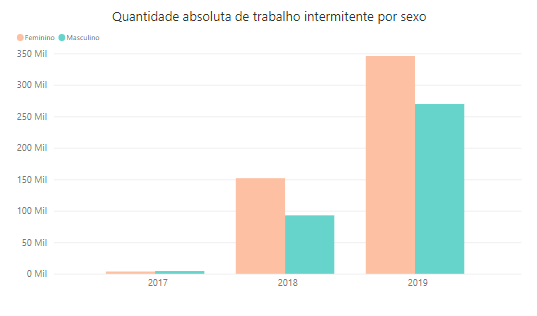
- Qual é o número absoluto de pessoas por cada categoria de sexo que realizaram trabalho intermitente em cada um dos últimos anos?
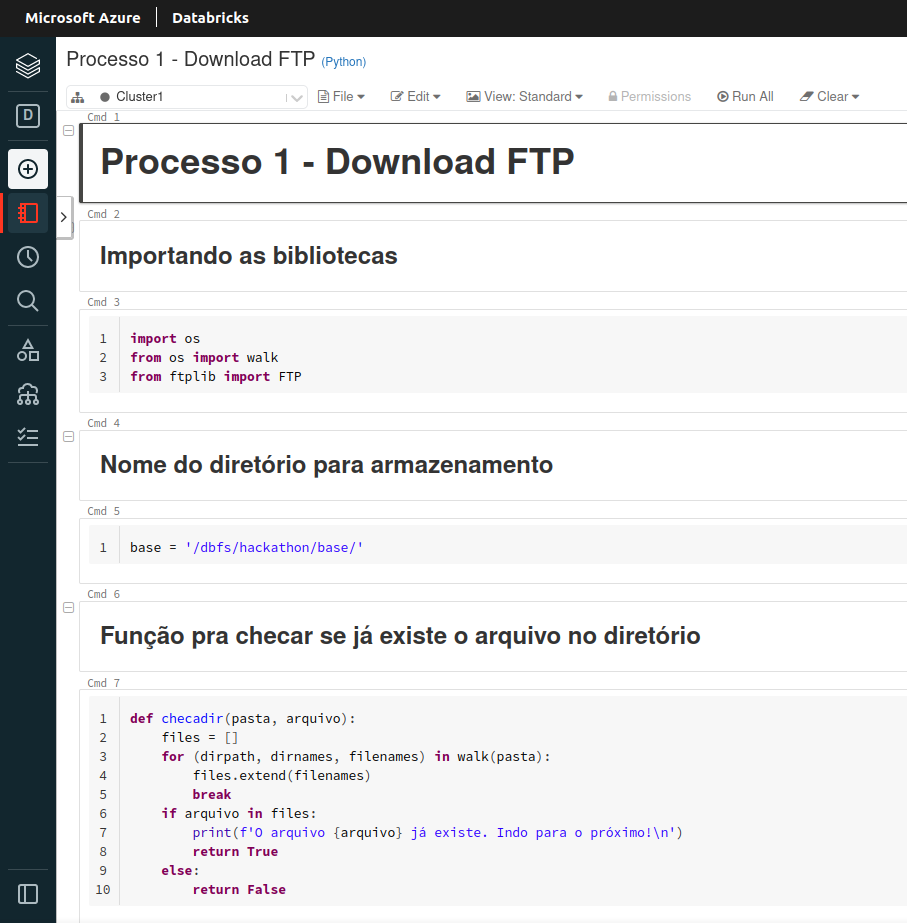
O projeto consiste na construção de um Pipeline de ETL dos dados abertos da RAIS disponibilizados pelo governo em um servidor FTP (ftp://ftp.mtps.gov.br/pdet/microdados/RAIS/) do Ministério do Trabalho.
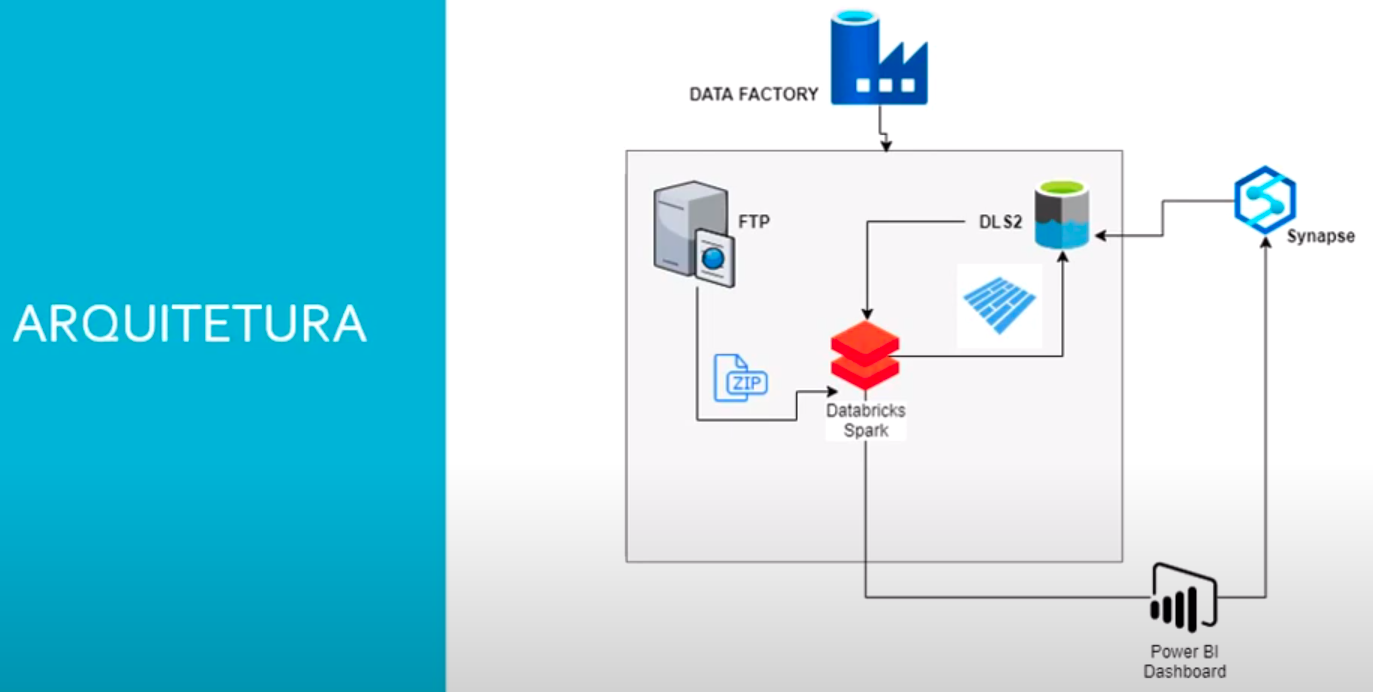
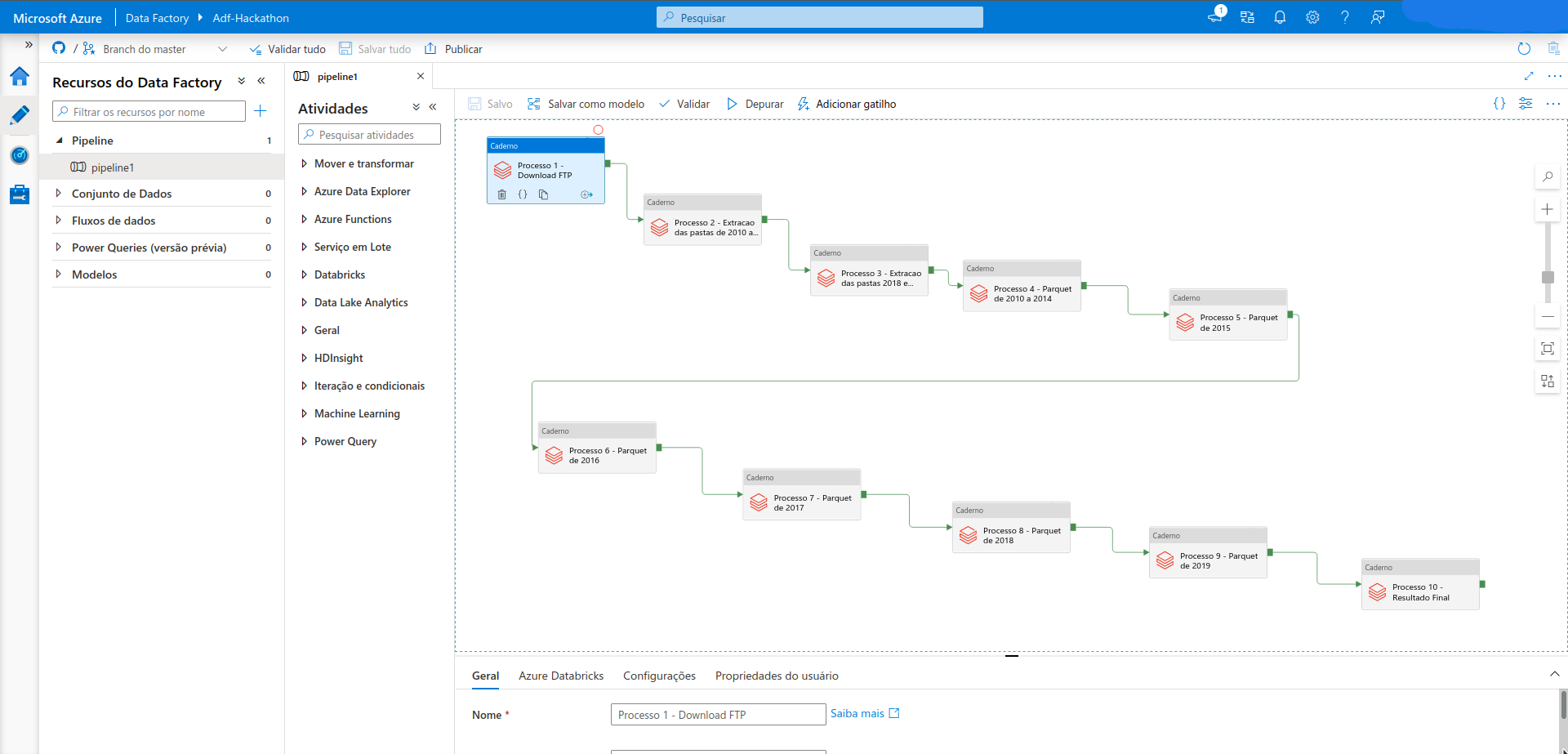
A automatização do processo foi feito em Python através de Notebooks do Databricks e a orchestração do pipeline feita no DataFactory. O armazenamento foi realizado no Data-lake do Azure. O processamento dos dados foram feito em PySpark em cluster Spark do Databricks. O Synapse Analytics criou as tabelas externas referenciando ao Datalake para serem visualizados em Dashboad via Power BI.
Todo o código-fonte do projeto encontra-se nesse repositório!
O vídeo de apresentação pode ser acompanhado aqui no youtube: https://www.youtube.com/watch?v=hIQnx7KVDd8
- Extração dos arquivos da RAIS de um servidor FTP do Ministério do Trabalho
- Descompactação dos arquivos 7Z para txt
- Processamento das bases, limpeza e tratamento dos dados e criação de tabelas no Databricks
- Armazenamento da base completa em formato Parquet no data lake
- Utilização do Azure Synapase para criação de tabelas externas referenciando o local dos arquivos parquet no data lake
- Power BI para visualizção dos dados no Synapse
-
Data Factory - Orquestração do Pipeline (Notebooks)

-
Databricks - Processamento em Spark do download, extração, limpeza e tratamento dos dados

-
Data Lake Storage Gen2 - Armazenamento dos dados txt e parquet

-
Synapse - Criação de tableas externas referenciando o local dos dados no data lake

-
Power BI - Visualização dos dados



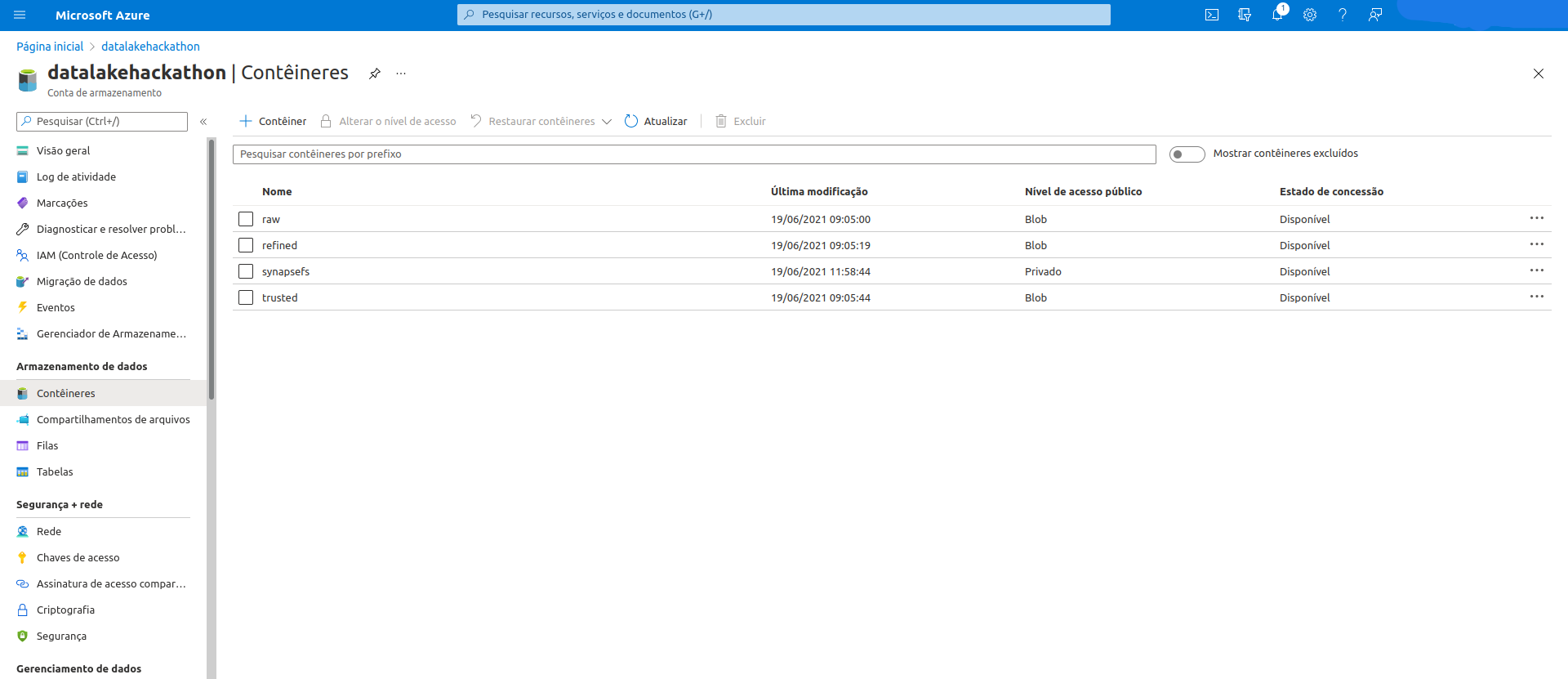



