timer的优化故事 #10
Description
前几天nodejs发布了新版本4.0,其中涉及到一个更新比较多的模块,那就是下面要介绍的timer模块。
timers: Improved timer performance from porting the 0.12 implementation, plus minor fixes (Jeremiah Senkpiel)#2540, (Julien Gilli)nodejs/node-v0.x-archive#8751nodejs/node-v0.x-archive#8905
之前也对timer模块有过比较多的研究,断断续续的看过这个模块在github上的一些改动,于是借着这次机会整理一下自己对timer模块的理解,和小伙伴们一起分享timer模块的优化过程。
使用场景
也许你在使用nodejs开发项目时并没有使用到timer模块,诸如setTimeout以及setInterval和setImediate方法等等。但如果你开发的是web项目,那么你的项目中一定涉及到了timer模块。
细心的同学在平时的http接口开发调试中可能会注意到,每个http的request header里都有一个Connection:keep-alive标识,这是http/1.1开始引入的,表示客户端需要和服务端一直保持着tcp连接。当然了,这个连接不能就这么一直保持着,所以一般都会有一个超时时间,超过这个时间客户端还没有发送新的http请求,那么服务器就需要自动断开从而继续为其他客户端提供服务。
nodejs提供的http服务器便是采用timer模块来满足这种请求,每一个新的连接到来构造出一个socket对象,便会调用socket.setTimeout设置一个定时器用于超时后自动断开连接。
设计
在nodejs开发的web项目中,timer模块的使用频率是非常高的,每一个新的连接到来都会设置它的超时时间,而且每个连接的超时时间都一样,在http server中默认是2 * 60 * 1000ms。nodejs使用c++包裹的Timer对象来实现定时器功能,下面的代码示例了使用Timer对象来实现一个非常简单的定时器。
const Timer = process.binding('timer_wrap').Timer;
const kOnTimeout = Timer.kOnTimeout | 0;
var mySetTimeout = function (fn, ms) {
var timer = new Timer();
timer.start(ms, 0);
timer[kOnTimeout] = fn;
return timer;
}
var myClearTimeout = function(timer){
if(timer && timer.close) {
timer.close();
}
}
mySetTimeout(function() {
console.log('timeout!');
},1000);
那我们是否就可以用上面实现的mySetTimeout来对每个socket进行超时操作呢
mySetTimeout(function(){socket.close();},2 * 60 * 1000);
可以是可以,但是这样真的好吗?设想我们做的是一个非常棒的产品,每天好几百万上千万的用户,高峰期在2 * 60 * 1000ms这段时间内会产生非常多的新连接,必然会创建非常多的Timer对象,这个开销还真不小!
nodejs在设计之初就非常非常注重性能,所以像上面这种这么简单的方案必然是不能接受的。
实际上在这2分钟之内,nodejs中的timer模块只会创建一个Timer对象,一个Timer对象如何来满足这么多连接的超时处理呢?
