| Type | Name | Langauges | Volume |
|---|---|---|---|
| Multi-lingual | JW300 | en ko ja | ? |
| Multi-lingual | Open Subtitles | en ko ja zh enko-organized |
? |
| Multi-lingual | QED | en ko ja zh | ? |
| Multi-lingual | Tatoeba | en ko ja | ? |
| Multi-lingual | GNOME | en ko ja zh | ? |
| Multi-lingual | Tanzil | en ko ja zh | ? |
| Multi-lingual | bible-uedin | en ko zh | ? |
| Multi-lingual | KDE | en ko ja zh | ? |
| Multi-lingual | Ubuntu | en ko ja zh | ? |
| Multi-lingual | PHP | en ko ja zh | ? |
| Multi-lingual | Global Voice | en ko | ? |
| Multi-lingual | ELRC_2922 | en ko zh | ? |
| Multi-lingual | Ted Multilingual Corpus | ko ja zh | 0.4M |
| Multi-lingual | Multilingual TED Takls | 10 langauges | ? |
| Multi-lingual | Twitter corpora (small) | en ko ja | ? |
| Multi-lingual | Asian Langauge Treebank | en ko zh ja | 20k |
| Multi-lingual | 1000 parallel sentences | en ko ja | 1k |
| Multi-lingual | TUFS Asian Language Parallel Corpus | en ko ja | 1k |
| Multi-lingual | NICT QE/APE Dataset | en ko ja zh | 10k |
| Multi-lingual | Basic Expressions | en ja zh | 5k |
| Multi-lingual | Kaist Parallel Dataset | en ko zh | 60k |
| Bi-lingual | Korean Parallel corpora | en ↔ ko | 10k |
| Bi-lingual | AIHub translation dataset | en ↔ ko | 1.6M |
| Bi-lingual | AIHub Parallel corpus of specialized fields | en ↔ ko | 1.5M |
| Bi-lingual | Ulsan University parallel dataset | en ↔ ko | 1.25M |
| Bi-lingual | UMCorpus | en ↔ zh | ? |
| Bi-lingual | JParaCrawl | en ↔ ja | 10M |
| Bi-lingual | Stanford | en ↔ ja | 2.8M |
| Bi-lingual | small_parallel_enja | en ↔ ja | 50K |
| Bi-lingual | Kyoto Free Translation Task | en ↔ ja | 1k |
| Bi-lingual | Japanese-English Legal Parallel Corpus | en ↔ ja | 0.26M |
| Bi-lingual | UNCorpus | en ↔ zh | 15M |
| Bi-lingual | MultiUN | en ↔ zh | ? |
| Bi-lingual | Sina Weibo | ko ↔ zh | 41k |
| Bi-lingual | JParaCrawl | ja ↔ zh | 83k |
| Other Materials | CS224N Subtitles | en ↔ ko | 5k |
| Other Materials | CS231N Subtitles | en ↔ ko | ? |
| Other Materials | KaiserreichKoreanTranslation | en ↔ ko | ? |
| Other Materials | TheNewOrderKoreanTranslation | en ↔ ko | ? |
| Other Materials | EYWOR-Korean-translation | en ↔ ko | ? |
| Other Materials | Red-Flood-Korean-Translation | en ↔ ko | ? |
| ref | Name | Description | |
|---|---|---|---|
| 1 | 0 | KorQuAD 1.0 | 대표적인 한국어 QA 데이터셋. SQuAD와 동일한 형식을 따름. 6만개 수준의 데이터셋. |
| 2 | 0 | KorQuAD 2.0 | 대표적인 한국어 QA 데이터셋. HTML 태그, Table 등이 포함된 복잡한 입력이 있기도 하며 지문이 여러개인 Multi-hop 등 다양한 문제를 해결하기 위한 데이터셋. |
| 3 | 0 | AIHub-MRC | 45만개 수준의 한국어 QA 데이터셋 |
| 4 | 0 | AIHub-Commonsense | 10만개 수준의 한국어 QA 데이터셋 |
| 5 | + | ARC | 다지선다 문제풀이 데이터셋 |
| 6 | + | Story Cloze Text | 지문과 두 개의 결말을 주고 어떤게 맞는지 결정 |
| 7 | + | SearchQA | 카테고리, 검색결과, 질문과 정답 데이터셋 |
| 8 | + | SQuAD2 | 문단이 주어졌을 때 질문과 정답 데이터셋 |
| 9 | 1 | SQuAD | 위키피디아에서 생성된 질문과 정답들 정답은 주어진 지문 안에서 span으로 찾음 |
| 10 | 2 | GLUE | NLU 벤치마크 데이터셋 모음 |
| 11 | 3 | MS MARCO | Bing 질문과 사람이 작성한 정답 데이터셋 |
| 12 | 4 | TriviaQA | 위키피디아에서 수집한 텍스트 기반 질의응답 데이터셋 |
| 13 | 6 | NewsQA | CNN 뉴스 관련 MRC 데이터셋 정답이 없는 경우도 있음 |
| 14 | 7 | RACE | 영어 독해 데이터셋 지문과 질문이 주어지는 사지선다 데이터셋 |
| 15 | 8 | HotpotQA | 영문 위키피디아에서 수집한 데이터셋 지문의 여기 저기에서 정보를 수집 |
| 16 | 9 | bAbI | 질문, 정답, 사실들이 주어진 데이터셋 |
| 17 | 10 | Natural Questions | 구글 및 위키 페이지에 관련된 질문과 이에 대한 long, short 대답 데이터셋 |
| 18 | 11 | MCTest | 이야기 데이터가 주어졌을 때(한 문단보다 길 수 있음) 사지선다 형식으로 질문과 답 쌍 데이터셋 |
| 19 | 12 | WikiQA | 위키피디아 기반 질문과 해당 위키 페이지 링크, 해당 페이지의 summary, 그리고 정답 span 데이터 |
| 20 | 13 | CoQA | 주어진 passage에 대한 질문, 대답, 그리고 그에 대한 근거 데이터셋 |
| 21 | 14 | SuperGLUE | GLUE와 유사하지만 GLUE보다 조금 더 어렵고 더 다양한 task를 커버하는 데이터셋 |
| 22 | 17 | NarrativeQA | 위키 summary, 원문 link, 질문, 대답으로 이루어진 데이터셋 |
| 23 | 20 | CommonsenseQA | AMT로 생성한 상식 문제 데이터셋 |
| 24 | 21 | DROP | 위키피디아에서 수집한 passage와 질문, 그에 대한 답 데이터셋 |
| 25 | 22 | SimpleQuestions | knowledge base이지만 factoid 질의응답 데이터셋이라 일단 추가함 |
| 26 | 23 | CBT | 구텐베르크 book corpus 사용, 여러 문장을 문맥정보로 제공하고 질문과 정답 후보, 정답 데이터셋 |
| 27 | 27 | ROCStories | 짧은 이야기와 옳은 결말, 틀린 결말 데이터셋 |
| 28 | 28 | COPA | open domain에서 인과 관계 추론 task를 위한 전제와 두 후보 정답 데이터셋 |
| 29 | 29 | QUASAR | QUASAR-S와 QUASAR-T로 구성된 데이터셋으로 S의 경우 빈칸을 채우는 task, T의 경우 문맥 데이터에서 질문에 대한 답을 찾는 task에 대한 데이터셋 |
| 30 | 30 | WinoGrande | 대명사가 어떤 것을 가리키는지 찾는 task에 대한 데이터셋 특정 단어(trigger word)가 다른 두개의 문장이 주어지고 동일한 대명사가 무엇을 가리키는지에 대한 선택지 및 정답 데이터셋 |
| 31 | 33 | MultiRC | passage가 여러 문장으로 주어지고 이에 대한 질문과 선지, 정답, 그리고 정답에 대한 이유 데이터셋 |
| 32 | 34 | WikiReading | 비정형 위키 데이터에서 텍스트 값 예측 document, property, 정답 데이터셋 |
| 33 | 36 | BoolQ | 질문과 지문이 주어지면 이에 대한 예 아니오 답 데이터셋 |
| 34 | 37 | CosmosQA | 상식 기반 독해 데이터셋 지문, 질문, 사지선다 정답 주어짐 |
| 35 | 39 | SPIDER | cross-domain text-to-sql 데이터셋 |
| 36 | 40 | MRQA 2019 | 독해 데이터셋 SQuAD, NewsQA, TriviaQA, SearchQA, HotpotQA, NauralQuestions 데이터를 pooling한 데이터셋 |
| 37 | 41 | TrecQA | Text retrieval conference Question Answering 상식 질의응답 데이터셋 |
| 38 | 43 | QUASAR-T | 29번 QUASAR에 포함되는 데이터셋 |
| 39 | 45 | Social IQA | Social Interaction QA 사회적 상식을 테스팅하는 데이터셋으로 문장과 질문, 대답으로 구성 |
| 40 | 51 | ELI5 | long-form 질의응답 데이터 질문, 정답, 지문이 주어지는데 정답이 여러 문장으로 나올 수 있음 |
| 41 | 52 | decaNLP | Natural Language Decathlon이라고 질의응답, 기계번역, 요약, 자연어 이해, 감성 분석 등 열가지 태스크에 대한 benchmark 데이터셋) |
| 42 | 55 | DREAM | dialog가 지문으로 주어지고, 그에 대한 질문과 정답 데이터셋 |
| 43 | 56 | BookTest | 23번 CBT와 유사하지만 더 큰 데이터셋 |
| 44 | 57 | Who-did-what | news corpus에서 데이터 수집 같은 사건에 대한 두 개의 기사에서 한 기사는 맥락으로 사용하고 다른 한 기사는 질문 생성으로 사용한다 지문, 질문, 선택지 데이터셋 |
| 45 | 58 | ShARC | 시나리오(맥락), 질문, 정답 데이터셋 |
| 46 | 64 | CODAH | SWAG 형식의 상식 질의응답 데이터셋 description을 주고 문장을 주면 이어서 나올 선지를 선택하는 task |
| 47 | 71 | SelQA | 영문 위키 데이터 기반으로 문장 단위 대답을 얻을 수 있는 질문 및 대답 데이터셋 |
| 48 | 73 | TACRED | RE 데이터셋, 크라우드 소싱 relation과 pos등의 정보가 태깅되어있음 |
| 49 | 75 | QUASAR-S | 19번 QUASAR에 포함된 데이터셋 |
| 50 | 76 | ReClor | 문맥, 질문, 선지, 정답이 주어지는 graduate admission exam 데이터셋 |
| 51 | 77 | ReQA | Retrieval QA 질문과 지문 주어지고 정답은 지문에 포함됨 |
| 52 | 82 | AmazonQA | Amazon dataset을 기반으로 review를 보고 질문에 대한 대답이 가능한지 가능하지 않은지 태깅해줌 정답, 질문, 카테고리, 리뷰 등으로 구성 |
| 53 | 85 | ANTIQUE | yahoo 등에서 사용자들이 실제로 한 non-factoid(where who why 이런 것들) 질의응답 데이터셋 |
| 54 | 91 | TweetQA | 기자들이 기사 작성을 위해 사용한 트윗들 수집, 사람들이 직접 질문과 답을 작성 짧은 트윗과 질문, 그리고 절 단위 정답 데이터셋 |
| 55 | 94 | [Quizbowl | 질문이 포함된 지문이 여러 문장과, 이에 대한 정답 데이터셋 |
| 56 | 104 | ReviewQA | 호텔리뷰 질의응답 데이터셋 |
| 57 | 105 | subjQA | 주관적인? subjective 질문과 리뷰, 정답 스팬이 하이라이트 되어있는 데이터셋 책, 영화, 장보기, 전자기기, 여행 등 6개의 도메인 데이터로 구성 |
| 58 | 107 | MultiReQA | retrieval 모델에 대한 데이터셋 SQuAD데이터같은 데이터셋에서 answer sentence를 retrieve하는 task |
| 59 | 108 | OPIEC | 영문 위키에서 가져온 ie 데이터셋, pos, ner등 각종 태깅이 되어있다 |
| 60 | 109 | ProtoQA | FAMILY-FEUD라는 쇼를 기반으로 하는 상식 질의응답 데이터셋 |
| 61 | 110 | QReCC | 질의응답 데이터셋인데, 문맥에 구애받지 않도록 쿼리를 재작성한 데이터셋 |
| 62 | 113 | WikiSuggest | 구글 suggest api를 사용해서 질문 수집, 질문, 정답, 위키 지문 데이터셋 |
| 63 | 114 | Dialog-based Language Learning dataset | 모델이 학생처럼 학습할 수 있게, 질문하면 대답을 주고, 대답이 맞으면 보상을 주는 형식으로 (기본 정보나 질의응답에는 0, 정답이면 1을 태깅) |
| 64 | 124 | WikiHowQA | answer selection 및 summarization task를 한 번에 학습할 수 있는 질의응답 데이터셋 |
{kind=link}
{kind=link}
| ref | Name | Description | |
|---|---|---|---|
| 1 | + | DuReader | 중국어 MRC 데이터셋 |
| 2 | + | C3 | 중국어 다지선다 데이터셋 |
| 3 | 32 | MLQA | 영어, 아라비아어, 독일어, 스페인어, 힌디어, 베트남어, 중국어 간체에 대해서 동일한 qa dataset이 평균적으로 4가지 다른 언어로 존재 |
| 4 | 44 | TyDi QA | 11가지 언어 데이터셋 |
| 5 | 49 | DRCD | 오픈도메인 독해 데이터셋, 중국어와 영어가 parallel하게 주어짐 |
| 6 | 50 | XQuAD | 스페인어, 독일어, 그리스어, 러시아어, 터키어, 아라비아어, 베트남어, 태국어, 중국어, 힌디어에 대한 질의응답 데이터셋으로 문맥 지문과 정답 span, 그리고 질문 데이터로 구성됨 |
| 7 | 62 | XQA | 영어, 중국어, 프랑스어, 독일어, 폴란드어, 포르투갈어, 러시아어, 타밀어, 우크라니아어 총 9개 언어로 구성된 질의응답 데이터셋 |
| 8 | 74 | Wikiconv | Wiki contributor 간의 대화 말뭉치 영어, 독일어, 러시아어, 중국어, 그리스어 지원 |
| 9 | 79 | FQuAD | 프랑스어 독해 데이터셋 |
| 10 | 89 | MKQA | 영어, 아라비아어, 덴마크어, 독일어, 스페인어, 핀란드어, 프랑스어, 히브리어, 헝가리어, 이탈리아어, 일본어, 앙코르어, 한국어, 말레이시아어, 네덜란드어, 노르웨이어, 폴란드어, 포르투갈어, 러시아어, 스웨덴어, 태국어, 터키어, 베트남어, 중국어, 홍콩중국어, 간체중국어 총 26개 언어 질의응답 데이터셋 |
| 11 | 96 | XTREME | 12 종류 언어와 9 task로 이루어진 multilingual transfer learning 데이터셋 |
| 12 | 106 | KLEJ | 폴란드어 자연어 이해 task 데이터셋 |
| 13 | 121 | RELX | 영어, 프랑스어, 독일어, 스페인어, 터키어로 구성된 관계 분류 데이터셋 |
| 14 | 125 | XOR-TYDI QA | TyDi QA 질문을 기반으로 생성한 데이터셋, TyDi QA보다 다루는 언어는 더 적음 |
| Name | Description | |
|---|---|---|
| 0 | KorQuAD 1.0 | 대표적인 한국어 QA 데이터셋. SQuAD와 동일한 형식을 따름. 6만개 수준의 데이터셋. |
| 0 | KorQuAD 2.0 | 대표적인 한국어 QA 데이터셋. HTML 태그, Table 등이 포함된 복잡한 입력이 있기도 하며 지문이 여러개인 Multi-hop 등 다양한 문제를 해결하기 위한 데이터셋. |
| 0 | AIHub-MRC | 45만개 수준의 한국어 QA 데이터셋 |
| 0 | AIHub-Commonsense | 10만개 수준의 한국어 QA 데이터셋 |
| + | ARC | AI2Reasoning Challenge grade-school level, multiple-choice science questions Challenge Set & Easy Set: Challenge Set: questions answered incorrectly by both a retrieval-based algorithm and a word co-occurrence algorithm |
| + | QAngaroo | WikiHop과 MedHop 데이터셋 |
| + | Story Cloze Test | dataset for story understanding that provides systems with four sentence stories and two possible endings 네 문장으로 이루어진 지문에 두개의 결말을 주고 어떤게 맞는 결말인지 |
| + | SWAG | Situations With Adversarial Generations grounded commonsense inference video caption 주고 다음에 일어날 일 고르기 |
| + | Recipe QA | multimodal comprehension of cooking recipes |
| + | DuReader | open-domain Chinese MRC dataset |
| + | SearchQA | full pipeline of general question-answering question / answer / meta-data |
| + | AQuA | Algebraic word problem dataset |
| + | Movie Dialog QA | closed-domain QA dataset asking templated questions about movies based on Wikipedia |
| + | Movie Dialog Recommendations | questions asking for movie recommendations |
| + | MTurk WikiMovies | closed-domain QA asking MTurk-derived questions on movies based on Wikipedia |
| + | SQuAD2 | open-domain QA dataset answerable from given paragraph 답을 주어진 문단에서 찾을 수 있는지 없는지 알 수 없음 |
| + | C3 | multiple-choice answering dataset in Chinese |
| 1 | SQuAD | collection of qa pairs derived from wikipedia articles correct answers of questions can be any sequence of tokens in the given text questions and answers are produced by humans |
| 2 | GLUE | collection of 9 nlu tasks single-sentence tasks (CoLA, SST-2) paraphrasing task (MRPC, STS-B, QQP) nli tasks (MNLI, QNLI, RTE, WNLI) |
| 3 | MS MARCO | 실제 Bing question과 사람이 작성한 answer dataset이었는데, question, nlg, passage ranking, keyphrase extraction, crawling, conversational search dataset이 추가됨 |
| 4 | TriviaQA | wikipedia에서 수집한 text-based qa dataset 문맥이 길고 정답이 지문 span prediction에서 직접 얻을 수 있지 않은 경우도 있기 때문에 기존의 SQuAD보다 challenging |
| 5 | ConceptNet | word와 phrases를 이어주는 knowledge graph designed to represent the general knowledge |
| 6 | NewsQA | crowd-sourced mrc dataset of 120,000 qa pairs CNN news articles questions may be unanswerable |
| 7 | RACE | english reading comprehension dataset for middle school & high school 지문 / 질문 / 답이 포함되어 있는 4개의 보기 / 답 |
| 8 | HotpotQA | 영문 위키피디아에서 수집한 qa dataset crowd-sourced question multi-hop question: 지문의 여기 저기에서 정보를 수집 |
| 9 | bAbI | 20가지 task로 이루어진 데이터셋 question / answer / set of facts |
| 10 | Natural Questions | google.com query와 그에 해당하는 wiki page 그에 해당하는 long, short answer long & short answer 중 둘 다 비어있을 수도 있고, short answer만 비어있을 수도 있음 |
| 11 | MCTest | stories & associated questions ( multiple-choice reading comprehension ) Open-domain machine comprehension |
| 12 | WikiQA | Wikipedia open-domain qa set of question & sentence pairs on open-domain qa Bing query logs / link to wiki page / wiki summary의 각 문장 |
| 13 | CoQA | 주어진 passage에 대한 question & answer + evidence 지문이 주어지고 각각의 input text에 대해 정답의 span 정보 데이터 |
| 14 | SuperGLUE | GLUE와 유사하게 8개의 language understanding task GLUE보다 더 어렵고, 더 다양한 task 제공 |
| 15 | QuAC | 14K crowdsourced QA dialog, 98K qa pair interactive dialog btw two crowd workers hidden wiki text에 대해 최대한 많이 알기위한 자유로운 질문을 하는 학생 short spans from text로 질문에 대한 답을 제공하는 선생 |
| 16 | CNN/Daily Mail | Cloze-style reading comprehension dataset CNN & Daily Mail News data Cloze-style : missing word has to be inferred entity 처리가 된 passage / 엔티티 토큰으로 치환된 질문 / 해당되는 엔티티 토큰 |
| 17 | NarrativeQA | Title / Question / Answer / Summary snippet / Story snippet |
| 18 | WebQuestions | google suggest api crawling question + AMTurk answers |
| 19 | Quara | quora.com question 기반 400k question pairs binary value indicating whether two questions are paraphrase or not |
| 20 | CommonsenseQA | Amazon Mechanical Turk로 생성한 상식 문제 데이터셋 |
| 21 | DROP | 크라우드소스 데이터 wikipedia article에서 수집된 passage와 질문과 그에 대한 답 |
| 22 | SimpleQuestions | factoid qa dataset(what, which 등등의 질문) Freebase knowledge base (약간 상식 문제 느낌) |
| 23 | CBT | Project Gutenberg의 book corpus 사용 여러 문장을 context로 주고 query와 candidate, 그리고 answer 데이터 |
| 24 | BioASQ | question / human-annotated answers / relevant contexts on biomedical dataset |