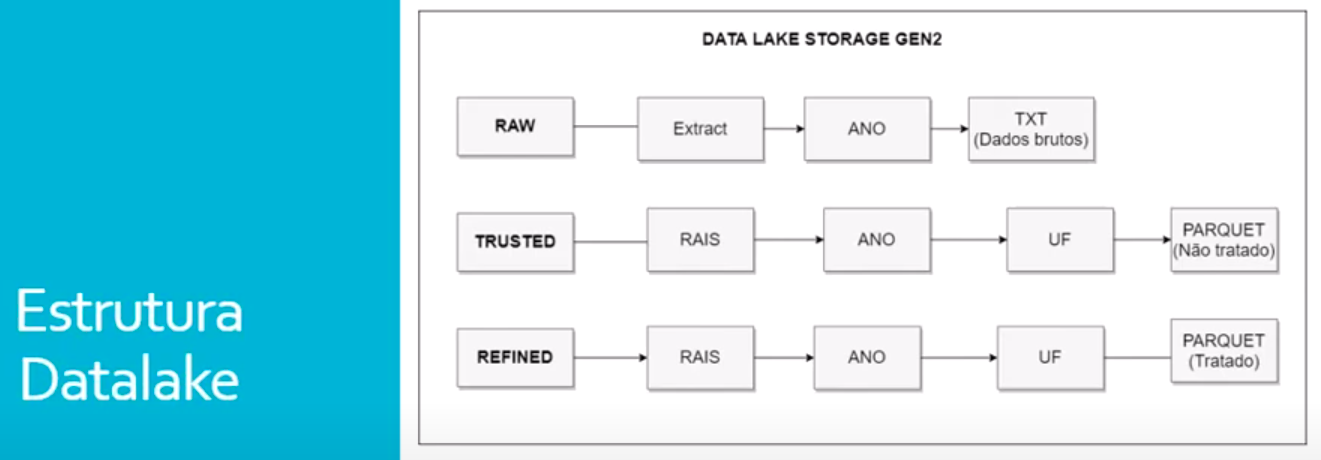
Decidimos estruturar o Datalake em 3 camadas:
- A camada RAW onde fica os dados brutos baixados e descompactados.
- A camada TRUSTED onde fica os dados brutos armazenados em Parquet para possíveis consultas e Insights no futuro.
- A camada REFINED onde fica os dados tratatos e processados pelo Spark para ser consumido pelo Synapse e PowerBI.
O custo do projeto envolveu desde o desenvolvimento a implantação do mesmo.
Está diretamente relacionado:
- Armazenamento dos dados no Datalake: 21gb de dados compactados, 274gb de dados descompactados e dados tratados.
- Processamento dos dados do cluster Spark no Databricks.
- Recursos do Azure: Worspace Databricks, Synapse Analytics e DataFactory.