timer模块会使用一个链表来保存所有超时时间相同的对象,每个对象中都会存储开始时间_idleStart以及超时时间_idleTimeout。链表中第一个加入的对象一定会比后面加入的对象先超时,当第一个对象超时完成处理后,重新计算下一个对象是否已经到时或者还有多久到时,之前创建的Timer对象便会再次启动并设置新的超时时间,直到当链表上所有的对象都已经完成超时处理,此时便会关闭这个Timer对象。
通过这种巧妙的设计,使得一个Timer对象得到了最大的重用,从而极大的提升了timer模块的性能。这一场景其实在libev中已早有研究 http://pod.tst.eu/http://cvs.schmorp.de/libev/ev.pod#Be_smart_about_timeouts
实现
上面说到timer模块通过c++提供的Timer对象,最终生成setTimeout以及setInterval等函数暴露给用户使用。那Timer对象是如何实现的呢,下面我们就来一探究竟。
一个最底层的timer
熟悉linux网络编程的同学一定听说过epoll吧,
epoll是什么?按照man手册的说法:是为处理大批量句柄而作了改进的poll。当然,这不是2.6内核才有的,它是在2.5.44内核中被引进的(epoll(4) is a new API introduced in Linux kernel 2.5.44),它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
其中有这么一个函数
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
收集在epoll监控的事件中已经发送的事件。参数events是分配好的epoll_event结构体数组,epoll将会把发生的事件赋值到events数组中(events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)。maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时。
当我们监听一个fd上的事件时,可以设置等待事件发生的超时时间。利用这个特性便可以非常简单的实现一个定时器功能。
由于我使用的是mac系统,所以就用kqueue来代替epoll(它们之间非常相似,具体的详细介绍以及使用方法感兴趣的可以自行查阅相关资料)
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/event.h>
#include <sys/time.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <errno.h>
const int MAX_EVENT_COUNT = 5000;
int main() {
struct timeval t_start,t_end;
int fd = -1;//构造一个不会有任何事件发生的fd
int kq = kqueue();
struct kevent changes[1];
EV_SET(&changes[0], fd, EVFILT_READ, EV_ADD, 0, 0, NULL);
int timeout = 3500;
struct kevent events[MAX_EVENT_COUNT];
struct timespec spec;
spec.tv_sec = timeout / 1000;
spec.tv_nsec = (timeout % 1000) * 1000000;
gettimeofday(&t_start, NULL);
kevent(kq, NULL, 0, events, MAX_EVENT_COUNT, &spec);
gettimeofday(&t_end, NULL);
printf("timeout = %d, run time is %ld\n", timeout, t_end.tv_sec*1000+t_end.tv_usec/1000 - (t_start.tv_sec*1000+t_start.tv_usec/1000));
return 0;
}
至此我们便利用kqueue实现了一个非常简单非常底层的定时器。
libuv中的timer
前面讲到,在http server中每一个新的连接并不会真的就去创建一个Timer对象。同样,在nodejs底层的定时器中,并不会每次创建一个Timer对象就在kqueue上注册一个事件等待超时。优化的思路和nodejs中的timer模块很相似,只不过现在不能保证每个定时器的超时时间都一样。
定时器有一个非常显著的特征,超时时间最短的定时器一定最先触发,假设我们有很多的定时任务,每个任务的执行时间都不同。当第一个定时器超时后,便从这些任务中查找出已经到点的任务并执行对应的超时处理,然后再重新计算余下任务中最先执行的时间,并根据这个时间再次开启一个定时器。
对应的算法需求就是每次都需要查找集合中最小的元素,显然二叉堆中的最小堆(父结点的键值总是小于或等于任何一个子节点的键值)是最适合不过的一种数据结构了。由于最小的元素总是处于根节点,我们可以以O(1)时间找到最小值。对于插入操作,在最坏的情况下,新插入的节点需要不断的和它的父节点进行交换,直到它为根节点为止。假设堆的高度为h, 二叉树最多有2^(h+1) - 1 个 节点. 因此新插入一个节点最多需要log(n+1) -1 次比较,其算法复杂度为O(logn)。
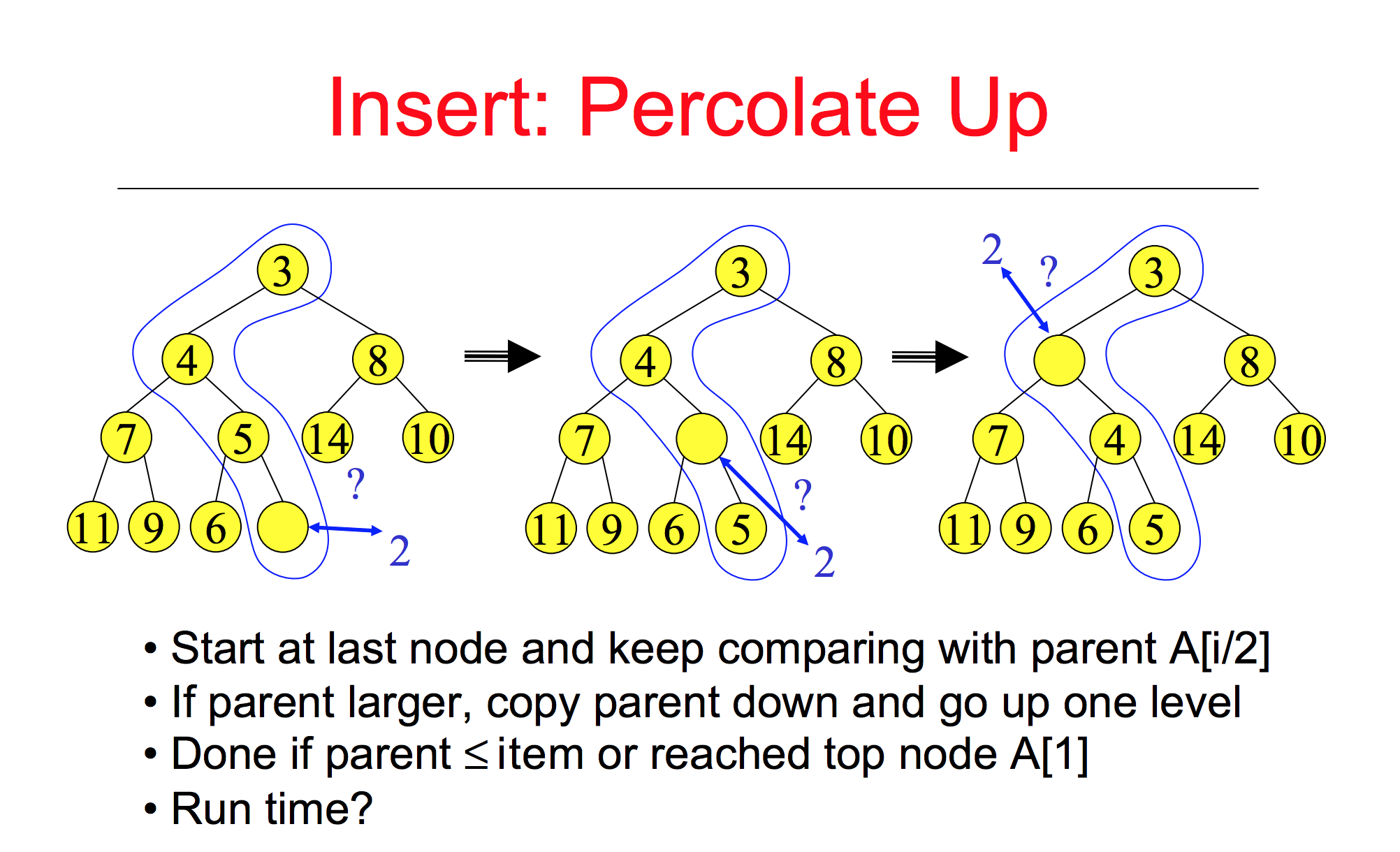
libuv中已经实现了一个最小二叉堆的算法https://github.com/joyent/libuv/blob/master/src/heap-inl.h, 下面我们就用这个算法来实现一个支持设置不同超时时间的定时器。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/event.h>
#include <sys/time.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <errno.h>
//https://github.com/joyent/libuv/blob/master/src/heap-inl.h
#include "heap-inl.h"
#define container_of(ptr, type, member) \
((type *) ((char *) (ptr) - offsetof(type, member)))
const int MAX_EVENT_COUNT = 5000;
typedef struct {
struct heap_node* heap_node[3];
int value;
}node_t;
static int less_than(const struct heap_node* ha, const struct heap_node* hb) {
const node_t* a;
const node_t* b;
a = container_of(ha, const node_t, heap_node);
b = container_of(hb, const node_t, heap_node);
if (a->value < b->value)
return 1;
return 0;
}
int main() {
struct heap *heap_p = malloc(sizeof(node_t));
heap_init(heap_p);
int a[] = {10,9,8,6,7,3,5,4,2};
int len = sizeof(a)/sizeof(int);
for(int i=0;i<len;i++){
node_t *node_p = malloc(sizeof(node_t));
node_p->value = a[i]*1000;
heap_insert(heap_p, (struct heap_node*)node_p->heap_node, less_than);
}
int fd = -1;
int kq = kqueue();
struct kevent changes[1];
EV_SET(&changes[0], fd, EVFILT_READ, EV_ADD, 0, 0, NULL);
struct kevent events[MAX_EVENT_COUNT];
struct timeval t_start,t_end;
while(heap_p->nelts) {
node_t *node_p = container_of(heap_p->min, node_t, heap_node);
struct timespec spec;
spec.tv_sec = node_p->value / 1000;
spec.tv_nsec = (node_p->value % 1000) * 1000000;
gettimeofday(&t_start, NULL);
kevent(kq, NULL, 0, events, MAX_EVENT_COUNT, &spec);
gettimeofday(&t_end, NULL);
printf("timeout = %d, run time is %ld\n", node_p->value, t_end.tv_sec*1000+t_end.tv_usec/1000 - (t_start.tv_sec*1000+t_start.tv_usec/1000));
heap_dequeue(heap_p, less_than);
}
printf("timer is over!\n");
return 0;
}
执行gcc timer.c -o timer && ./timer后输出
timeout = 2000, run time is 2004
timeout = 3000, run time is 3000
timeout = 4000, run time is 4003
timeout = 5000, run time is 5005
timeout = 6000, run time is 6005
timeout = 7000, run time is 7005
timeout = 8000, run time is 8004
timeout = 9000, run time is 9000
timeout = 10000, run time is 10005
timer is over!
可以看到我们设置的9个定时器都预期执行了,除了有5ms以内的偏差。这就是nodejs中最底层的定时器实现了。
nodejs中的timer
我们再回到nodejs中的timer模块,为了不影响到nodejs中的event loop,timer模块专门提供了一些内部的api(timers._unrefActive)给像socket这样的对象使用。
timer内部会维护一个unrefList链表以及一个unrefTimer Timer对象,当有新的超时任务到来时便会添加到unrefList中,超时后便从unrefList中取出任务执行。
在最初的设计中,每次执行_unrefActive添加任务时都会维持着unrefList的顺序,保证超时时间最小的处于前面。这样在定时器超时后便可以以最快的速度处理超时任务并设置下一个定时器,但是在添加任务时最坏的情况下需要遍历unrefList链表中的所有节点。具体实现可参考https://github.com/nodejs/node/blob/5abd4ac079b390467360d671a186a061b5aba736/lib/timers.js
很显然,在web开发中建立连接是最频繁的操作,那么向unrefList链表中添加节点也就非常频繁了,而且最开始设置的定时器其实最后真正会超时的非常少,因为中间涉及到io的正常操作时便会取消定时器。所以问题就变成最耗性能的操作非常频繁,而几乎不花时间的操作却很少被执行到。
针对这种情况,如何解决呢?目前在node社区主要有2种方案。
使用不排序的链表
主要思路就是将对unrefList链表的遍历操作,移到unrefTimeout定时器超时处理中。这样每次查找出已经超时的任务就需要花比较多的时间了O(n),但是插入操作却变得非常简单O(1),而插入节点正是最频繁的操作。
使用二叉堆
原理和libuv中的timer实现一样,添加和查找一个节点都能达到O(log(n))的复杂度(找出最小节点本身很快,但是删除它需要O(log(n))的复杂度),能够在二者之间保持一个很好的平衡。
benchamark
这2种方案都有比较详细benchamark数据, 具体可参考https://github.com/nodejs/node-v0.x-archive/wiki/Optimizing-_unrefActive
小结
在高并发连接到来并且很少有实际的超时事件发生时unrefList使用没有排序的链表来存储超时任务时性能是非常棒的。但是一旦出现很多超时事件都发生的情况下,对超时事件的处理会再次变成一个瓶颈。
而使用二叉堆来存储超时任务时,当有大量超时事件发生时性能会比链表好很多,没有超时事件触发时性能比链表稍差。
可见nodejs在不同的场景中使用的定时器实现也不都一样。当我们自己在实际的开发时,如果需要使用到定时器功能,不妨好好思考下哪种方案更适合业务场景,能够最大的提升timer模块的性能。