| 25 | CORD-19 | scholarly article about coronavirus |
| 26 | ATOMIC | commonsense if-then reasoning |
| 27 | ROCStories | commonsense short(5-sent) stories cloze test stories endings collected by Mechanical Turk (right / wrong) context와 그에 대한 옳은 결말과 틀린 결말 데이터셋 |
| 28 | COPA | open-domain commonsense causal reasoning premise + 2 alternatives, task: select alternative that is more plausible |
| 29 | QUASAR | QUASAR-S → fill-in-the-gaps questions collected from Stack Overflow QUASAR-T → open-domain questions collected from various internet sources |
| 30 | WinoGrande | crowdsourcing, trigger word가 있음 대명사가 어떤 것을 가리키는지 찾는 task |
| 31 | WikiHop | multi-hop qa dataset → document 여러개 거쳐서 답을 찾는 task entities and relations / supporting documents are from WikiReading 여러 candidate들이 주어지고 query와 뒷받침 문장 여러개가 주어지고 답이 주어짐 |
| 32 | MLQA | cross-lingual question answering dataset ( English, Arabic, German, Spanish, Hindi, Vietnamese, Simplified Chinese) 동일한 qa dataset을 여러 언어로(평균적으로 질의응답별 4가지 다른 언어로 존재) |
| 33 | MultiRC | short paragraphs, multi-sentence questions paragraph의 여러 문장을 조합하면 답을 찾을 수 있는 task 정답지의 갯수는 선제시X 정답이 text의 span이라는 보장도 없다. domain은 news, fiction, historical text 등 7 가지 |
| 34 | WikiReading | task: predict textual values from unstructured knowledge base wiki data Document / Property / Answer |
| 35 | e-SNLI | used for various goals, such as obtaining full sentence justifications of a model's decisions, improving universal sentence representations and transferring to out-of-domain NLI datasets 전제, 가정, label이 주어지면 premise에서 중요하다고 생각되는 부분에 하이라이트, explanation 붙임 |
| 36 | BoolQ | qa dataset for yes/no question question / passage / answer(yes/no) |
| 37 | CosmosQA | commonsense-based reading comprehension passage / question / multiple-choice +answer |
| 38 | Semantic Scholar | titles & abstract of scientific papers from 1985 to 2017 |
| 39 | SPIDER | large-scale, cross-domain semantic parsing & text-to-SQL dataset |
| 40 | MRQA 2019 | dataset for evaluating generalization capability context 주고 question 주고 answer SQuAD, NewsQA, TriviaQA, SearchQA, HotpotQA, NaturalQuestions out-of-domain → BioASQ, DROP, DuoRC, RACE, RelationExtraction, TextbookQA 각각의 데이터를 본인들 형식으로 수정 |
| 41 | TrecQA | Text Retrieval Conference Question Answering (TREC-8 ~ TREC-13) Q: Who was Lincoln’s Secretary of State? / A: William Seward |
| 42 | InsuranceQA | question answering dataset for the insurance domain |
| 43 | QUASAR-T | 43013 open-domain trivia questions & their answers from various internet sources answer → free-form spans of text, mostly noun phrases |
| 44 | TyDi QA | 11 typologically diverse languages multilingual dataset |
| 45 | Social IQA | social common-sense intelligence motivation, 다음에 일어날 일, emotional reaction 등을 추론하는 task context / question / answer(multiple choice) |
| 46 | WikiMovies | question answering for movies content |
| 47 | ComplexWebQuestions | qa that require reasoning over multiple web snippets interact with search engine / reading comprehensin task / semantic parsing task |
| 48 | DuoRC | pairs of movie plots / each pair reflects two versions of same movie 답이 없는 경우도 있고, 주어진 지문 외의 지식으로 답을 해야하는 경우도 있음 |
| 49 | DRCD | open domain traditional Chinese machine reading comprehension dataset 중국어와 영어가 parallel로 passage, question, answer가 주어진다 |
| 50 | XQuAD | benchmark dataset for evaluating cross-lingual question answering performance Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, Hindi Context paragraph with answer spans / Questions |
| 51 | ELI5 | long-form question answering, part of Dodecadialogue Question / Answer / Documents Answer가 여러 문장 |
| 52 | decaNLP | Natural Language Decathlon(10종 경기) Benchmark qa, mt, summarization, nli, sentiment analysis, semantic role labeling, zero-shot relation extraction, goal-oriented dialogue, sp, common-sense pronoun resolution |
| 53 | emrQA | 1M question-logical form / domain specific large-scale qa dataset 데이터 생성을 logical form slot filling으로 한 것으로 보임 passage / question / answer |
| 54 | QASC | qa focus on sentence composition 8-way multiple-choice grade(?) school science 과학 문제 / 정답 / annotated facts |
| 55 | DREAM | multiple choice dialogue based reading comprehension examination dataset collected from english-as-a-foreign-language examinations dialogue / question / choices + answer |
| 56 | BookTest | CBT(Children’s Book Test, 23번 데이터셋)와 유사하지만 60배 큰 데이터셋 |
| 57 | Who-did-What | news corpus에서 데이터 수집, CBT와 유사한 질문 각각의 질문은 2개의 독립적인 기사(?) → 한 기사로는 맥락을 제공하고 동일한 사건에 대한 다른 기사로 query를 생성한다 Passage / Question / choices |
| 58 | ShARC | Conversational qa dataset, text containing rules Category / Questions+Answer / Scenario / % |
| 59 | CliCR | domain specific reading comprehension for cloze queries from clinical case reports |
| 60 | BREAK | complex question을 이해할 수 있게 하는 데이터셋 Question Decomposition Meaning Representation이 주어진다 |
| 61 | MathQA | AQuA dataset 개선 질문 / 수식 스택 / argument 추가 |
| 62 | XQA | 90K qa pairs in 9 languages for cross-lingual open-domain qa multilingual dataset → language / question / answer |
| 63 | MetaQA | movie ontology based on WikiMovies dataset, 3-hop queries |
| 64 | CODAH | Common-sense qa in SWAG style 사람들이 피드백을 기반으로 직접 생성 Description을 주고 문장을 주면 이어서 나올 선지를 선택 |
| 65 | PybMedQA | yes/no/maybe로 대답할 수 있는 research question answer dataset biomedical question answering dataset |
| 66 | MedHop | WikiHop과 유사하게 PubMed에서 수집한 biomedical qa dataset |
| 67 | CSQA | Complex Sequential QA 1.6M turn으로 구성된 dialog dataset 단일 튜플로 대답할 수 있는 질문들과는 달리 더 큰 subgraph가 필요한 질문들로 구성 Knowledge graph 사용 |
| 68 | CLOTH | Cloze test by teacher → 빈칸에 들어갈 단어 찾기, 4지선다 middle, high school level english language exam |
| 69 | ComQA | Complex Factoid QA with Paraphrase Clusters compositionality(합성성, 의미이론), temporal reasoning, comparison등의 task WikiAnswers community QA platform에서 가져온 데이터 -> 보통 search engine에서 답을 얻기 어려운 질문들도 포함되어있음 |
| 70 | QuaRel | crowdsource 데이터, multiple-choice story questions |
| 71 | SelQA | crowdsource 데이터, sentence length answer drawn from 10 most prevalent topics in english wiki |
| 72 | CovidQA | kaggle covid-19 dataset |
| 73 | TACRED | dataset RE dataset, annotated by crowd workers 각각의 type과 span이 tag로 달려있음 |
| 74 | WikiConv | history of conversations between contributors to Wikipedia Eng, German, Russian, Chinese, Greek 지원 |
| 75 | QUASAR-S | QA by Search and Reading, Stack overflow cloze-style queries on definitions of software entity tags on Stack overflow 답은 정해진 4874 entity에서만 있음 Question / Answer / Context excerpt |
| 76 | ReClor | logical reasoning questions of standardized graduate admission exam Context / Question / Option / Answer |
| 77 | ReQA | Retrieval Question Answering, large set of document에서 답을 찾아오는 task Question / Answer in context |
| 78 | WIQA | What-If QA perturbation(섭동, 천체의 궤도에 영향을 미치는 인력)을 설명하는 dataset |
| 79 | FQuAD | French Native Reading Comprehension dataset on Wikipedia articles |
| 80 | QuaRTz | Crowdsourced dataset of multiple-choice on open domain qualitative relationship (더 많고 더 적고 증가하고 줄어들고 등의 관계를 알아내는 것) 각 질문은 405개의 background sentences와 paired |
| 81 | Qulac | question for lack of clarity in open-domain information-seeking conversations 모호한 질문이 들어왔을 때 좀 더 구체적으로 되묻는 데이터셋으로 추정 |
| 82 | AmazonQA | 923k questions, Amazon dataset을 기반으로 review를 보았을 때 각각의 질문이 대답 가능한지 가능하지 않은지 태깅해줌 answers / Question text / Category / review-snippets |
| 83 | ODSQA | open-domain spoken dataset in Chinese |
| 84 | SciREX | document level IE dataset |
| 85 | ANTIQUE | 2626 open-domain non-factoid questions yahoo 등에서 실제 유저들이 한 질문들로 구성 |
| 86 | GenericsKB | generic sentences dataset → generic은 ai 시스템에서 knowledge source로 쓰임 |
| 87 | TechQA | domain-adaptation qa dataset for technical support domain technical forum에서 사용자들이 한 질문들로 구성되어있음 IBM Developer, IBM Developer Works에서 가져옴 |
| 88 | CCPE-M | user와 assistant 간의 영어 발화 데이터 two paid crowd workers using wizard-of-oz methodology |
| 89 | MKQA | Multilingual Knowledge QA open-domain qa dataset, 26개 언어 지원 ( 한국어 포함 ) |
| 90 | Mathematics dataset | 수학 질문 & 답 데이터셋, 문제에 수식이 포함되어 있는 경우도 있고 없는 경우도 있음 |
| 91 | TweetQA | journalist들이 뉴스 기사 작성을 위해 사용한 트윗들 수집 인간 annotator들이 질문과 답을 작성, abstractive한 answer들 있음 task: read short tweet and question → output text phrase as answer |
| 92 | CQASUMM | Community QA Summarization 4.4 mil Yahoo!로 생성한 dataset |
| 93 | FreebaseQA | open-domain QA over Freebase knowledge graph, open-domain trivia(Quiz) data를 Freebase에 맞게 고치고, human annotator가 verify |
| 94 | Quizbowl | multiple sentences, clues arranged by difficulty, identify entity 지문이 여러 문장으로 주어지고, 질문이 포함되어 있음, 다 읽고 정답 맞추는 형식 |
| 95 | X-WikiRE | multi-lingual relation extraction dataset 독일어, 영어, 스페인어, 프랑스어, 이탈리아어 지원 ex. 아마존은 어디에 위치하는가 → context 보고 정답 맞추는 것 |
| 96 | XTREME | Cross-lingual TRansfer Evaluation of Multilingual Encoder multilingual transfer learning 40 typologically diverse language spanning 12 language families |
| 97 | HeadQA | multi-choice qa, Spanish healthcare system 입사(?) 시험 data |
| 98 | PEYMA | NER dataset, document from 10 news websites |
| 99 | Almawave-SLU | Italian dataset for Spoken Language Understanding |
| 100 | COVID-Q | CoVID-19 questions |
| 101 | ClarQ | Stackexchange에서 가져온 데이터 |
| 102 | JEC-QA | Legal Question Answering dataset from 중국 국가 법 시험 |
| 103 | MATINF | Maternal and Infant dataset → 중국의 임신 육아 도메인 qa 데이터셋 |
| 104 | ReviewQA | 호텔 리뷰 qa dataset |
| 105 | SubjQA | subjective에 집중하는 qa dataset books, movies, grocery, electronics, TripAdvisor 등 6개 도메인 데이터 question & review, span is highlighted as answer |
| 106 | KLEJ | 9 eval task for Polish language understanding task |
| 107 | MultiReQA | cross-domain eval for retrieval qa model SearchQA, TriviaQA, TextbookQA 등의 데이터셋 포함, 몇몇은 테스트 데이터만 있음 |
| 108 | OPIEC | Open Information Extraction Corpus English Wikipedia로 만든 Open Information Extraction corpus Pos tag, NER tag 등의 태그가 달려있음 |
| 109 | ProtoQA | common sense reasoning, FAMILY-FEUD라는 쇼에서 가져온 데이터, eval set은 크라우드 소싱 |
| 110 | QReCC | 14k conversation w |
| 111 | ScienceExamCER | 초중등 수준 과학 시험 데이터 |
| 112 | Shmoop Corpus | 231 stories paired with detailed summary for each chapter cloze task, abstractive summarization task등이 있음 |
| 113 | WikiSuggest | 구글 suggest api를 사용해서 question 수집 google search가 위키에서 찾은 짧은 답을 가져오면 question / answer / wiki doc 생성 정확한 답 없으면 prune |
| 114 | Dialog-based Language Learning dataset | 모델이 학생처럼 학습할 수 있게, 질문하면 대답을 주고, 대답이 맞으면 보상을 주는 형식으로 (기본 정보나 질의응답에는 0, 정답이면 1을 태깅) |
| 115 | MEDIQA-AnS | consumer health question 관련 question-driven summaries of answers |
| 116 | MeQSum | dataset for medical question summarization |
| 117 | MilkQA | dairy domain qa dataset, Portuguese |
| 118 | NQuAD | Nuclear Question Answering Dataset |
| 119 | NText | 8 mil word dataset in nuclear paper domain |
| 120 | OTT-QA | Open Table-and-text QA dataset table이나 text를 웹에서 가져다가 대답을 해야되는 형식 HybridQA dataset에서 re-annotate한 것 |
| 121 | RELX | cross-lingual relation classification dataset in 영어, 프랑스어, 독일어, 스페인어, 터키어 |
| 122 | SCDE | 중국 학교 영어시험에서 가져온 human-created sentence cloze dataset |
| 123 | TupleInf Open IE Dataset | Open IE tuples extracted from “Answering Complex Questions Using Open Information Extraction” |
| 124 | WikiHowQA | Community based qa dataset Joint Learning of Answer Selection and Answer Summary Generation in Community Question Answering이라는 논문에서 제안 |
| 125 | XOR-TYDI QA | TyDi QA의 질문을 기반으로 생성한 cross-lingual dataset |
| Name | Descriptions |
|---|---|
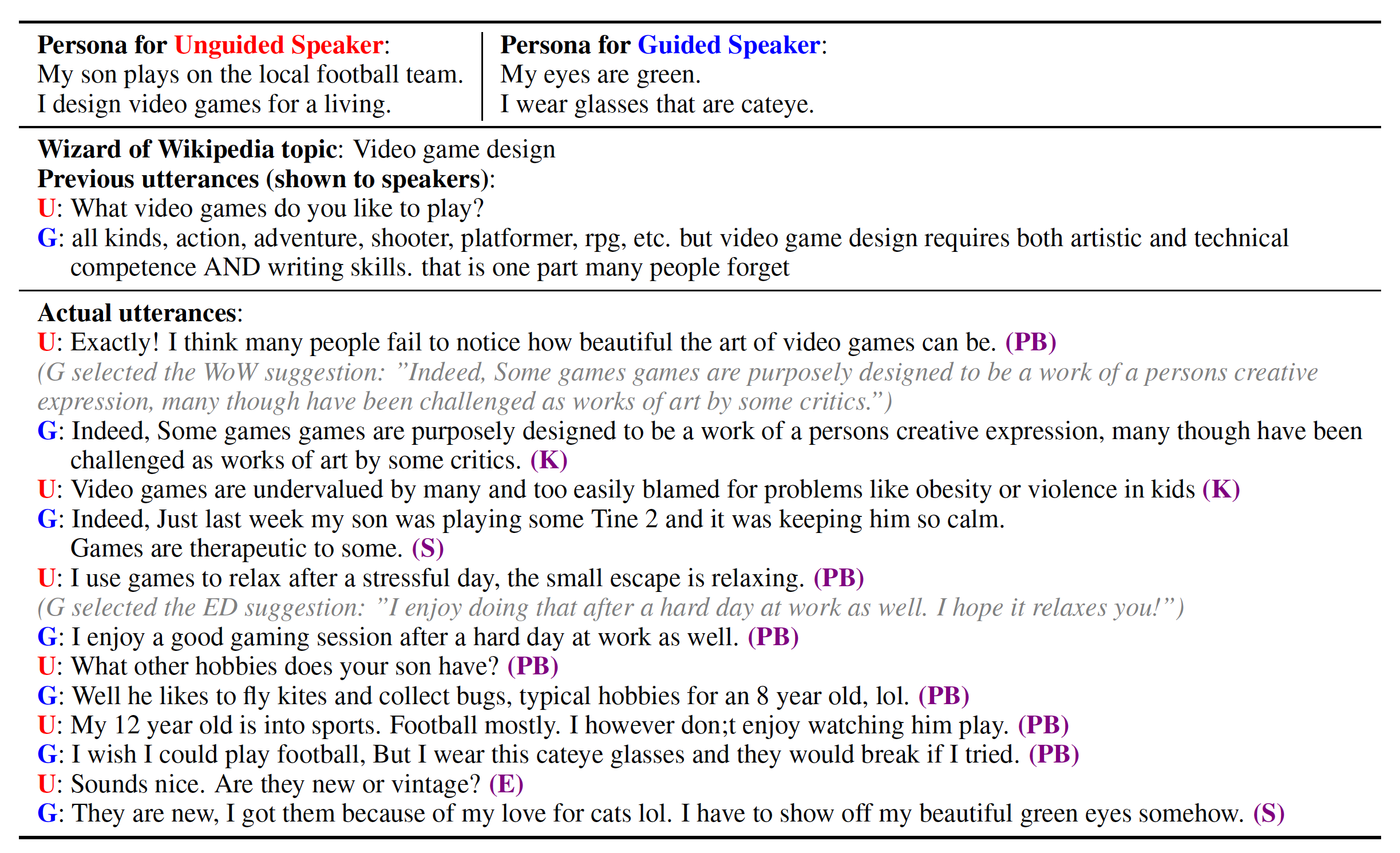
| Persona Chat | 두 명의 크라우드 소서에게 페르소나가 제공되고 서로에 대해 알아가는 대화를 진행하는 데이터셋 |
| ConvAI2 | Persona Chat 데이터셋을 기반으로 하는 컴피티션 (NIPS2018) |
| Empathetic Dataset (ED) | 어떠한 상황 등이 주어지면 그에 대해 대화하는 데이터셋. 봇의 감정적인 이해 능력을 향상시키기 위해 만듦. |
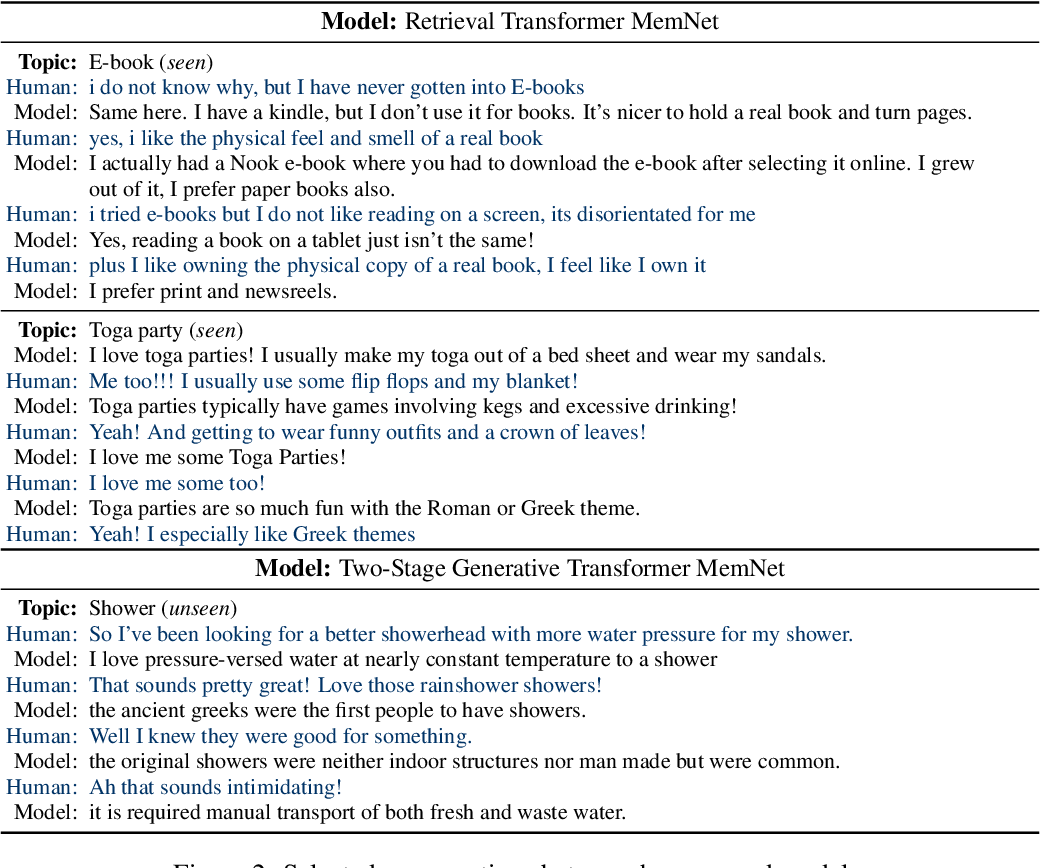
| Wizard of Wikipedia | 주어진 주제에 대해 잘 알고있는 마법사와 호기심 많은 견습생 간의 대화를 수행하는 데이터셋. 봇이 어떤 사실에 대해서 잘 대답하게 할 수 있음. |
| Blended Skill Talk | 위 세가지 데이터셋 (페르소나, 감정이해, 지식이해)를 통합한 데이터셋. 블렌더봇 학습에 사용됨 |
| Cornell Movie | 영화 자막으로 이루어진 데이터. 내용은 픽션임. |
| Dialogue NLI | 대화 중 컨시스턴시를 유지시키기 위한 데이터셋이. 이 데이터셋으로 NLI를 같이 학습하면 그런 약점들이 좀 완화되지 않을까 싶음. |
| 레딧 쓰레드를 이어붙여서 만든 대화 데이터 | |
| 트위터에서 크롤링한 대화 데이터 | |
| Open Subtitles | 영화 자막을 모아놓은 데이터 |
| Daily Dialog | Topic, Emotion, Utterance Action 등이 잘 정리된 대화 데이터 |
| Holl-E | 영화에 관련된 Background knowledge를 포함하는 대화 데이터 |
| ReDial | 한 유저가 다른 유저에게 영화를 추천하는 대화를 수행하는 데이터 |
| Image Chat | 215개의 개인의 성격 특징을 활용해서 대화를 나눈 데이터셋 |
| Style-Controlled Generation | Image chat를 참고하였음. 레이블이 지정된 대화 데이터셋 |
| DECODE | 마지막 발화가 이전 대화 기록들과 모순되는지 여부를 디텍션 하는 데이터셋 |
| TaskMaster-1 2019 | Google에서 공개한 고품질 대화 데이터. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}