On Distinguishability Criteria for Estimating Generative Models #25
Comments
Motivation to read this paperAfter I read the paper "Adversarial Contrastive Estimation" (#23), which replaces the original fixed noise generator in noise contrastive estimation (NCE) with the dynamic noise generator using with GAN training, some questions like "How does NCE relate to GANs?", "NCE is closely related to MLE, and how about GANs?" naturally rises in my mind. This paper compares MLE, NCE, GAN and gives several initial answers to:
In conclusion, the analysis shows that GANs are not as closely related to NCE as previously believed.
Comparison (from NIPS 2016 Tutorial: Generative Adversarial Networks or watch video from 1:00:17)
Similarities
Different p_{c}
Different goals
Different training objectives
Different stationary points when converges
Different convergence properties
NCE can implement MLE: Self-Contrastive Estimation (SCE)
GANs cannot implement MLESee derivation in the paper. Reference |



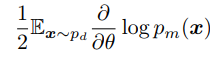
Metadata
The text was updated successfully, but these errors were encountered: