[BUG] The responses from LLM studio and HF differ greatly #24
Labels
type/bug
Bug in code
Comments
|
Hi @tomasonjo The reason is that you need to align the prompting. With default setting, we are adding an Which outputs An additional newline at the start also usually works well and I added it above, you can play with the prompt and the inference settings a bit. We have an open issue to generate an automatic model card on HF to exactly describe how a prompt needs to look like based on the settings of the experiment: #5 |
|
Thanks for the prompt response, loving the tool. Will turn this into a blog post next week! |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
🐛 Bug
I am not sure if this is a bug, but just my lack of understanding. However, I have fine-tuned a model (EleutherAI/pythia-1b) to generate Cypher statement. In the studio chat, it all looks fantastic:
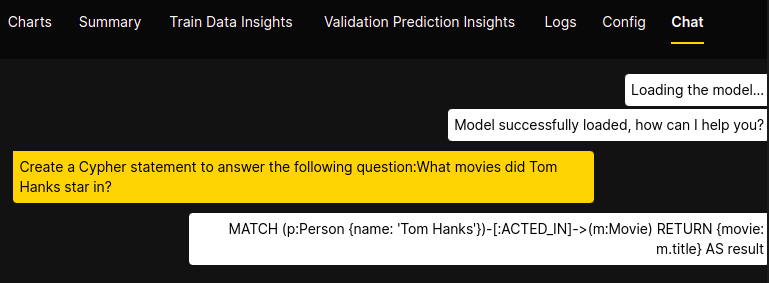
I have uploaded the weight to HF, and tried to replicate the text generation with transformers:
I get the following result:
Create a Cypher statement to answer the following question:What movies did Tom Hanks star in?Create a movieCreate a movieCreate a movieSend this message to:Create a movieCreate a movieSend this message to:Create a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreate a movieCreateWhat am I missing?
To Reproduce
I've tried both
AutoModelForCausalLMandGPTNeoXForCausalLMI can share the training data if needed, and have also made the HF model public
The text was updated successfully, but these errors were encountered: