reporting: Start span start line mis-calculation #299
Assignees

Labels
Comments
|
What determines if a report span should be |
|
When the |
|
It would be interesting to see the col:row start and end points for this example. |
feds01
added a commit
that referenced
this issue
Jun 21, 2022
feds01
added a commit
that referenced
this issue
Jun 21, 2022
feds01
added a commit
that referenced
this issue
Jun 21, 2022
kontheocharis
pushed a commit
that referenced
this issue
Jun 28, 2022
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
In the following error report:
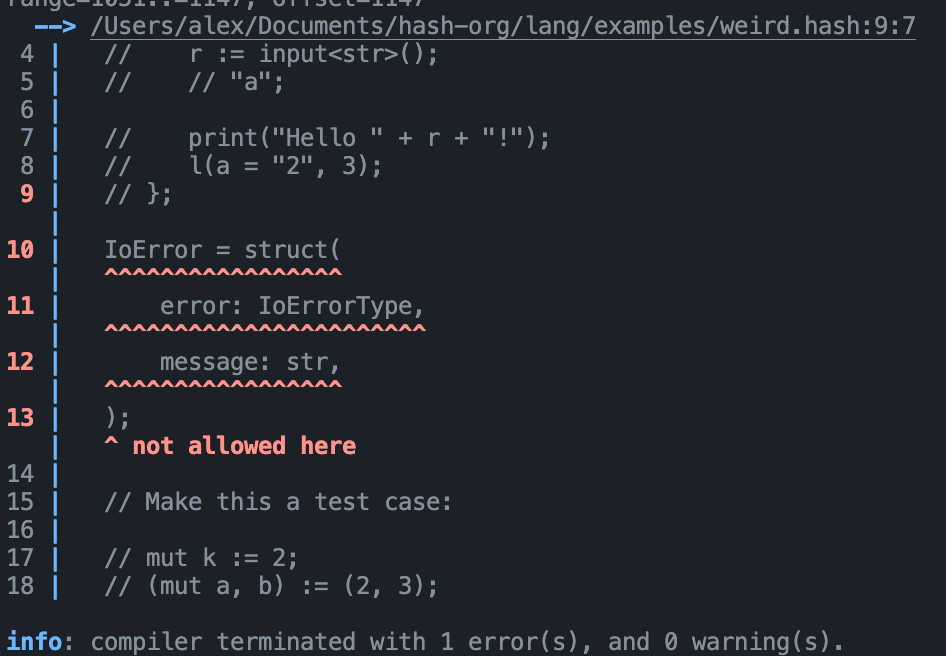
The highlighter mistakingly highlights the
9line number. The span of the expression does not actually begin on the 9th line. This might be a mistake within the lexing implementation or a miscalculation within the report offset to(col, row)calculation. It's clear that the line of the span is for some reason being recorded as the end of line 9 where there is a\ncharacter at the end.Further investigation yielded that the actual span of expression (as printed from the raw source is):
Ideally, the report should not highlight the line number 9, like so:
This could be fixed by changing
offset_col_rowby not counting the\nin the case of the initial span offset, an implementation could be:The text was updated successfully, but these errors were encountered: