[backport v1.1] [ENHANCEMENT] Maintenance mode doesn't drain the node #3363
Comments
Pre Ready-For-Testing Checklist
|
|
Move back to |
|
Ran test plan from linked comment on Harvester
PASS
FAIL
PASS
PASS
FAIL |

|
I retested this in a 4 node physical setup and it worked fine. However it did successfully move the VMs to the node and turned it back on. Is that the desired functionality? |
VMs should always be migrated to other nodes when its host entering maintenance; and if migrated VMs be restart (not soft reboot), it migt be host back to the origin node (if the node is working), it is expected. |
|
Tested in
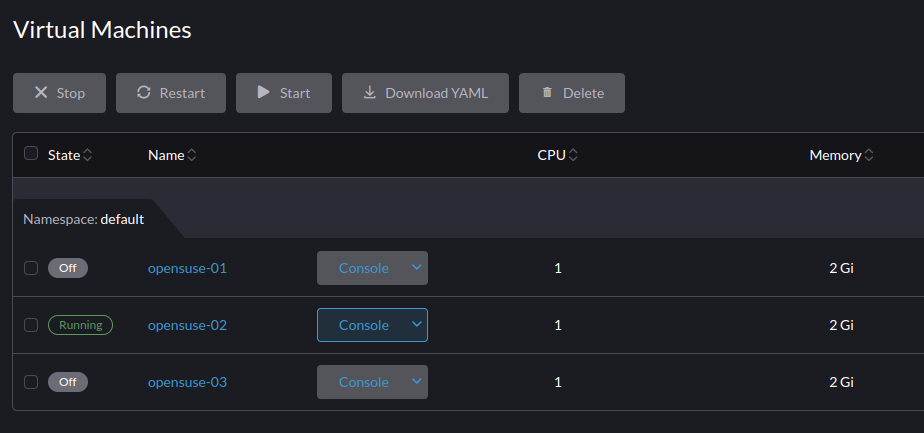
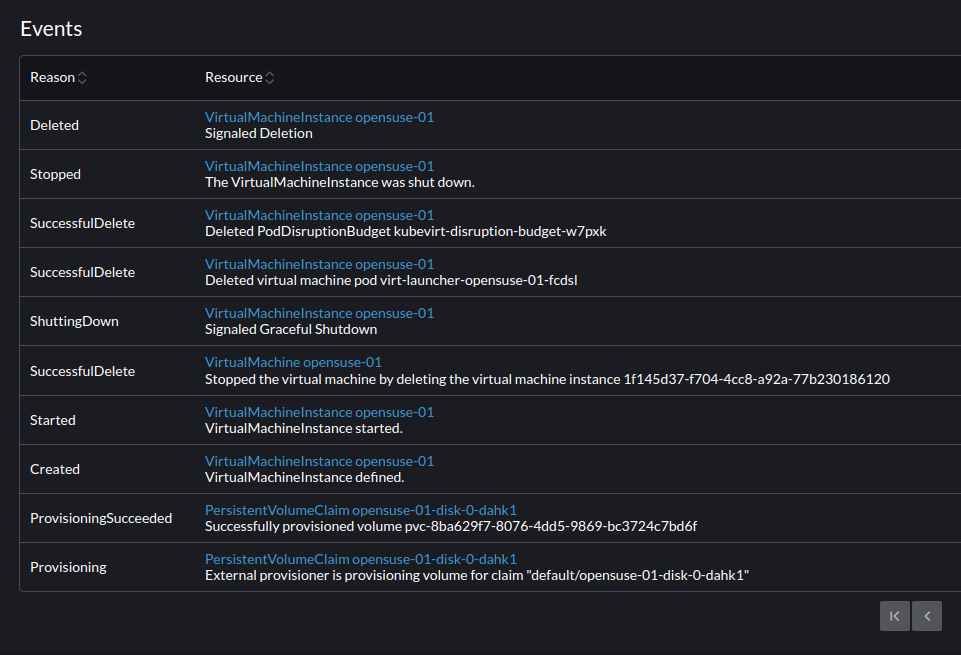
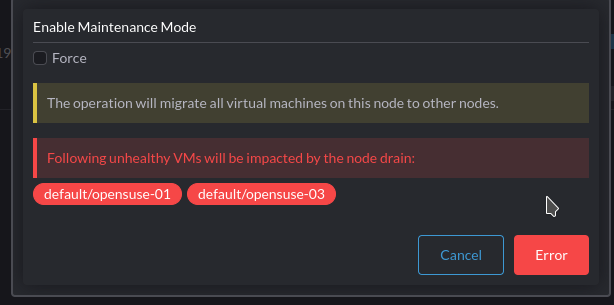
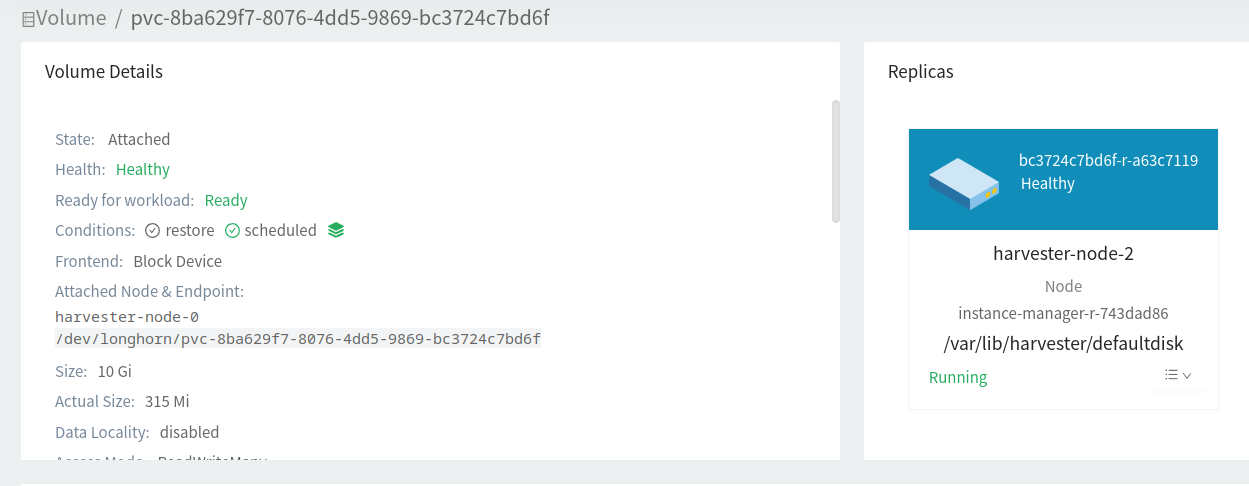
PASSThis seems to be working. It gave the error then it shutdown the VMs. The VM could not be turned back on after the shutdown. It just detaches the volume in Longhorn. The host is showing as cordoned. When I uncordon the host it will allow you to turn on the VM again and it comes up successfully.
|


backport the issue #2723
The text was updated successfully, but these errors were encountered: